《并查集》专题
-
 试图在网站中查找ID并出现“chrome不可访问”错误
试图在网站中查找ID并出现“chrome不可访问”错误这是我的密码。 由于某种原因,两个Chrome浏览器正在打开,我得到了这个错误: 如何打开一个浏览器,引用该浏览器,并打印“主内容”ID中的所有数据?或者,表ID='dags'?
-
查找并选择一个单元格基于URL在谷歌工作表
我使用谷歌表单制作了一个简单的基于表单的化学品数据库。该表如下所示:https://docs.google.com/spreadsheets/d/e/2PACX-1vR0-AMEKNM3ZbDq67OIKWnc7E3KP8kfOsnr0Bjg2OSjpevLLjniknGXfIiiyZvbwE9bz3EfbOpO46ef/pubhtml?gid=292509613 有许多行和列。用户可以使用如下u
-
捕获异常“PlayerInteractEvent”并检查位置是否存在|| Minecraft插件Spigt Bukkit
我有一个问题。我有一个我正在尝试使用的我的世界服务器插件,它不存在。 我收到以下错误: 无法将事件PlayerInteractEvent传递给XXX org.bukkit.event.EventException:org.bukit.plugin.java.JavaPluginLoader$1.execute(JavaPluginLoader.java:319)~[spigot-1.16.jar:
-
二叉搜索树查找最大节点并将其删除(泛型类)
正如标题所说,我目前正试图找到BST的最大节点,我想删除它。我有方法来查找最大节点和删除节点准备从我的算法书,但我不知道如何在主方法中使用它们。我有一个方法,可以通过输入一个数字插入节点,例如8,这将打印一个级别有序的树:4, 2, 6, 1, 3, 5, 7其中4是根。我希望能够找到最后一个节点并删除它。到目前为止,我有这些方法: 我的主要方法是这样的: 我希望能够自由插入任何节点,并且树仍然能
-
检查筛选器找到任何项目并获取第一个项目
-
 java - 多线程并发查询百万数据的内存占用问题?
java - 多线程并发查询百万数据的内存占用问题?开启十个线程,每个线程都会去查询500W的数据。 单独一个线程,堆内存占用500M。 十个线程,堆内存占用最高也不过1400MB,为什么会这样呢?这些内存占用居然不会叠加的吗?
-
在JPQL查询中的集合上检查NULL?
问题内容: 我正在写一个JPQL查询,它基于 Categories 集合进行查询。我的类别可以为空,因此我正在使用:categories = NULL进行检查。 当类别为NULL时,以上方法可以正常工作。但是,当类别超过一个值时,我得到了错误 java.sql.SQLException:操作数应包含1列 与hibernate有关的痕迹是 (?,?)或(?,?)中的category6_.catego
-
查找重复项但排除集的查询
我有一个表,有以下列 我想要一个查询(下面查询的修改版本),如果上面的表中给定的work_date和员工ID(GROUP BYEMP_ID和WORK_DATE)超过1行,它将返回一行。所以我写了如下查询: 例如: 如果我通过1/1/2013 for:p_WorkDate,查询应返回如下: 基本上,我试图找出EMP\u ID和WORK\u DATE是否有超过1行,但还有一个额外的要求,即元素列包含什
-
Cloud FireStore:如何在我的集合查询中获取文档引用并将其映射为JSON值?
假设我有一个评论集。每个comment对象都有一个指向发帖用户的“doc ref”。我需要一个查询,它将返回一个注释列表,包括每个单个用户引用的值,因此我的查询返回一个很好的格式的Json注释对象。
-
数据并行与任务并行
本文向大家介绍数据并行与任务并行,包括了数据并行与任务并行的使用技巧和注意事项,需要的朋友参考一下 数据并行 数据并行意味着在每个多个计算核心上并发执行同一任务。 让我们举个例子,对大小为N的数组的内容求和。对于单核系统,一个线程将简单地对元素[0]求和。。。[N-1]。但是,对于双核系统,在核0上运行的线程A可以对元素[0]求和。。。[N / 2-1],而在核心1上运行的线程B可以求和元素[N
-
Java 8并行流并发分组
问题内容: 假设我有一堂课 我试图按班上所有领域分组。如何在JAVA 8中使用并行流来转换 映射的键是类中每个字段的值。JAVA 8以下示例将单个字段分组,如何将一个类的所有字段归为一个Map? 问题答案: 您可以使用的静态工厂方法来实现: 正如Holger在评论中所建议的那样,以下方法可能比上述方法更可取: 它使用的重载方法的行为与我上面建议的语句相同。
-
并发,并行,多线程编程
本章讲解 Rust 中,并发,并行,多线程编程的相关知识。
-
查
本节将演示下查询数据的一些常用方法。 通过命令行 use testDB # 查询最新的三条数据 SELECT * FROM weather ORDER BY time DESC LIMIT 3 通过Http接口 curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=testDB" --data-urlenco
-
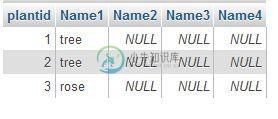 MySQL-查询将具有相同ID的行合并,并保留该ID的所有条目但作为一条记录
MySQL-查询将具有相同ID的行合并,并保留该ID的所有条目但作为一条记录问题内容: 我一直在在mysql数据库中的一个表上工作,该表被本地保存在wamp服务器上,我正在wamp中使用phpmyadmin区域来运行查询。我正在尝试获取数据来执行以下操作: 任何人都可以帮我建立一张带有许多工厂记录的表格。植物可以具有多个名称,该表将其显示为不同的记录。该表称为new_plantsname 持续超过3000条记录 我想要的是将具有相同plantid的记录组合在一起,并在不同
-
Hibernate合并
问题内容: 我正在测试hibernate并将此查询提供给 我在命令行中得到这些查询: 我使用的是“合并不保存”,所以为什么hibernate正在更新我的对象,所以不应该更新。对吗 怎么了 问题答案: 我将尝试使用一个更具体的示例进行解释。假设您有以下情况: 尝试重新附加分离的对象时发生异常,userA。 为了解决上述问题,使用了merge(),如下所示: