《线程》专题
-
Nashorn以线程安全的方式
下面我分享了我的代码,我试图使用线程安全的Nashorn作为脚本引擎来评估简单的数学公式。公式将类似于“a*b/2”,其中a 我需要知道这种方法是否有助于使Nashorn线程在这个用例中安全。我在Attila的回答中读到,我们可以在线程之间共享脚本引擎对象,因为它们是线程安全的。 对于bindings和eval,因为我们正在为每次执行evaluate创建新线程,每个线程都有自己的bindings对
-
引擎线程安全吗?[重复]
任何人都可以澄清NashScript引擎是否线程安全?如果不是线程安全的,如何处理多个脚本?
-
执行器服务-线程超时
这种方法的Java博士说 如果需要,最多等待给定的时间完成计算,然后检索其结果(如果可用)。 参数: 超时等待的最长时间 unit超时参数的时间单位 根据我的理解,我们对强加了一个超时,我们提交给,这样,我的将在指定的时间(超时)过去后中断 但是根据下面的代码,似乎超过了超时时间(2秒),我真的很难理解这一点。谁能给我指一下正确的路吗?
-
SSLContext和SSLSocketFactory createSocket线程安全吗?
SSLHandler类在多个线程中使用,如下所示: 因此,为每个新线程创建一个SSLHandler。为了避免这种情况,我考虑使用单例模式重构SSLHandler:
-
Java线程堆栈内存占用
当我研究线程及其占用的内存(线程堆栈)时,我决定做一个简单的负载测试,看看线程的数量如何影响我的计算机上的RAM。 所以,在测试中,我使用了Tomcat,在设置中。xml将最小和最大web容器线程池设置为200。在那之后,我在将pool设置为2000时也做了同样的操作。我很震惊,因为内存占用没有差异(通过Windows任务管理器进行检查),而且几乎是一样的。所以我认为这些线程可能必须处于运行状态,
-
java计时器任务多线程
我使用Timer和TimerTask为聊天应用程序长轮询新消息。我想研究两种“稍微”不同的可能性: 1:计时器声明为局部变量 *问题:每次调用该方法时,我都会看到创建了一个新线程,[Timer-1]、[Timer-2]等等。。在Eclipse调试窗口中,即使在getLastMessages(..)之后,它们似乎都在运行完成运行并向客户端返回值。如果计时器实际使用线程,并且在几次事务之后,服务器最终
-
扩展线程时吞下异常
-
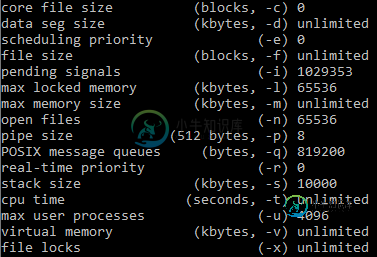 java.lang.OutOfMemoryError与不和谐JDA 350线程
java.lang.OutOfMemoryError与不和谐JDA 350线程所以我会尽力解释我的问题。目前,我正在进行一项规模相当可观的计划。然而,正如350所说,我从未使用过这么多线程。它目前给了我一个内存不足的错误,但我已经尝试了多种选择: 添加-Xss参数 添加我可以在这个网站上找到的其他参数 此外,我还尝试编辑堆栈大小和用户限制 下面列出了内存溢出问题的错误。 当我发现无论我做什么,线程堆栈大小总是看起来是1024。 我目前从具有以下规格的VPS运行此. jar文
-
线程C11无法解释原因
我在Ubuntu13.04桌面上运行这个非常简单的程序,但是如果我注释掉sleep_for一行,它会在从main打印cout后挂起。有人能解释为什么吗?据我所知,main是一个线程,t是另一个线程,在本例中,互斥体管理共享cout对象的同步。
-
MySQL的Select Last_Insert_ID的线程安全
我正在尝试制作一些SQL 不过,我觉得这在多用户环境中并不安全。那里有一个狭窄的窗口,另一个用户可以在那里插入一些东西,并导致一个错误的返回值。如何安全地插入并获取插入记录的密钥?
-
Spring批处理-多线程环境
我想编写一个spring boot批处理应用程序,其中我有一个充满事件的数据库表。我想做的是有一个多线程的spring boot批处理应用程序,它将以这种方式工作: 我想有5个线程运行,每个线程将保留一个偏移量来跟踪它读取的事件,以便没有其他线程再次读取相同的事件。我想怎么做: 所以我希望能够在数据库表中为每个线程保留偏移量。有没有办法让Spring Boot环境以这种方式工作?
-
单例、线程安全和互斥
我今天在思考这个问题。下面是我正在思考的一个场景。 singletonClassObj。添加两个数字(10,20); SingletonClassObj.addTwoNumbers(100,200); 现在我的问题是什么,假设Thread-1首先执行并调用方法。那么有没有可能在整个函数被线程-1执行之前,线程-2调用函数并更改x和y的值?例如,线程-1以10和20的形式发送数据,在将求和分配给变量
-
Apache Flink,线程比Kafka分区多
数据流很简单 Kafka- “一些逻辑”是这里的瓶颈,所以我想使用更多的线程/任务来提高吞吐量,而不是增加kafka分区(目前为3个)。输入和输出主题之间的顺序在这里并不重要。 使用Apache Storm可以轻松完成。我可以为一些逻辑增加螺栓的并行度。如何使用Flink做到这一点?更普遍的问题是,是否有任何简单的方法可以在Flink的不同阶段使用不同的并行度?
-
多线程中的同步对象
现在我的问题是:关键字对这种情况有用吗?
-
使用HTTP-Kit驻留的线程
我有几个线程在运行,每个线程都对HTTP工具包进行阻塞调用。我的代码一直在工作,但最近大约30分钟后就冻结了。我所有的线程都卡在以下一点上: