《2024届毕业生现状》专题
-
使用doclava生成Javadoc时出现可空注释错误
我试图在Android Studio中使用Doclava为Android库生成Javadoc。源代码在某些时候使用了“Nullable”标记,这会在生成javadoc时导致崩溃: 在doclet类com中。谷歌。多克拉瓦。Doclava,方法start引发了一个异常java。朗。反思。调用TargetException com。太阳工具。javac。密码Symbol$CompletionFailu
-
npm在react native中运行android时出现生成错误
运行: JS服务器已经运行。 在设备上构建和安装应用程序(cd) 失败:构建失败,有一个异常。 出了什么问题: 配置根项目“pusher”时出现问题。无法解析配置“:classpath”的所有依赖项。无法下载protobuf java。jar(com.google.protobuf:protobufjava:2.5.0)无法获取资源的https://jcenter.bintray.com/com/
-
失败:生成失败,出现异常。应为BEGIN_ARRAY,但为
-
生成。Gradle错误-评估项目“: app”时出现问题
当我试图运行我的应用程序时,我遇到了以下错误。 评估项目: app时出现问题。 提供的字符串模块表示法“commons io:common无法解析配置的所有依赖项”:app:debugRuntimeClasspath。s-io:2.6'无效。示例注释:“org。gradle:gradle核心:2.2','组织。mockito:mockito核心:1.9.5:javadoc'。 >
-
Python使用multiprocessing实现一个最简单的分布式作业调度系统
本文向大家介绍Python使用multiprocessing实现一个最简单的分布式作业调度系统,包括了Python使用multiprocessing实现一个最简单的分布式作业调度系统的使用技巧和注意事项,需要的朋友参考一下 mutilprocess像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多。 介绍 P
-
 Angular2 ag电网企业项目在放置许可证密钥时出现问题
Angular2 ag电网企业项目在放置许可证密钥时出现问题我有许可证的ag网格企业版,但我没有;不知道如何把它和如何导入企业在我的angular2项目。 我正试着把许可证放在主要位置。ts向licenseManager提交文件,并将企业版放入软件包中。json和systemjs。配置。json systemjs.config.js: 包裹json 主要的ts "错误:错误:XHR错误(404未找到)加载http://localhost:3000/node
-
线程“main”java中出现异常。io。IOException:作业中未指定输入路径
我正在尝试使用Java中的spark读取json文件。我尝试的几个更改是: SparkConf conf=新SparkConf()。setAppName(“搜索”)。setMaster(“本地[*]”); DataFrame df=sqlContext。读取()。json(“../Users/pshah/Desktop/sample.json/*”); 代码: 错误:
-
java - 最终一致性思想应用的业务场景以及实现形式?
最近在学分布式事务,了解到分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP和BASE两大理论,实现AP模式或者CP模式。 对于CP模式的使用场景,我可以理解成将多个事务合成为一个大的事务去提交、回滚。 但是我对于AP的最终一致性思想仅仅停留在概念上,对于具体业务场景以及在出现不一致情况下如何进行弥补依然比较模糊,望大佬们可以解答一下,此外,如果可以,希望大佬可以分享一下,实践中这两
-
如何使管道作业等待所有触发的并行作业?
问题内容: 我将Groovy脚本作为Jenkins中Pipeline工作的一部分,如下所示: 由于将标记设置为,因此它并行执行多个其他自由式作业。但是,我希望所有作业完成后才能完成呼叫者作业。目前,Pipeline作业会触发所有作业并在几秒钟后自行完成,这不是我想要的,因为我无法跟踪总时间,而且我无法一次取消所有已触发的作业。 当并行完成所有作业时,如何纠正上述脚本以完成管道作业? 我试图将构建作
-
在上游作业中显示下游作业的控制台输出
问题内容: 我正在使用詹金斯。 詹金斯(Jenkins)有上游工作:A 詹金斯(Jenkins)有下游工作:B A的控制台日志输出为: B的控制台日志输出为: 我想要得到的是: 有什么办法,我可以在作业A的控制台日志中获取作业B的控制台输出,然后确定作业“ A”是否成功(使用日志解析/ grep表示故障/错误等关键字)。 问题答案: 不确定您要达到的目标,但是看起来有些人为。查看以下方法是否满足您
-
将作业配置导入通用作业配置类(注释配置)
我正在重构一个传统的基于Spring Batch XML的应用程序,以使用注释配置。我想了解如何将以下XML文件转换为基于注释的配置,并保持相同的关注分离。 为了便于讨论,这里有一个简单的例子。 job-config-1.xml job-config-2.xml job-config-3。xml 我想从XML配置转移到Java配置。我想为每个XML创建3个作业配置类。比如说JobConfig1。j
-
一个作业更新另一个作业输出的最佳方法
下面是我的场景。我的工作是处理大量的csv数据,并使用Avro将其写入按日期划分的文件中。我得到了一个小文件,我想用它来更新这些文件中的一些附加条目,第二个作业我可以在需要时运行,而不是再次重新处理整个数据集。 这个想法是这样的: job1:处理大量的csv数据,将其写入压缩的Avro文件中,并按输入日期拆分为文件。源数据不按日期划分,因此此作业将做到这一点。 job2(在Job1运行之间根据需要
-
如何在azkaban 3.0中从作业文件中获取作业名称
当试图安排作业时,我们需要来自Azkaban的作业名称。有什么内置属性吗?我们从获取流名称。 我的工作文件是:
-
无法将作业参数传递给步骤-Spring批处理作业
我们正在实施Spring批量作业, 我们需要将作业参数从Client/MASTER传递给SLAVE。CLIENT/MASTER是我们的作业和分区代码所在的位置。我们使用传递JOB参数的J Unit调用JOB。 SLAVE是定义所有步骤及其实现(读取器Writer和处理器)的地方。 我们能够以独立的方式实现这一点,但不能与客户一起实现 我们正在使用Weblogic和Spring集成以及JMS来实现同
-
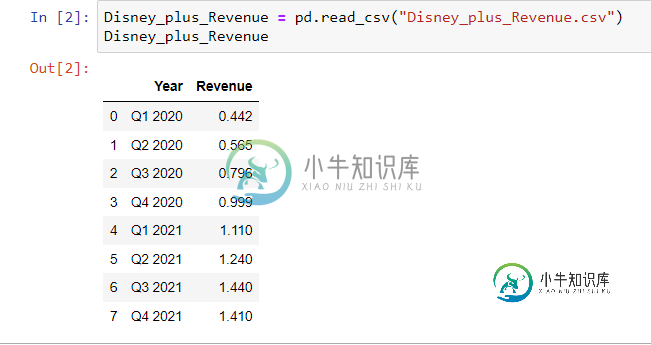 使用 Pandas 将季度业绩转换为年度业绩的建议
使用 Pandas 将季度业绩转换为年度业绩的建议因此,我有2020年第一季度至2021第四季度迪士尼加收入的季度数据。 错误-