《架构师》专题
-
 在ASP.NET 2.0中操作数据之五十七:在分层架构中缓存数据
在ASP.NET 2.0中操作数据之五十七:在分层架构中缓存数据本文向大家介绍在ASP.NET 2.0中操作数据之五十七:在分层架构中缓存数据,包括了在ASP.NET 2.0中操作数据之五十七:在分层架构中缓存数据的使用技巧和注意事项,需要的朋友参考一下 导言: 正如前面章节所言,缓存ObjectDataSource的数据只需要简单的设置一些属性。然而,它是在表现层对数据缓存,这就与ASP.NET page页面缓存策略(caching policies)紧
-
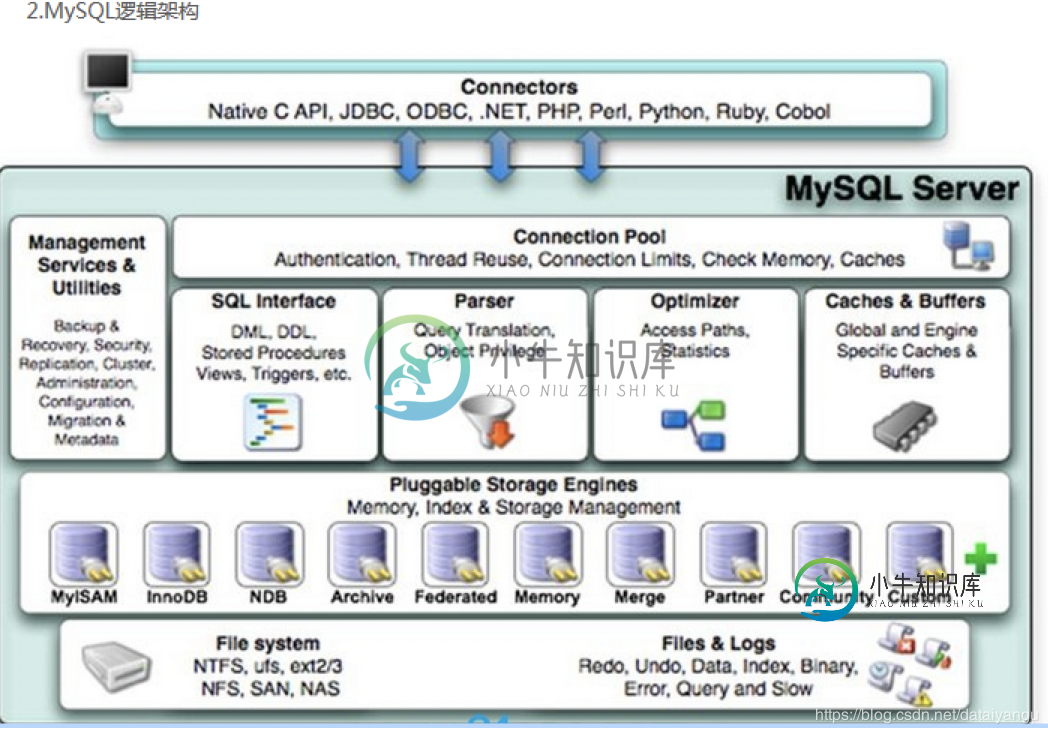 MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎详解
MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎详解本文向大家介绍MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎详解,包括了MySQL高级学习笔记(三):Mysql逻辑架构介绍、mysql存储引擎详解的使用技巧和注意事项,需要的朋友参考一下 Mysql逻辑架构介绍总体概览 和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其
-
BatchGetItem操作上的DynamoDB和Boto3错误:“提供的键元素与架构不匹配”
我在Boto3/DynamoDB BatchGetItem操作中遇到困难。我将非常感谢任何帮助或指导!我对python/aws非常陌生,如果这是一个新手问题,那么很抱歉在高级版。 当我执行该操作时,会出现以下错误: 这是我的代码: 这是表中项目的屏幕盖。 这是表详细信息的屏幕盖,显示分区键为'item_ID',是'string' 以下是完整的错误消息:
-
每个EC2实例中AWS弹性beanstalk中docker容器的缩放数量[app架构]
我有一个dockerized数据应用程序,它运行长时间的计算,并且没有多线程或异步的灵活性,因此多用户是一个日益严重的问题。docker映像目前运行在弹性Beanstalk上(主要是为了熟悉AWS),但我很快注意到水平缩放EC2实例,在每个EC2实例运行一个docker容器,将会非常昂贵。应用程序的计算并不是非常占用CPU的,所以最好利用每个实例的容器数量。 弹性Beanstalk是否有一个策略来
-
 从DynamoDB获取项时出现“提供的键元素与架构不匹配”错误
从DynamoDB获取项时出现“提供的键元素与架构不匹配”错误当我试图从表中获取项目时,它会打印此错误 botocore.exceptions.ClientError:调用GetItem操作时发生错误(ValidationException):提供的键元素与架构不匹配 这是我的密码 有什么想法吗?谢谢
-
为什么我的org.springframework.test.web.servlet.MockMvc框架无法解析控制器的构造函数参数
我想为我的Spring Boot应用程序创建一个单元测试,但在启动一个测试时,我收到以下错误: 当我试图从运行测试时,无法满足构造函数参数,反之亦然。 该应用程序很简单,只有两个控制器,用于管理订单和用户。源代码具有以下结构: 一般来说,为了构建我的应用程序,我试着遵循Spring Boot kotlin教程。 应用程序本身运行没有任何问题。问题在于运行测试时。 我看到框架提出的行动相当明显: 考
-
将XJC与xml.xsd导入一起使用时出错:“无法读取架构文档'xml.xsd'”
我试图在第三方的模式文件上运行xjc(它是Amazon.com的产品API)。我遇到了麻烦,因为对于其中一个文件default.xsd,xjc忽略了以下导入(它是模式声明之后的第一个导入): [警告]schema_reference.4:无法读取架构文档“xml.xsd”,因为1)找不到该文档;2)无法读取该文档;3)文档的根元素不是。文件:/c://temp/amazon/default.xsd
-
在java多线程客户机-服务器架构中从run()方法调用方法
我试图在run()方法中调用其他方法。但只有在退出/终止客户端连接时,这些方法才会显示输出。例如:当客户端发出listall命令时,应该打印listall方法。但它只有在客户端终止连接时才会被调用。 谁能告诉我我做错了什么吗 运行()
-
在软件设计架构中,过程内聚和顺序内聚有什么区别?
程序内聚性表示模块的零件被分组是因为它们总是遵循特定的执行顺序,而顺序内聚性表示模块的零件被分组是因为一个零件的输出是另一个零件的输入,就像装配线一样。这些定义模棱两可。请解释一下。
-
在测试模式下使用飞行路线玩游戏:未找到“公共”架构
我在开发和生产模式下(成功)使用飞行方式游戏插件。我还想在测试模式下使用它。文档说,它在测试模式下自动运行迁移。 我使用scala测试,我的测试用例被包装在一个假的应用程序中 运行测试用例时,自动转换失败,并显示“未找到Schema public”: 这个错误到底是什么意思?为什么它使用公共模式?我的数据库配置定义了“db.default”,而不是“db.public”。什么是公共模式?我没有在任
-
需要将所有传单更新固定到指定架构中的 1 个schema_version表
我们希望能够将所有sql执行固定到架构A中的特定schema_version表。我们需要这个,以便我们可以将sqls作为系统运行,并且飞行方式始终引用A.schema_version来验证校验和并更新SQL运行的结果。我们尝试添加以下设置: 飞行路线。schemas=A flyway.table=schema_version 然而,我们发现,如果我们以用户B的身份运行info,那么flyway无法
-
XSD架构错误:XmlSchema错误:Element http://www.w3.org/2001/XmlSchema:Element在此上下文中无效
我正在尝试验证这个XML文件第127行XmlSchema错误:Element http://www.w3.org/2001/XmlSchema:Element在此上下文中无效。125号线,位置4。相关架构项sourceURI:virtual://server/schema.xsd,第177行,位置2。 在这一行-->xs:element name=“msg:market”type=“type-sc
-
在springboot微服务架构中,带有JSON主体的POST请求不传递到endpoint
-
 美团三面:消息中间件实现高可用架构,你会怎么设计?
美团三面:消息中间件实现高可用架构,你会怎么设计?主要内容:一、背景引入,二、先来思考一下消息中间件的可用性问题,三、集群化部署 + 数据多副本冗余,四、多副本同步复制强制要求,五、多机器承载多副本强制要求,六、架构原理与技术无关性一、背景引入 这篇文章,我们来聊一下消息中间件高可用架构的一些原理。 对于一个合格的高级Java工程师而言,你肯定会碰到在系统里用到MQ的场景,那么这个时候你需要基于你的业务场景和需求,考虑在使用MQ的时候可能遇到的一些技术问题。 接着,你必须得针对这些技术问题设计一套完整的技术方案。 你需要从消息的订阅模式、消息的
-
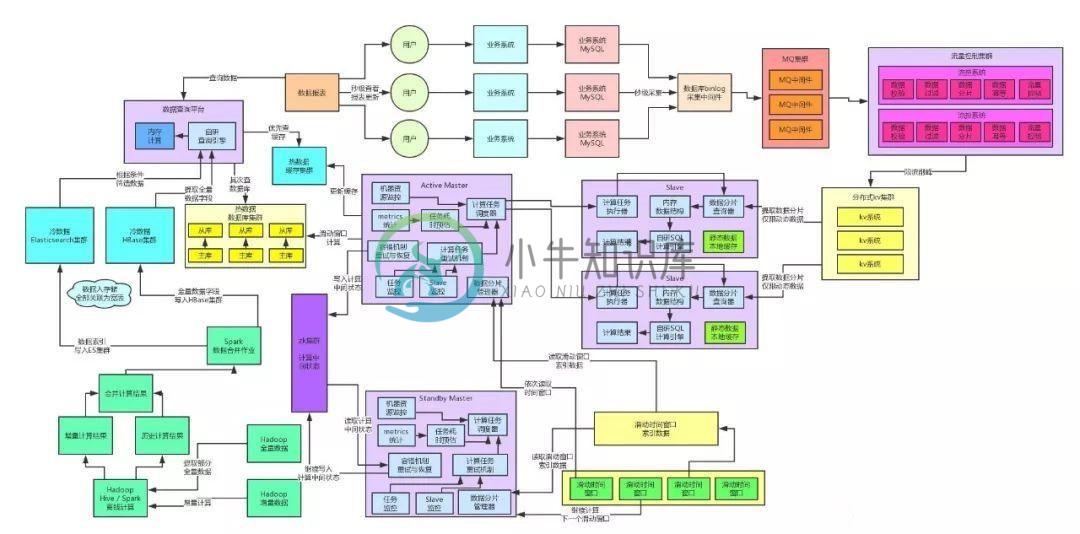 超大流量全链路4个9的高可用架构设计演进过程
超大流量全链路4个9的高可用架构设计演进过程主要内容:一、前情回顾,二、MQ集群高可用方案,三、KV集群高可用保障方案,四、实时计算链路高可用保障方案,五、热数据高可用保障方案,六、冷数据高可用保障方案,七、最终总结一、前情回顾 冷热数据分离: 冷数据基于HBase+Elasticsearch+纯内存自研的查询引擎,解决了海量历史数据的高性能毫秒级的查询 热数据基于缓存集群+MySQL集群做到了当日数据的几十毫秒级别的查询性能。 最终,整套查询架构抗住每秒10万的并发查询请求,都没问题。 本文作为这个架构演进系列的最后一篇文章,我们来聊聊