《审计》专题
-
实体类的正确设计。需要建议
问题内容: 例如,我有实体类: 接下来,我添加新的实体类: 接下来,我可以添加越来越多的实体类。 而且,此刻我想:我可以/必须以逻辑结构绑定/连接我的实体类,还是没有? 我的意思是说?我尝试解释一下: 要点1:所有这些类:,以及其他- 。 想法1:需要通过接口或抽象类对此类进行逻辑绑定。 第2点:我看到,所有实体类都有相同的方法:和。 想法2:需要避免在所有类中声明此方法。 我的解决方案: 添加界
-
带条件的停止计时器仅在第一次工作?
问题内容: 我正在编写“谁想成为百万富翁”游戏,并且我已经完成所有设置,这只是计时器的问题。 游戏的工作方式如下:如果用户正确回答了问题,他/她便会继续前进。如果不是,则游戏结束,他们可以选择再次玩。 游戏首次运行时,一切正常,计时器执行应做的事情-从30秒开始,倒计时,显示秒数。 但是,当用户单击“再次播放”按钮时,先前的计时器将继续使用新的计时器。像这样: -timerA在用户迷路之前还剩20
-
计算if和else的数量,不包括嵌套的if-else
问题内容: 谁能告诉我如何编写一个程序,其中我必须从文本文件中读取ac程序,然后计算if-else语句的数量,但不包括嵌套的if- else。在此程序中,我已经计算了文本文件中if和else的数量,但是如何从此计数中排除嵌套的if?请帮助我。 问题答案: 通常,以计数方式指定if-else语句是错误的,因为在编程语言中,if-else语句不仅是包含或的行(请考虑注释中的“ if”或“ else”词
-
如何通过SNMP查找打印机的计数器
问题内容: 我目前正在从事一个项目,涉及通过SNMP从打印机获取信息。现在,我一直在测试/研究的打印机是Lexmark X950。 我一直在努力的一个问题是,我也希望该程序也适用于HP或Kyocera或Brother打印机,但是我使用的OID似乎只能在Lexmark上使用。 这是我使用的一些OID: 如您在这里看到的,我主要将1.3.6.1.4.1.641用作我的OID,但它们仅适用于Lexmar
-
您所熟悉的测试用例设计方法都有哪些?
本文向大家介绍您所熟悉的测试用例设计方法都有哪些?相关面试题,主要包含被问及您所熟悉的测试用例设计方法都有哪些?时的应答技巧和注意事项,需要的朋友参考一下 (1)等价类划分 (2)边界值分析法 (3)错误推测法 (4)因果图方法
-
测试计划工作的目的是什么?测试计划文档的内容应该包括什么?
本文向大家介绍测试计划工作的目的是什么?测试计划文档的内容应该包括什么?相关面试题,主要包含被问及测试计划工作的目的是什么?测试计划文档的内容应该包括什么?时的应答技巧和注意事项,需要的朋友参考一下 1)借助软件测试计划,参与测试的项目成员,尤其是测试管理人员,可以明确测试任务和测试方法,保持测试实施过程的顺畅沟通,跟踪和控制测试进度,应对测试过程中的各种变更。 测试背景 测试目标 测试范围 测试
-
什么是测试计划?
本文向大家介绍什么是测试计划?相关面试题,主要包含被问及什么是测试计划?时的应答技巧和注意事项,需要的朋友参考一下 软件测试计划就是在软件测试工作正式实施之前明确测试的对象,并且通过对资源、时间、风险、测试范围和预算等方面的综合分析和规划,保证有效的实施软件测试。
-
简单介绍一下tensorflow的计算流图?
本文向大家介绍简单介绍一下tensorflow的计算流图?相关面试题,主要包含被问及简单介绍一下tensorflow的计算流图?时的应答技巧和注意事项,需要的朋友参考一下 答:Tensorflow是一个通过计算图的形式来表述计算的编程系统,计算图也叫数据流图,可以把计算图看做是一种有向图,Tensorflow中的每一个节点都是计算图上的一个Tensor, 也就是张量,而节点之间的边描述了计算之间的
-
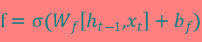 LSTM每个门的计算公式
LSTM每个门的计算公式本文向大家介绍LSTM每个门的计算公式相关面试题,主要包含被问及LSTM每个门的计算公式时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 遗忘门: 输入门: 输出门:
-
卷积池化后大小计算公式?
本文向大家介绍卷积池化后大小计算公式?相关面试题,主要包含被问及卷积池化后大小计算公式?时的应答技巧和注意事项,需要的朋友参考一下 首先我们应该知道卷积或者池化后大小的计算公式: out_height=((input_height - filter_height + padding_top+padding_bottom)/stride_height )+1 out_width=((input_wi
-
海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?
本文向大家介绍海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?相关面试题,主要包含被问及海量数据分布在100台电脑中,想个办法高效统计出这批数据的top10?时的应答技巧和注意事项,需要的朋友参考一下 这种就分为两种情况: 情况1: 情况2:
-
寻找热门查询,300万个查询字符串中统计最热门的10个查询?
本文向大家介绍寻找热门查询,300万个查询字符串中统计最热门的10个查询?相关面试题,主要包含被问及寻找热门查询,300万个查询字符串中统计最热门的10个查询?时的应答技巧和注意事项,需要的朋友参考一下 利用hash映射,将数据映射到小文件中,取1000为例,然后在各个小文件中进行hashmap统计各个串的出现频数,对应进行快排序或者堆排序,找出每个文件中最大频数的,最后将每个文件中最多的取出再进
-
上千万或上亿的数据,统计其出现次数最多的前N个数据?
本文向大家介绍上千万或上亿的数据,统计其出现次数最多的前N个数据?相关面试题,主要包含被问及上千万或上亿的数据,统计其出现次数最多的前N个数据?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析?
本文向大家介绍一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析?相关面试题,主要包含被问及一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析?时的应答技巧和注意事项,需要的朋友参考一下 多层划分(按照bitmap划分)
-
为什么LR用极大似然估计参数?
本文向大家介绍为什么LR用极大似然估计参数?相关面试题,主要包含被问及为什么LR用极大似然估计参数?时的应答技巧和注意事项,需要的朋友参考一下 如果用平方差损失函数时,损失函数对于参数是一个非凸优化的问题,可能会收敛到局部最优解,而且对数似然的概念是使得样本出现的概率最大,采用对数似然梯度更新速度也比较快