《管培上岸经验》专题
-
多台机器上的Java RMI注册表对象管理
假设我的系统中有3个节点:node1、node2、node3,我在所有3个节点上都有远程对象。我的问题是: 我可以在node1上运行一个注册表实例并让它管理3个节点上的所有对象,还是每个节点都需要自己的注册表实例?也就是说,一个注册表只能在自己的机器上管理对象,还是也可以在其他机器上管理对象?
-
在aws s3上托管静态站点时使用google域
我在AWS/S3上与其他域名注册商建立了许多静态站点;但是,google域给我带来了一些问题。 我采取的步骤: -在S3/AWS上: > 已创建桶domainname.org 通过添加index.html启用静态网站托管 已将index.html和相关文档上载到存储桶 创建桶www.domainname.org以重定向到桶domainname.org 为domainname.org创建了桶策略,如
-
我话题上的耐用标志消费者不管用?
尝试在主题使用者上实现持久功能。为 jms 使用者和客户端 ID 放置了一个名称。(显然添加了持久=“真”) 据我所知。当它第一次运行时,该主题会将消费者注册为“耐用”。 所以基本上我这样做了,部署了生产者和消费者。它被注册为耐用消费者。将消息发布到主题,消费者将获得消息。现在,我取消部署消费者,并发布另一条消息,消费者无论何时起床都应该收到。当我再次部署消费者时,我得到了通用的temp-topi
-
数据流管道上的BigQuery SQL作业依赖关系
我有一个python中的ApacheBeam管道,不管出于什么原因,它都有下面这样的流。 SQL作业-- 当我在本地运行此程序时,此序列工作正常。然而,当我试图将其作为数据流管道运行时,它实际上并没有按此顺序运行。 在数据流上运行时是否有强制依赖关系的方法?
-
在应用服务器上托管Java Swing应用程序
但是所有的答案和评论对链接帖子的回应也没有太大帮助
-
4.9 服务器上的 Git - 第三方托管的选择
如果不想设立自己的 Git 服务器,你可以选择将你的 Git 项目托管到一个外部专业的托管网站。 这带来了一些好处:一个托管网站可以用来快速建立并开始项目,且无需进行服务器维护和监控工作。 即使你在内部设立并且运行了自己的服务器,你仍然可以把你的开源代码托管在公共托管网站——这通常更有助于开源社区来发现和帮助你。 现在,有非常多的托管供你选择,每个选择都有不同的优缺点。 欲查看最新列表,请浏览 G
-
 7.4-上海中厂后端开发实习主管面-25min
7.4-上海中厂后端开发实习主管面-25min请做个自我介绍 上一段实习做了多久? 为什么想来上海? 大四是没有课了嘛?可以全职实习吗? 你上一个实习做了什么事情? 数据量多大? 第一个项目做了哪些工作? 修复了什么样的bug? 第二个项目做了什么? 对自己的规划是怎么样? 你只会Java吗?有实际写过其他语言的项目吗?Java学习了多久? 对linux了解吗? 是部署了自己的项目吗? 数据库用了哪些? 会哪些优化数据库的手段? 对人工智能有
-
Tensorflow:在分布式培训中使用参数服务器
问题内容: 尚不清楚参数服务器如何知道分布式张量流训练中的操作。 例如,在此SO问题中,以下代码用于配置参数服务器和工作程序任务: 如何指示给定的任务应该是参数服务器?参数是一种默认的任务行为吗?您还能/应该告诉参数服务任务做什么? 编辑 :这个SO问题解决了我的一些问题:“逻辑确保将Variable对象均匀分配给充当参数服务器的工作程序。” 但是参数服务器如何知道它是参数服务器?是否足够? 问题
-
在AWS Sagemaker培训期间从检查点重新加载
Sagemaker是培训您的模型的绝佳工具,我们通过使用AWS spot实例节省了一些资金。然而,培训工作有时会在中间停止。我们正在使用一些机制在重新启动后从最新的检查点继续。另请参见文档。 不过,您如何有效地测试这种机制?你能自己触发吗?否则,您必须等待spot实例实际重新启动。 另外,您是否需要为此使用链接的参数或?例如,估计器文档似乎为检查点建议了一些。
-
如何使用可变大小的输入进行培训?
这个问题相当抽象,不一定与tensorflow或keras有关。假设您想要训练一个语言模型,并且您想要为您的LSTM使用不同大小的输入。我特别关注这篇论文:https://www.researchgate.net/publication/317379370_A_Neural_Language_Model_for_Query_Auto-Completion. 除其他外,作者使用单词嵌入和一种热字符编
-
OpenNLP名称查找器培训:不支持的语言:en
根据文档中的指南,我试图在一些数据上测试training OpenNLP的Name Finder。然而,我遇到了错误:,这似乎没有任何意义。 我运行的命令是: 我从https://opennlp.apache.org/download.html.环境变量似乎设置正确,基本文件夹中的文件夹包含一个文件夹。 编辑:这似乎与CoNLL2003格式有关。如果我尝试直接运行训练器而不指定它就可以工作。但是我
-
如何在OpenNLP中培训“乌尔都语”的NER模型?
我想使用Apache OpenNLP为我的母语乌尔都语训练NER模型。我已经准备好了中的训练数据。制作训练模型(. bin)的下一步是什么,就像我们在模型下载部分的OpenNLP站点上找到的那样。
-
如何在AWS sagemaker中运行预先培训的模型?
我有一个模型。预训练的pkl文件以及与ml模型相关的所有其他文件。我想把它部署到aws sagemaker上。但是在没有培训的情况下,如何将其部署到aws sagmekaer,就像aws sagemaker中的fit()方法一样,运行train命令并推送模型。焦油gz到s3位置,当使用deploy方法时,它使用相同的s3位置来部署模型,我们不会在s3中手动创建与aws模型创建的位置相同的位置,并使
-
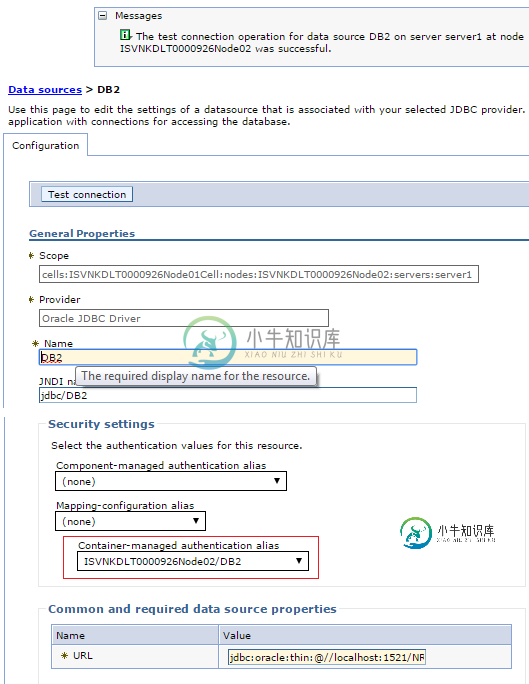 (OpenJPA/WAS)如何将容器托管身份验证用于容器托管实体管理器
(OpenJPA/WAS)如何将容器托管身份验证用于容器托管实体管理器了解如何配置WAS或OpenJPA,以便通过容器管理的实体管理器使用容器管理的身份验证。 试图通过在JNDI中注册为“JDBC/DB2”(指Oracle)的JDBC数据源访问Oracle数据库,该数据源在persistence.xml中定义。 persistence.xml 但是,当访问持久性单元的容器管理实体管理器时,会抛出ORA-01017无效的usrname/password。如果在pers
-
EC2 上的 Kafka 代理未连接到本地网络上的动物园管理员
伙计们,如果有人经历过这个问题,请你帮帮我,我一直在绞尽脑汁,但没有成功,我尽可能多地阅读了很多帖子。 场景我有动物园管理员/两个经纪人和一个生产者和消费者在我的本地分区上运行,来自我子网内的不同IP地址,一切都很完美。我的生产者生产-消费者消费生活快乐。 我想在EC2上复制这一点,并在EC2中创建一个kafka代理,并希望该代理连接到我的动物园管理员,但由于某种原因,EC2上的代理无法连接到我。