《架构思维》专题
-
连接到合流平台架构注册表失败-Apache FlinkSQL合流Avro格式
我正在使用Confluent managed Kafka cluster、模式注册表服务,并试图在Flink作业中处理Debezium消息。作业已配置为使用表 表连接器配置 错误消息 我通过以下方式成功测试了与架构注册表的连接: 错误消息“io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException:Una
-
 测试室迁移,在资产文件夹[room migration]中找不到架构文件
测试室迁移,在资产文件夹[room migration]中找不到架构文件这个问题是在我决定将另一个实体添加到房间数据库之后出现的。架构正在预期目录中导出。所有的建筑。gradle设置已完成,似乎正在工作,但没有。自从我得到: 事实上,两个json模式都已生成,但测试运行程序无法找到此类文件。以下是gradle设置: 因此,很明显gradle插件所做的事情与iSpect或文档中所说的有所不同,但事实并非如此。
-
架构注册表容器:使用docker-compose启动时服务器意外死亡
我编写了docker-compose.yml文件来创建以下容器: null 我想要一个docker-compose文件来旋转必要的容器,公开所需的端口并互连依赖的容器。目标是让我使用来自Docker Hub的官方合流图像。我的docker-compose文件如下所示: 现在,当我运行时,将创建并启动所有这些容器。但是架构注册表容器将立即退出。提供以下输出: 我搜索了这个问题,但没有帮助。我尝试了各
-
要求数组在Swagger架构对象定义中至少包含一个元素
在我的< code>swagger.yaml中有一个这样的模式对象定义: 但是,生成的服务器仍然乐意接受使用此模式对象作为不包含任何字段的必需主体参数的POST请求。 我是否可以这样配置Swagger:<code>颜色</code>字段在<code>用户
-
启用架构创建支持在Spring启动器-starter-data-solr 中提供支持
我使用spring-boot-starter-data-solr,并希望利用Spring Data Solr的schmea cration支持,如文档中所述: 每当刷新应用程序上下文时,自动架构填充都会检查您的域类型,并根据属性配置将新字段填充到索引中。这要求 solr 在无架构模式下运行。 但是,我无法实现这一目标。据我所知,Spring启动器不会在@EnableSolrRepositories
-
无法为XML架构命名空间应用程序定位Spring NamespaceHandler-上下文
一切都很好,但当我包括Spring-Web依赖项时。我开始这个项目有问题。出现以下异常: 3.6.2.release/testproject/target/testproject-0.0.1-snapshot/},d:\users\yeap\workspace-sts 3.6.2.release\testproject\target\testproject-0.0.1-snapshot org.s
-
使用哪种数据库/服务架构来查询和存储指标数据?
我是系统开发的新手,想知道是否有比我更有经验的人可以帮助我解决有关数据库,Web服务和整体架构的一些问题。 我有一个应该每天运行的网络刮刀。它将从多个公开的政府数据中收集、筛选和汇总当地企业的数据。这些数据将被存储到Postgres数据库中。 然后,用户将拥有一个管理仪表板,可以在其中查看一些指标和趋势。我不知道的是,这个仪表板是否应该在用户每次加载仪表板时查询数据库。 我想这不是最明智的方法,因
-
DBIx::类架构处理在内存中和磁盘上SQLite之间有所不同
更新:解决了我的问题 我再次被make_schema_at的行为绊倒(请参阅代码中关于@INC被修改的注释,我已经为此提交了一份错误报告)。 下面是我编写代码的原因(以及我在第一条评论中提到的更正,即定义 在内存数据库的情况下,make_schema_at会断开与handle$dbh的连接,这不起作用!可以通过将db句柄的克隆传递给make_schema_at来解决这个问题。我也认为MaxyStu
-
Confluent 3.3无法使用kafka-avro-console-producer在本地连接到架构注册表
下载confluent open source 3.3后在命令行做一个简单的实验: 合流启动-启动所有服务时不会出现任何可见错误:
-
Android Clean架构:当模型涉及两个房间的桌子时,缓存映射
我有一个将两个表连接在一起的查询。我在kotlin中创建了一个数据类,其中包含我需要查询返回的每个表的变量。当我在DAO查询中更新模型时,我显然必须通过更新模型类的干净拱的层。我到了映射实体到域层的Mapper类。这里我遇到了一个问题,因为这个函数只能扩展到一个房间实体,我的数据类引用了两个表中的值。 界面 类 所以这个函数缺少表B中的所有值,因为我不能在mapper函数中扩展两个表。人们如何解决
-
如何让FlyWay运行我的迁移?“架构是最新的。不需要迁移。“
我有一个现有的数据库。我创建了两个迁移 我在中设置了以下内容 Spring Boot1.5.6,飞道芯3.2.1 Spring文档-FlyWay文档
-
查询Snowflake帐户中可用的表数(包括所有数据库和架构)
SQL查询以获得雪花帐户中可用的表的总数(包括所有数据库和架构)
-
 字节大数据开发推荐架构(深圳)日常实习一面(凉)75min
字节大数据开发推荐架构(深圳)日常实习一面(凉)75min9.20 24届非科班本发面筋攒好运! 第一次面+太紧张+基础不好+算法出没见过的hard = 寄 组是偏基础架构的 自我介绍到一半简介项目的时候就被打断了开始撕项目(乐 学习的方法 离线项目: 1.分层的好处,为什么分层 2.idmapping 3.拉链表的逻辑(用户活跃区间的中间表),下次还应该解释一下这个中间表的好处以及为什么方便。 实时项目: 1.维表动态注入的意义在哪里,为什么不直接写入
-
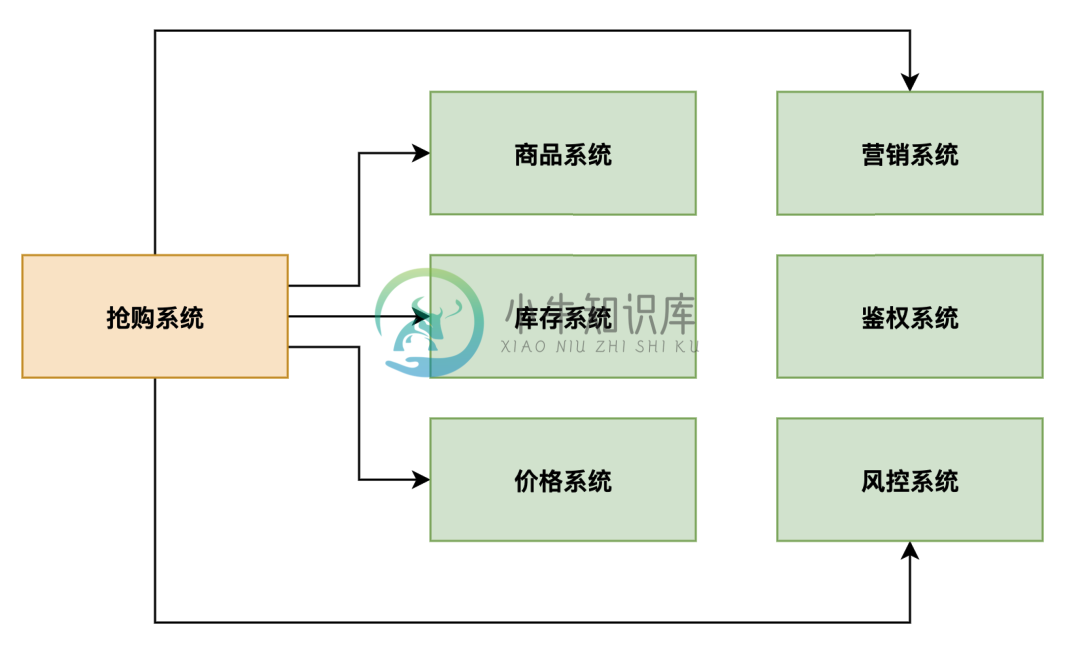 瞬时高并发抢购系统场景,你该如何设计系统架构?
瞬时高并发抢购系统场景,你该如何设计系统架构?主要内容:背景,业务架构设计,网络拓扑架构设计,秒杀业务流量洪峰,架构设计优化,总结背景 大家好,这篇文章给大家介绍一个非常经典的去大厂面试经常被问的一个问题,就是瞬时高并发抢购问题。 通常来说,大厂开发的系统经常会遇到一些类似电商秒杀抢购、景点门票高并发抢购、特殊商品(比如口罩)高并发抢购、类似 12306 的高并发抢票类的系统。 所以经常会问这一类高并发抢购类的问题,这个时候,小伙伴们如果不能有理有据的给出一整套高并发场景下系统可能遇到的各种问题,以及你对应的架构设计和解决方
-
1.4.3 数据处理平台架构中的 SMACK 组合:Spark、Mesos、Akka、Cassandra 以及 Kafka
数据处理平台架构中的SMACK组合:Spark、Mesos、Akka、Cassandra以及Kafka 在今天的文章中,我们将着重探讨如何利用SMACK(即Spark、Mesos、Akka、Cassandra以及Kafka)堆栈构建可扩展数据处理平台。虽然这套堆栈仅由数个简单部分组成,但其能够实现大量不同系统设计。除了纯粹的批量或者流处理机制之外,我们亦可借此实现复杂的Lambda以及Kappa架