《jmeter》专题
-
如何在jmeter中生成仪表板报告?
问题内容: 我在Fedora上运行jmeter2.12。 生成仪表盘报告的步骤是什么? 问题答案: 脚步: 1.从侦听器中添加“摘要报告”,“简单数据编写器”。 2.将位置设置为生成的csv 3.从“ D:\ apache-jmeter-3.0 \ bin \”打开reportgenerator.properties,从中复制所有内容 4.从同一bin文件夹中打开user.properties 5
-
如何在Jmeter Webdriver采样器中使用chromeoption和desirecapabilities?
问题内容: 我正在将Jmeter webdriver采样器与chrome浏览器一起使用。我需要在jmeter中使用chromeoption和期望的功能。我该如何编码以使用这些选项。 我要使用的示例代码可以是这样。 有人可以帮忙吗? 问题答案: 查看ChromeDriverConfig.java ,您当前无法使用WebDriver Sampler对其进行控制,因此这些选项位于: 修补源代码,并根据需
-
通过JMeter regexp解析HTML
问题内容: 我在JMeter中使用正则表达式遇到了一些麻烦。我有这种形式的HTML 我需要获取JMeter 中and 的值作为变量。 问题答案: 请改用XPath Extractor 。 如果 必须 使用正则表达式,只需搜索正则表达式标签解析即可。
-
使用JMeter运行Selenium脚本
问题内容: 我已经准备好具有功能流程的Selenium自动化脚本,现在我想将这些脚本与JMeter集成以进行负载测试。 那可能吗? 如果是这样,如何将两者融合? 我的首要目标是使用硒运行自动化脚本,而不是在jmeter中运行这些脚本以进行负载或性能测试。 问题答案: JUnit请求采样器 如果您想重用已经自动化的(Java)Selenium场景,而不是为WebDriver Sampler重写JS脚
-
 jmeter如何自动生成测试报告
jmeter如何自动生成测试报告本文向大家介绍jmeter如何自动生成测试报告,包括了jmeter如何自动生成测试报告的使用技巧和注意事项,需要的朋友参考一下 1、准备.jmx脚本文件 2、在脚本文件路径下执行cmd命令: 参数解析: ● -n: 非GUI模式执行JMeter ● -t: 执行测试文件所在的位置 ● -l: 指定生成测试结果的保存文件,.jtl文件格式 ● -e: 测试结束后,生成测试报告 ●
-
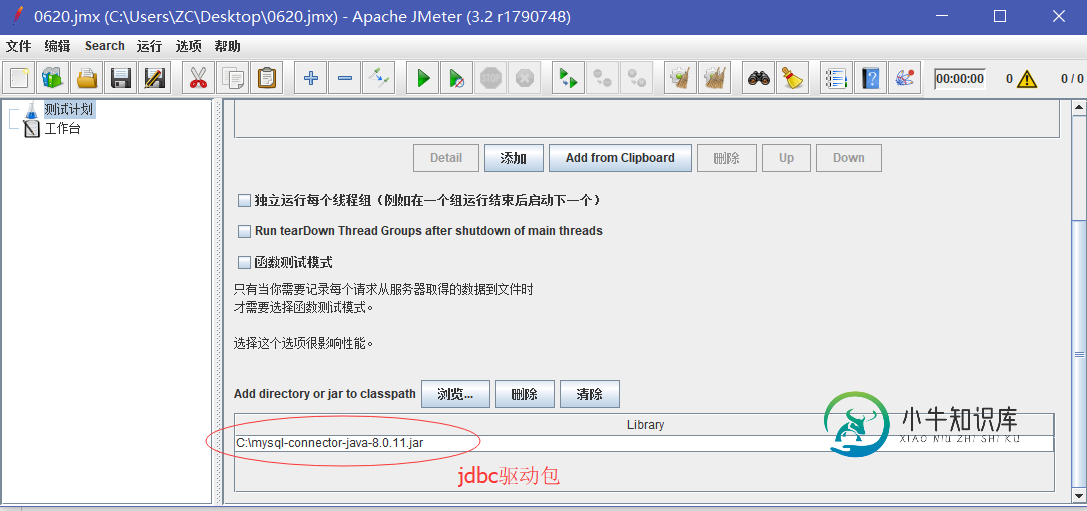 Jmeter连接Mysql数据库实现过程详解
Jmeter连接Mysql数据库实现过程详解本文向大家介绍Jmeter连接Mysql数据库实现过程详解,包括了Jmeter连接Mysql数据库实现过程详解的使用技巧和注意事项,需要的朋友参考一下 昨天把Mysql装好了,这个躺在草稿中很久的文章也可以出炉了。 首先需要准备个Mysql jdbc驱动包,尽量保证其版本和你的数据库版本一致,至少不低于数据库版本,否则可能有问题。去官网扒一个下来吧:https://dev.mysql.com/do
-
 Jmeter参数化获取序列数据实现过程
Jmeter参数化获取序列数据实现过程本文向大家介绍Jmeter参数化获取序列数据实现过程,包括了Jmeter参数化获取序列数据实现过程的使用技巧和注意事项,需要的朋友参考一下 一、序列数据是什么 很简单,就是利用参数化能产生顺序值,比如 1,2,3,4,5,6 或者约定格式 001,002,003,004等。 二、jmeter 产生序列数据 2.1 利用函数助手对话框实现 在jmeter菜单处点击 工具 -- 函数助手对话框 --
-
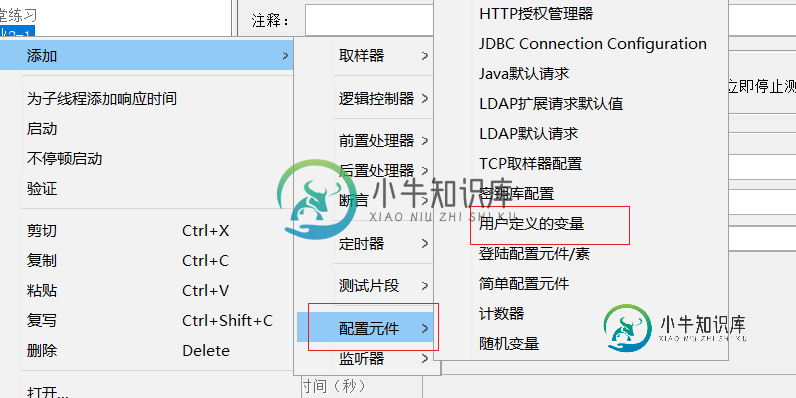 Jmeter参数化实现原理及过程解析
Jmeter参数化实现原理及过程解析本文向大家介绍Jmeter参数化实现原理及过程解析,包括了Jmeter参数化实现原理及过程解析的使用技巧和注意事项,需要的朋友参考一下 背景: 在实际的测试工作中,我们经常需要对多组不同的输入数据,进行同样的测试操作步骤,以验证我们的软件的功能。这种测试方式在业界称为数据驱动测试,而在实际测试工作中,测试工具中实现不同数据输入的过程称为参数化设置。 jmeter提供多种参数化设置的方式,常用的有:
-
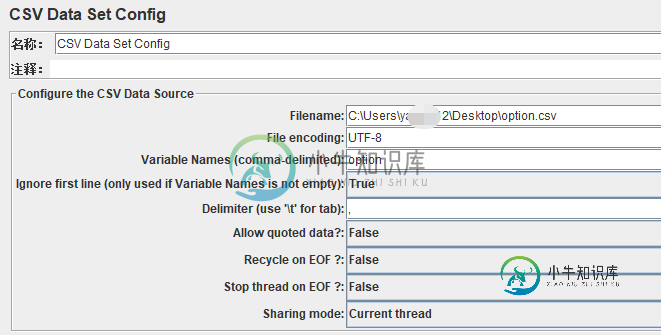 Jmeter参数化实现方法及应用实例
Jmeter参数化实现方法及应用实例本文向大家介绍Jmeter参数化实现方法及应用实例,包括了Jmeter参数化实现方法及应用实例的使用技巧和注意事项,需要的朋友参考一下 当使用JMeter进行测试时,测试数据的准备是一项重要的工作。若要求每次迭代的数据不一样时,则需进行参数化,然后从参数化的文件中来读取测试数据。 参数化:是自动化测试脚本的一种常用技巧,可将脚本中的某些输入使用参数来代替,如登录时利用GET/POST请求方式传递参
-
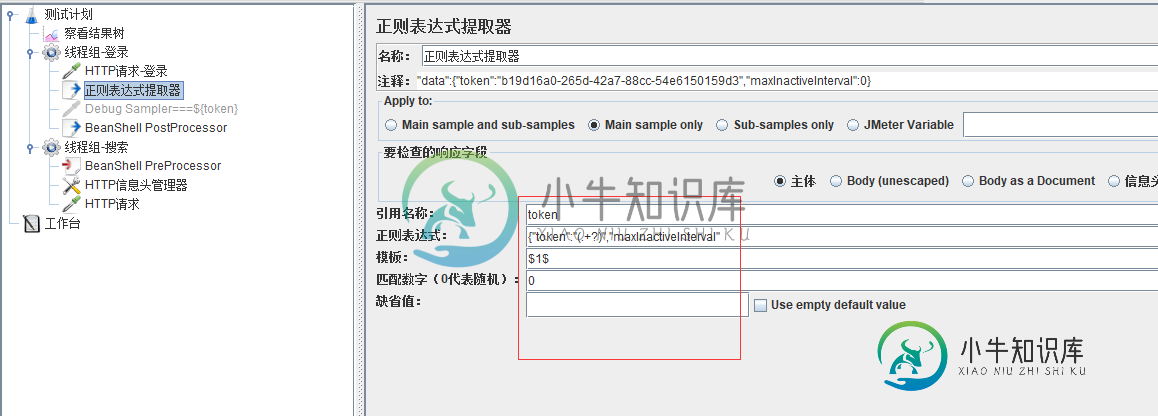 Jmeter线程组传参原理解析
Jmeter线程组传参原理解析本文向大家介绍Jmeter线程组传参原理解析,包括了Jmeter线程组传参原理解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了jmeter线程组传参原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景介绍: 使用jmeter做登录和搜索接口的测试: 登录接口请求头为:Content-Type: application/x-
-
如何在Webdriver-Sampler中传递变量 Jmeter Webdriver
问题内容: 我得到了一个包含8个以上Webdriver-Sampler和一个变量 的Testscript ,这些变量在某些Webdriver-Sampler中有所变化。 例如: 第一采样器: status =“登录成功” 第二采样器: status =“登录成功,搜索失败” 第三个采样器: status =“登录成功,搜索失败, 注销成功” 因此,我必须每次都传递变量,然后编辑该变量。我知道 可以
-
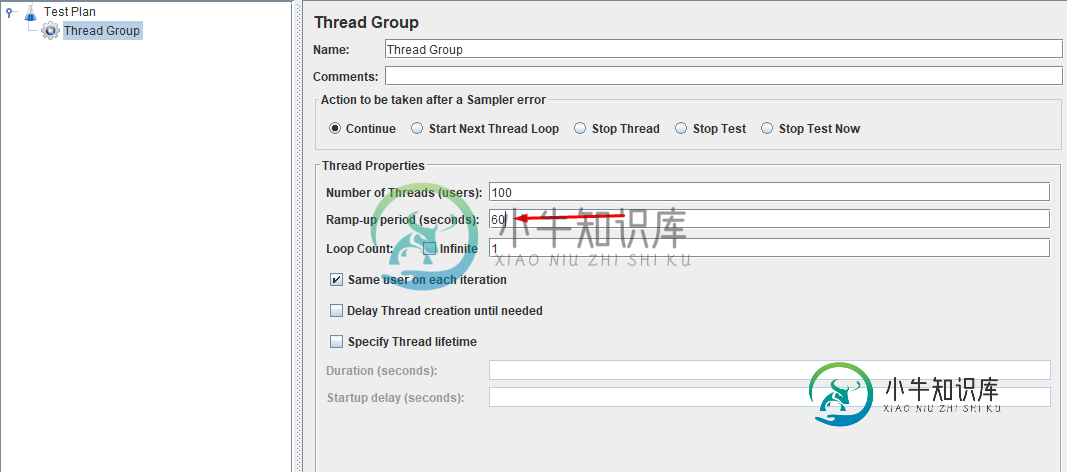 如何在jmeter中进行压力/性能测试?
如何在jmeter中进行压力/性能测试?我想进行压力测试,从预期的用户数开始(或从1个虚拟用户开始),然后逐渐增加负载,例如10个线程、20个线程等等…。100个线程,直到响应时间开始超过可接受的值或开始出现错误。但是对于所有这些测试运行,我应该增加爬升周期(秒),还是所有测试都保持不变?图片如下:
-
JMeter图-当有更多线程时,为什么响应时间较低
我正在使用Apache JMeter 5.0进行性能测试,线程组设置如下:线程数(用户)=100 爬升周期(以秒为单位)=5 循环计数=1 但是,我注意到,当线程数增加时,响应时间会变短。 能帮助解释或指导这里发生的事情吗?
-
jmeter-如何在聚合报告中设置最大值
我有一个Rest API的测试计划,其中有一个线程组和两个采样器。同时运行负载测试 线程数(用户):80 加速期:1 我得到"响应代码: 504响应消息:GATEWAY_TIMEOUT"在jmeta. 我观察到,当聚合图中的最大值达到60000ms时,所有响应都超时。需要采取哪些措施来防止超时问题。当我使用50个或更少的用户时,负载测试工作正常。
-
JMeter是否为许多虚拟用户显示了它所点击的第一个页面的正确平均响应时间?
我正在对一个有500个虚拟用户的系统进行负载测试。我将“上升周期(秒)”选项保持为零。所以,据我所知,JMeter将同时运行500个虚拟用户的系统。如果我错了,请纠正我。 现在,摘要报告显示第一页的平均响应时间为~100秒!。这比一分钟半的等待时间还要长。但是,当JMeter运行时,我使用浏览器手动转到同一页面/url,不必等待那么长时间。它甚至还没有关闭,页面的响应对我来说几乎是即时的。 我的问