《嵌入》专题
-
嵌入Tomcat-7以仅在https中运行
我想运行只使用HTTPS(8443)的嵌入式tomcat。我根本不想使用8080端口。有关于的想法吗? 谢谢
-
如何wirte JPQL选择嵌入ID的MAX?
我使用的是Eclipselink(JPA)+GlassFish V3.1.2+NetBeans 7.1.2 我有一个带有复合主键的表:
-
使用Cassandra CQL收集嵌入式对象
我正在尝试使用CQL将我的域模型放入卡桑德拉中。假设我有USER_FAVOURITES张桌子。每个收藏夹都有 ID 作为主键。我想按顺序存储最多 10 个多个字段的记录的列表,field_name、field_location等。 对这样的表进行建模是个好主意吗? 并且对象将由匹配索引的列表项构成(例如 我总是在一起查询收藏夹。我可能想添加和项目到某个位置,开始,结束或中间。 这是一个好的做法吗?
-
JOLT-在嵌套数组中加入数组
我正在努力实现以下转变。然而,我的解决方案在最终数组中添加了不需要的空值。 转换需要为所有元素在array中移位名称。我创建了3个案例来说明这个问题。 编辑:< code >根数组将始终至少有1个元素。 当前的JOLT规范工作正常,除了是空数组的情况。它生成值,我试图指定一个空字符串(或任何硬编码的字符串值,如)
-
在Spring Boot嵌入式Tomcat中阅读context.xml
在将非spring应用程序转换为Spring Boot时,您希望使用现有上下文。嵌入tomcat中的xml文件。 使用Spring Boot 1.5.1和Tomcat 8.5.11 TomcatEmbeddedServletContainerFactory配置 检查数据库连接的方法, 那么如何在Spring Boot中加载现有的context.xml。
-
将现有WAR添加到嵌入式tomcat
我已经搜索了这个问题,但我没有找到任何关于这个案例的东西。我发现了很多“如何将Spring Boot WAR部署到Tomcat”,但是没有关于用Spring Boot包装现有的Tomcat WAR的内容。 我正在尝试用Spring Boot“包装器”包装一个现有的WAR,这样就不必重新配置现有的代码库。这个解决方案不起作用,因为它依赖于在绝对位置可用的WAR,而我们正试图将“应用程序”WAR打包在
-
嵌入式轻量级(de)压缩算法
null 解压缩算法的重要指标是数据的大小加上算法的大小(因为它们将驻留在相同的有限内存中)。 可用于解压的RAM很少;可以将单个字形的数据解压缩到RAM中,但不能更多。 为了使事情变得更加困难,算法必须在32位微控制器(ARM Cortex-M core)上非常快,因为字形在被绘制到显示器上时需要解压缩。每八位元组十个或二十个机器循环是可以的,一百个肯定太多了。 为了使事情变得更容易,完整的数据
-
将嵌套类导入名称空间-C++
-
查找并使用已嵌入的字体?
该PDF文件已经包含一个名为“Lato(embedded)”的嵌入式字体,编码:ANSI。 如何创建一个PDFFont对象,使我和可以使用它来绘制额外的段落?
-
XWPF文档中缺少嵌入的图片
我有一个问题'XWPF文档'。程序的一部分获取docx文件,并将其中的所有内容复制到一个输出docx文件中。包括文字、表格、图片和公式。我在这方面有一个很好的结果,但是最近我有一个错误:一张图片没有复制到结果中。这是源代码,这是结果。结果你可以看到“3.1.6.2”部分的哪些图像被成功复制,但是不在“3.1.6.1”。 我是这样做的: 这里的关键是: 我从'运行'得到嵌入的图片。在坏的文件中,我有
-
Spring boot嵌入式MongoDb数据预填充
我已经使用flapdoodle作为SpringBoot的嵌入式mongo。这工作很好,但我需要手动将数据放入其中。 对于mongo db的Junit测试,我使用nosqlunit。这与Fongo(假蒙哥)配合得非常好。它支持从json文件读取数据,并在启动期间用数据预填充数据库。但这只适用于junit,因为这是一个junit扩展。 我正在寻找的是上述两者的混合,一个嵌入式mongo,它不仅与JUn
-
如何在嵌入式Jetty上配置strlog
我将从Groovy脚本中启动Jetty Web服务器。Jetty的默认日志记录是stderlog。现在我想配置这个日志记录,但文档中只提到了在使用start时如何进行配置。jar方法启动Jetty。 我如何配置,更具体地说,配置旋转日志文件,与StdErrLog嵌入式码头?
-
嵌入式防波堤,泽西2,焊接
(我在命中RESTendpoint时有)。 如何正确设置焊接(最好是编程方式)?
-
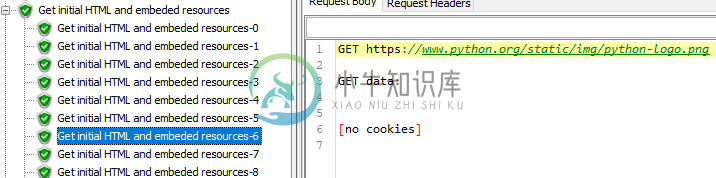 JMeter嵌入式资源名称不正确
JMeter嵌入式资源名称不正确我正在使用HTTP采样器下载嵌入式资源。下面是来自Python.org的示例。我希望嵌入的资源的名称与实际的请求相匹配。但它们的名称与父示例相同。可能是HTTPS的产物吗?我使用的是JMeter5.3。
-
在Chart.js段中嵌入唯一标识符?
我想通过允许用户双击一个切片来向下钻取来使我的饼图交互式。我相信这样做的方法是在画布上创建一个onClick处理程序,并使用来确定单击了哪个切片。 不过,调用返回的段数据可能不明确。这是返回数据的示例: 在这些字段中,只有< code>value 、< code>fillColor 、< code>highlightColor和< code>label是由我提供的,它们都不一定是唯一的。我可以确保