《云原生》专题
-
关于备份和还原
一个安全和可靠的服务器是与定期运行备份有密切的关系,因为由攻击、硬体故障、人为错误、电力中断等引致的错误有可能随时发生。 Navicat 为用户提供一个内置备份和还原工具用于备份或还原 MySQL、PostgreSQL、SQLite 和 MariaDB 数据库对象。对于 Oracle、SQL Server 和 MongoDB,用户可以使用以下的功能。 Oracle 数据泵 SQL Server 备
-
关于备份和还原
一个安全和可靠的服务器是与定期运行备份有密切的关系,因为由攻击、硬体故障、人为错误、电力中断等引致的错误有可能随时发生。 Navicat 为用户提供一个内置备份和还原工具用于备份或还原 MySQL、PostgreSQL、SQLite 和 MariaDB 数据库对象。对于 Oracle、SQL Server 和 MongoDB,用户可以使用以下的功能。 Oracle 数据泵 SQL Server 备
-
关于备份和还原
一个安全和可靠的服务器是与定期运行备份有密切的关系,因为由攻击、硬体故障、人为错误、电力中断等引致的错误有可能随时发生。 Navicat 为用户提供一个内置备份和还原工具用于备份或还原 MySQL、PostgreSQL、SQLite 和 MariaDB 数据库对象。对于 Oracle、SQL Server 和 MongoDB,用户可以使用以下的功能。 Oracle 数据泵 SQL Server 备
-
Python encoding 原理及应用
初学 Python 时可能不适应需要手动注释文件编码的写法,根据 PEP 263 所定义, 必须在 Python 文件的前两行,按照下面的写法注明文件的编码: # coding=<encoding name> 或者: # -*- coding: <encoding name> -*- 或者: # vim: set fileencoding=<encoding name> : 如果不定义文件的
-
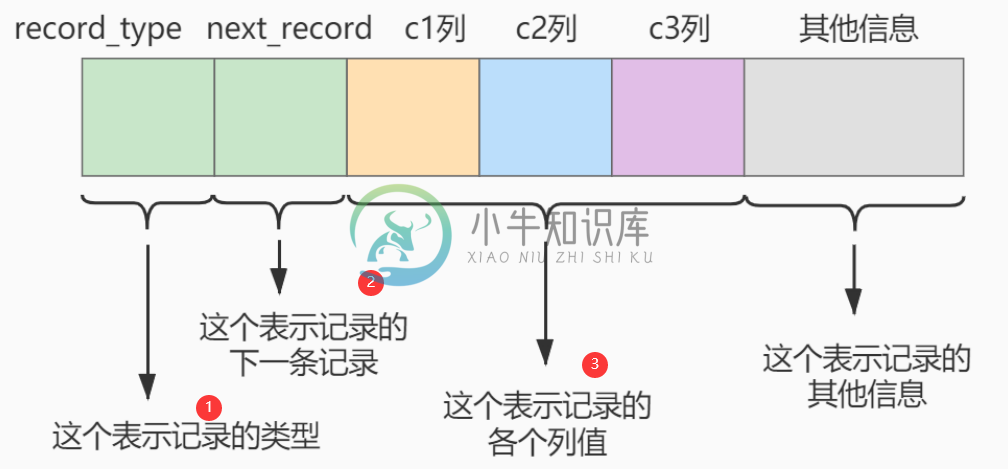 MySQL索引内部原理
MySQL索引内部原理主要内容:一、索引概述,二、设计索引,引入目录项,三、常见索引概念,1. 聚簇索引,2. 二级索引(辅助索引、非聚簇索引),3.联合索引,4.MyISAM中的索引,5.MyISAM与InnoDB对比,四、B-Tree和B+Tree对比一、索引概述 索引即一本书的目录,我们通过书的目录能够快速的查到对应文章的页码。数据库的索引也差不多,通过在某些字段建立索引,可以快速的查找某些特定的数据,避免全表搜索。 因为数据库表的数据在磁盘文件中,会将对应数据读取到内存中进行检索,全表搜索会带来更多的IO操作
-
设计模式与原则
主要内容:1.GRASP:通用职责分配软件模式(共9种),2.SOLID:设计原则(共5种),3.GOF:设计模式(共23种),4.其他必要设计原则GRASP: 通用职责分配软件模式(共9种) SOLID:设计原则(共5种) GOF:设计模式(共23种) 其他必要设计原则 1.GRASP:通用职责分配软件模式(共9种) 告诉我们怎样设计问题空间中的类与分配它们的行为职责,以及明确类之间的相互关系等 Infomation Expert(信息专家) Creator(创造者) Low coupling
-
 SpringBoot自动装配原理
SpringBoot自动装配原理主要内容:1.SpringBoot自动装配原理,2.BeanFactory和ApplicationContext的区别,3.Spring容器是什么1.SpringBoot自动装配原理 BFPP:BeanFactoryPostProcessor BPP:BeanPostProcessor BDRPP:BeanDefinitionRegistryPostProsessor 1.当启动SpringBoot程序时候,创建SpringApplication的对象,在对象的构造方法中进行对某些参数的初始化工
-
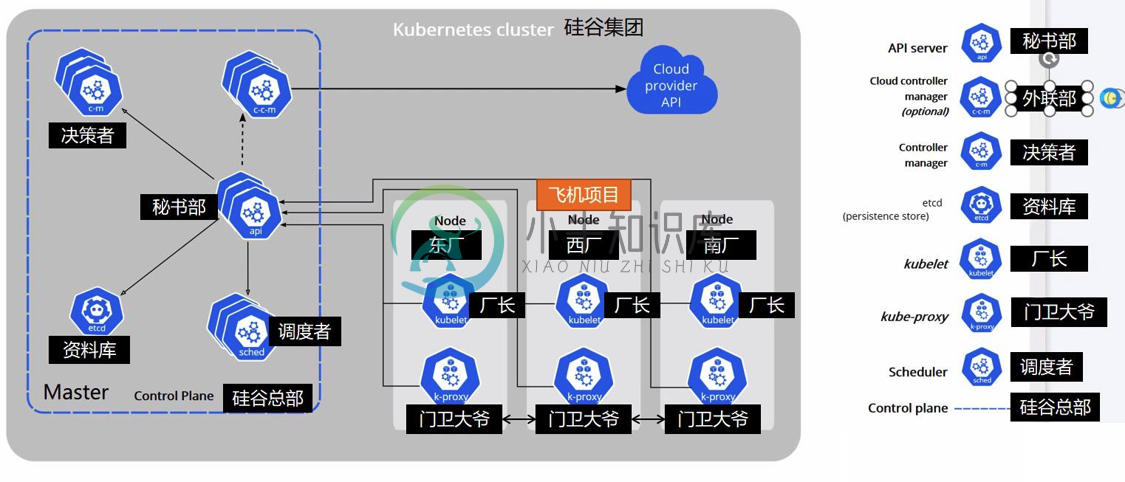 Kubernetes 核心资源原理
Kubernetes 核心资源原理主要内容:1.kubernetes 架构,2.从创建 deployment 开始,3.Pod,3.容器编排,4.水平扩缩容,5.更新/回滚,6.滚动更新,7.kubernetes 中的网络,8.微服务—service,9.kubernetes 中的服务发现与网络调用kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。 1.kubernetes 架构 从宏观上来看 kubernetes 的整体架构,包
-
 @EnableWebMvc + WebMvcConfigurer接口的原理
@EnableWebMvc + WebMvcConfigurer接口的原理主要内容:1.回顾,2.@EnableWebMvc + WebMvcConfigurer接口的使用原理,3.总结1.回顾 根据之前的文章, 之前自定义的组件放入了容器中, 但是DispatcherServlet会使用自定义的组件而放弃了默认组件, 导致很多功能都失效了。 所以 + 就是解决这个问题的 2.@EnableWebMvc + WebMvcConfigurer接口的使用原理 会给容器导入9大组件, 而且留了个入口可以定制化 添加链接描述SpringBoot 源码分析 (@Enablexx
-
Java atomic原子操作类
主要内容:1 atomic的概述,2 原子更新单个变量,2.1 基本原子类,2.2 带版本号的原子类,3 原子更新数组,3.1 重要属性,3.2 重要方法,4 原子更新字段属性,5 原子类的加强,6 atomic的总结基于JDK1.8详细介绍了JUC下面的atomic子包中的大部分原子类的底层源码实现,比如AtomicInteger、AtomicIntegerArray、AtomicStampedReference等原子类源码。最后还介绍了JDK1.8对原子类的增强,比如LongAdder和Lo
-
 中原银行AI面试
中原银行AI面试#中原银行AI面试##中原银行面试# 8道AI面试题!!刚开始还以为是4道面试题呢 1.为什么选择银行这个行业?你关于未来三到五年的职业规划是什么? 2.如果遇见意见不和或者不太好相处的成员或小组,你会怎么做?结果是什么? 3.对你自己所在行业的了解?你是如何获取行业动态的?近一年行业内令你最印象深刻的一件事是什么?为什么令你印象深刻? 4.你在实习/项目中遇到的最困难的事情是什么?面对困难,你是
-
 OPPO校招笔试原题
OPPO校招笔试原题你的牛牛已潜入OPPO校招组内部 距离OPPO开启春招已经一周啦,想必已经投递完简历了吧 那么接下来就是笔试环节啦👇 OPPO笔试难不难,考什么题呢 不必担心,牛牛有通关小技巧——校招原题 是的,没错,牛牛拿到了OPPO官方授权的23届秋招原题噢!!! 研发岗的友友,刷起来! 直通链接:OPPO笔试原题 #OPPO##春招##笔试##校招#
-
 CDN的原理是什么?
CDN的原理是什么?CDN的原理是什么?这是一道前端面试非常高频的面试题,但是很多同学在面试时候只能说出个大概,老规矩,点赞收藏支持一下,给我一分钟,理想哥教大家该怎么满分回答这个问题 如果我是求职者,我会这么回答: 目前的互联网应用中都包含大量的静态内容,如果不做任何处理,所有的请求都指向源站服务器的话,不仅会耗费大量的带宽,还会拖累页面加载速度,影响用户体验。 CDN服务的出现可以解决上述问题。CDN的本质仍然是
-
无法连接到谷歌云SQL从谷歌计算引擎与云SQL代理
我正在尝试使用云SQL代理将GCE实例连接到云SQL实例(第二代)。当我ssh到GCE实例时 我得到 我已阅读 上的文档https://cloud.google.com/sql/docs/compute-engine-access#gce-连接代理和 https://cloud.google.com/sql/docs/sql-proxy 两个实例都在同一个项目中,并且云SQL API在GCE实例(
-
使用云端硬盘API在Google云端硬盘中创建空电子表格
问题内容: 我想在Google云端硬盘中创建一个空的Google表格(仅使用元数据创建)。当我提到Google SpreadSheet API 文档时,它说要使用DocumentsList API,但已弃用,而是要求我使用Google Drive API。在云端硬盘API文档中,我找不到创建空工作表的任何方法。有人知道如何执行此操作吗? 问题答案: 您可以使用做这个驱动器的API被设置MIME类型