《并发》专题
-
将数据发送到一个方法并逐一检查
我得到了一个在Java中创建Ulam螺旋的挑战,但在创建Ulam螺旋之前,用户应该输入2个数字。这两个数字应该检查一下,所以它们不是质数。只要其中一个被写入的数字是素数,那么程序应该重新启动并要求2个新的数字。 getInput方法要求用户输入2个数字。在写入这些数字之后,应该调用isPrime方法,并且应该一次检查一个数字,如果它是Prime。如果检查的第一个数字不是素数,那么应该检查第二个数字
-
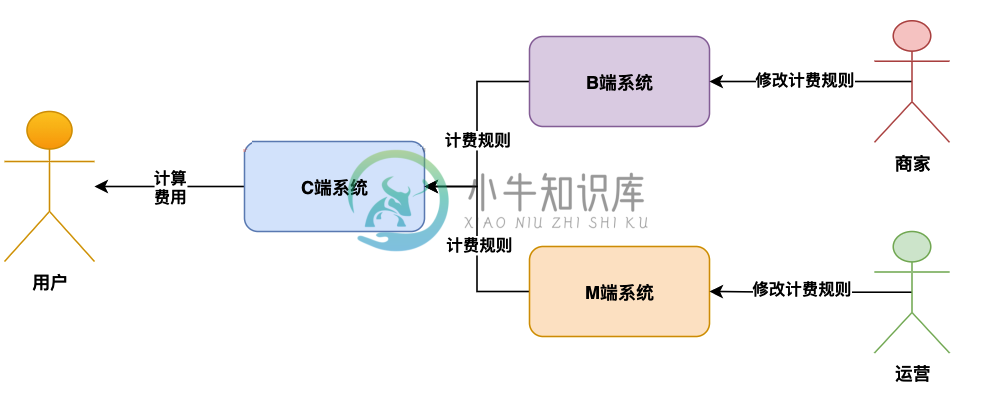 高可用高并发架构系统该如何设计?
高可用高并发架构系统该如何设计?主要内容:背景,计费业务系统架构设计,计费业务数据补偿系统设计,总结背景 今天给大家分享一个话题,就是对于线上跟钱有关的计费类的系统,在线上可能出现的一些把钱算错的问题,以及我们如何来设计架构解决这些问题。 但凡是跟算钱相关的系统,都是每个公司的重中之重,比如说价格系统、运费系统、计费系统、支付系统、基金系统、财务系统、结算系统等等,因为这些系统运行过程中,随时可能因为技术问题或者运营的人为误操作问题,把钱给算错了。 所以今天来给大家讲讲这一类跟算钱有关的系统,我
-
第5章 多线程 - 集合及concurrent并发包总结
1. 集合包 集合包最常用的有Collection和Map两个接口的实现类,Colleciton用于存放多个单对象,Map用于存放Key-Value形式的键值对。 Collection中最常用的又分为两种类型的接口:List和Set,两者最明显的差别为List支持放入重复的元素,而Set不支持。 List最常用的实现类有:ArrayList、LinkedList、Vector及Stack;Set接
-
使用Java构建微服务并发布到Kubernetes平台
Java作为多年的编程语言届的No.1(使用人数最多,最流行),使用它来构建微服务的人也不计其数,Java的微服务框架Spring中的Spring Boot和Spring Cloud已成为当前最流行的微服务框架。 下面是Sping技术栈所包含的技术框架图。 当然如果在Kubernetes中运行Java语言构建的微服务应用,我们不会使用上图中所有的技术,本节将主要讲解如何使用Spring Boot构
-
第6章 基于锁的并发数据结构设计
本章主要内容 并发数据结构设计的意义 指导如何设计 实现为并发设计的数据结构 在上一章中,我们对底层原子操作和内存模型有了详尽的了解。在本章中,我们将先将底层的东西放在一边(将会在第7章再次提及),来对数据结构做一些讨论。 数据结构的选择,对于程序来说,是其解决方案的重要组成部分,当然,并行程序也不例外。如果一种数据结构可以被多个线程所访问,其要不就是绝对不变的(其值不会发生变化,并且不需同步),
-
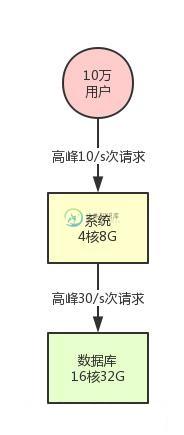 天猫双11高并发架构是怎么设计的?
天猫双11高并发架构是怎么设计的?主要内容:一、背景引入,二、先考虑一个最简单的系统架构,三、系统集群化部署,四、数据库分库分表 + 读写分离,五、缓存集群引入,六、引入消息中间件集群,七、现在能hold住高并发面试题了吗?,八、本文能带给你什么启发?一、背景引入 这篇文章,我们聊聊大量同学问我的一个问题,面试的时候被问到一个让人特别手足无措的问题:你的系统如何支撑高并发? 大多数同学被问到这个问题压根儿没什么思路去回答,不知道从什么地方说起,其实本质就是没经历过一些真正有高并发系统的锤炼罢了。 因为没有过相关的项目经历,所以就
-
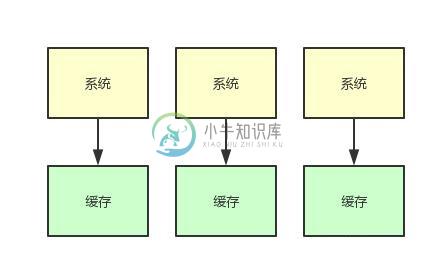 一文搞懂高并发下的缓存设计方案!
一文搞懂高并发下的缓存设计方案!主要内容:一、为什么要用缓存集群,二、20万用户同时访问一个热点缓存的问题,三、基于流式计算技术的缓存热点自动发现,四、动加载为JVM本地缓存,五、限流熔断保护,六、本文总结一、为什么要用缓存集群 这篇文章,咱们来聊聊热点缓存的架构优化问题。 其实使用缓存集群的时候,最怕的就是热key、大value这两种情况,那啥叫热key大value呢? 简单来说,热key,就是你的缓存集群中的某个key瞬间被数万甚至十万的并发请求打爆。 大value,就是你的某个key对应的value可能有GB级的大小,导
-
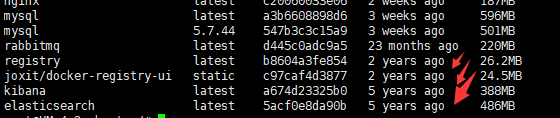 docker 拉取最新版本,发现并不是最新的?
docker 拉取最新版本,发现并不是最新的?docker pull 这个命令 我当时想的是拉取最新版本的镜像 结果发现tag是latest 但是版本不是最新的 dockerhub库中有最新的 这是不是说明我的docker拉取的仓库不对啊 怎么修改 或配置 我配置了阿里加速 下面是配置的阿里的
-
从表单获取日期并将其保存到数据库并列出产品
问题内容: 我正在尝试创建一个页面,该页面可以列出保存在数据库中的产品,然后客户可以查看可用产品的列表。我遇到的问题是Java中的日期。 我收到的错误消息是 有人可以告诉我怎么了吗? 问题答案: 更换 通过
-
是否可以将多个pdf页面合并为一张pdf并在Java打印?
我正在尝试创建Java程序,它可以读取多个pdf文件,并将它们合并成一个单一的pdf文件。然后打印PDF,但在打印时,我需要将多个PDF页面合并在一个页面中并打印。即使它是一个新的pdf创建,那对我来说是好的。我需要一些开源的Java pdf操纵库来处理这个。我知道一个解决方案是在打印时,选择多个打印选项,将多页打印到一张纸上。但我可以访问的打印机没有这样的功能。有谁能为这个问题提出一些解决方案,
-
如何将较小的ORC文件合并或合并为较大的ORC文件?
问题内容: SO和Web上的大多数问题/答案都讨论了如何使用Hive将一堆小的ORC文件组合成一个更大的文件,但是,我的ORC文件是日志文件,每天都分开,因此我需要将它们分开。我只想每天“汇总” ORC文件(它们是HDFS中的目录)。 我最有可能需要用Java编写解决方案,并且遇到过OrcFileMergeOperator,这可能是我需要使用的内容,但还为时过早。 解决此问题的最佳方法是什么? 问
-
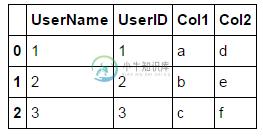 熊猫在具有不同名称的列上合并并避免重复[重复]
熊猫在具有不同名称的列上合并并避免重复[重复]如何将两个熊猫DataFrames合并到两个具有不同名称的列上,并保留其中一个列? 这提供了一个像这样的数据帧 但是很明显,我正在合并和,所以它们是相同的。我想让它看起来像这样。有什么干净的方法可以做到这一点吗? 我唯一能想到的方法是在合并之前将列重新命名为相同的列,或者在合并之后删除其中一个列。如果熊猫自动掉落其中一只,我会很高兴,或者我可以做类似的事情
-
 绘制甘特图:删除重复的Y轴标签并堆叠并行任务
绘制甘特图:删除重复的Y轴标签并堆叠并行任务我计划使用python库“Plotly”构建甘特图。具体而言:https://plotly.com/python/gantt/#group-一起完成任务。 然而,每个“作业”可以有多个任务,并且这些任务可以并行运行。从我观察到的情况来看,Plotly并没有将并行运行的任务堆叠在一起,这使得读取图表非常困难。下面是一个示例,“作业A”有两个并行运行的任务,但只有一个可见: 我想要的是“作业A”任务都
-
将元素添加到结构数组并合并Spark 2.3中的结构数组
我有下面的数据帧模式作为df.current模式,需要获得预期的模式作为df.expected模式,有没有一种方法,我可以在火花2.3实现这一点 df.current架构: df。预期架构: 示例数据: 注意:这里需要实现两件事: 为元素中的每个E、V对创建新字段SN,其值应为数组名称。例如:对于第一个数组列(ADA),SN的值=ADA 将阵列(ADA、ADW)合并为一个外部阵列(信号)
-
将spark数据拆分为分区并将这些分区并行写入磁盘
问题概要:假设我有300 GB的数据正在AWS中的EMR集群上用火花处理。这些数据有三个属性,用于在Hive中使用的文件系统上进行分区:日期、小时和(比方说)另一个。我想以最小化写入文件数量的方式将此数据写入fs。 我现在正在做的是获取日期、小时、另一个时间的不同组合,以及有多少行构成组合的计数。我将它们收集到驱动程序上的列表中,并遍历列表,为每个组合构建一个新的DataFrame,使用行数重新分