《云原生》专题
-
 13.0 Zookeeper Leader 选举原理
13.0 Zookeeper Leader 选举原理zookeeper 的 leader 选举存在两个阶段,一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。在分析选举原理前,先介绍几个重要的参数。 服务器 ID(myid):编号越大在选举算法中权重越大 事务 ID(zxid):值越大说明数据越新,权重越大 逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
-
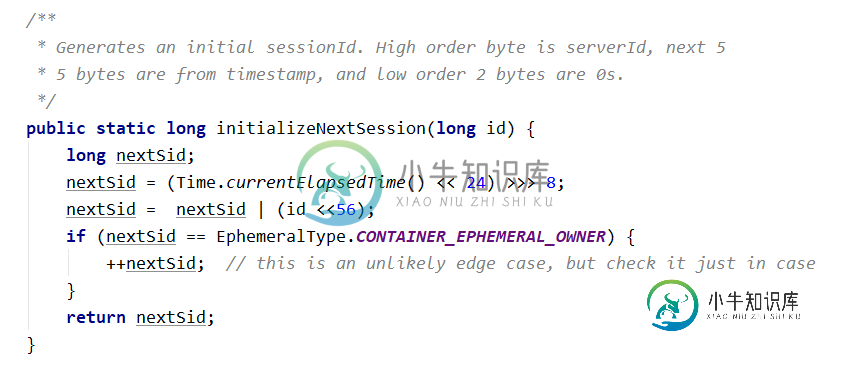 6.0 Zookeeper session 基本原理
6.0 Zookeeper session 基本原理客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就是 session 会话。 从第一次连接建立开始,客户端开始会话的生命周期,客户端向服务端的ping包请求,每个会话都可以设置一个超时时间。 Session 的创建 sessionID: 会话ID,用来唯一标识一个会话,每次客户端创建会话的时候,zookeeper 都会为其分配一个全局
-
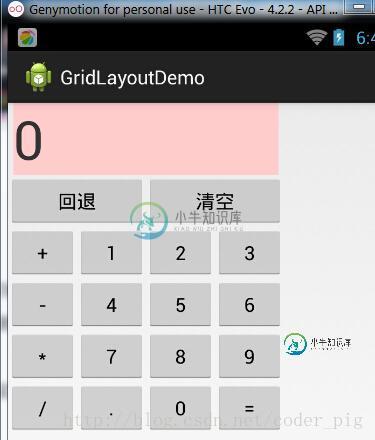 1.7 界面原型设计
1.7 界面原型设计主要内容:本节引言:,Mockplus原型工具的使用:,Android自带DroidDraw工具设计Android界面:,本节小结:本节引言: 引用锤子科技视觉设计总监——罗子雄在重庆TEDx活动上说的一小段话: 每当我们看到一些美妙的设计的时候,很多人心里面会有一种冲动,这种冲动会让你们想去创造一些 新的东西,创造一些美妙的事物。 我们常说用户体验用户体验,用户使用你的软件,第一个会接触的是什么?没错,图形化界面(GUI),简称UI,对于用户而言,最直观,给用户留下第一印像的是往往是程序的界面
-
mysql还原外键错误
我用phpmyadmin导出了我的数据库,其中包括禁用外键和执行到单个事务中,如果存在则删除表,但是当我想导入文件mysql时会抛出一个错误: 第35行错误1215(HY000):无法添加外键约束 谢谢你。
-
OpenJFX Maven原型不存在?
我试图按照官方文档创建一个JavaFXMaven项目(带有maven的IntelliJ章节,非模块化项目)。我将archtype artififact id替换为:,但当我尝试使用archtype创建项目时,仍然会出现以下错误: 无法执行目标org.apache.maven.plugins:maven-arch etype-plugin:3.1.1:生成(default-cli)在项目独立-pom
-
Nuget无法还原Microsoft.Net.Comilers 1.0.0
我正在尝试使用Nuget Package Manager在VS 2017中安装/重新存储。在输出中,它显示恢复已完成。然而,当我检查<code>包</code>文件夹时,我看不到<code>Microsoft.Net。编译器文件夹。因此我犯了错误 严重性代码描述项目文件行禁止显示状态错误此项目引用了此计算机上缺少的NuGet包。使用NuGet Package Restore下载它们。有关详细信息,
-
angular2Spring靴交叉原点cors
我的SimpleCorsFilter如下所示: 机智的邮递员它工作正常: 邮递员得到请求 restlet.com/blog/2016/09/27/how-to-fix-cors-problems/ 并调查了StackOverflow上发布的几个类似问题。
-
OpenShift原点:多主安装
我对OpenShift有点陌生,我已经安装了一个主节点和多个节点(现在已删除此设置)。 现在我需要更高的可靠性,所以我现在准备用三个主机和两个节点来启动我的主机。 我有一个dns、一个dhcp和一个etcd2集群,并使用主机的特定条目运行,例如: < li>openshift-router(外部和内部访问,将作为LB与HAproxy一起使用) < li>openshift-etcd1 < li>o
-
原因:java.lang.IllegalStateException:包未安装?
问题内容: 我的logcat中出现这种错误。尽管出现此错误,但我的项目运行正常。所以我只想澄清有关此错误的这些内容: 问题答案: 我认为当您已经安装了以前的版本并从eclipse运行应用程序时会发生这种情况?如果您在从Eclipse重新运行之前卸载了该应用程序,则不会发生这种情况。另外,这不会造成任何问题。
-
1.9 Raw Queries - 原始查询
由于常常使用简单的方式来执行原始/已经准备好的SQL查询,因此可以使用 sequelize.query 方法. 默认情况下,函数将返回两个参数 - 一个结果数组,以及一个包含元数据(例如受影响的行数等)的对象. 请注意,由于这是一个原始查询,所以元数据都是具体的方言. 某些方言返回元数据 "within" 结果对象(作为数组上的属性). 但是,将永远返回两个参数,但对于MSSQL和MySQL,它将
-
Swarm模式工作原理
本章节将从一下几个方面介绍Docker Engine Swarm模式下的工作原理: 节点工作原理 Service工作原理 安全(PKI) Task的状体啊
-
1.2.4.4 原始数据同步
1.1.1. 一、推送方式 哈勃数据通过kafka实时推送,用户通过订阅kafka数据可以满足更多使用场景,既可以满足离线统计需求,又可以支持实时分析 1.1.2. 二、工作流程 业务方申请一个kafka topic(用于数据推送与订阅 ,如没有私有kafka集群,可向运维申请公共kafka集群的topic) 业务方告知已申请的kafka broker信息、topic名称、推送数据的产品id。申请
-
3.2.11 Android热修复原理
一、概述 最新github上开源了很多热补丁动态修复框架,大致有: https://github.com/dodola/HotFix https://github.com/jasonross/Nuwa https://github.com/bunnyblue/DroidFix 上述三个框架呢,根据其描述,原理都来自:安卓App热补丁动态修复技术介绍,以及Android dex分包方案,所以这俩篇务
-
数据库系统原理
一、事务 概念 ACID AUTOCOMMIT 二、并发一致性问题 丢失修改 读脏数据 不可重复读 幻影读 三、封锁 封锁粒度 封锁类型 封锁协议 MySQL 隐式与显示锁定 四、隔离级别 未提交读(READ UNCOMMITTED) 提交读(READ COMMITTED) 可重复读(REPEATABLE READ) 可串行化(SERIALIZABLE) 五、多版本并发控制 基本思想 版本号 Un
-
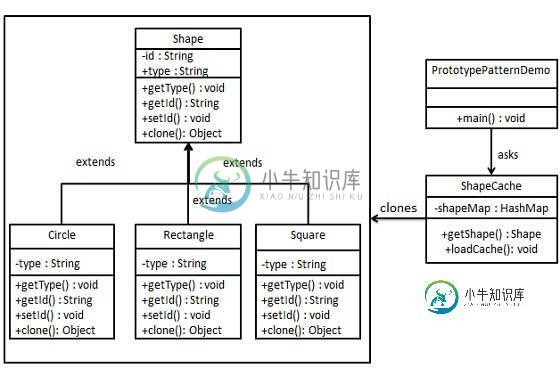 详解JAVA 原型模式
详解JAVA 原型模式本文向大家介绍详解JAVA 原型模式,包括了详解JAVA 原型模式的使用技巧和注意事项,需要的朋友参考一下 原型模式 原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一