《多线程》专题
-
 用Python实现一个简单的多线程TCP服务器的教程
用Python实现一个简单的多线程TCP服务器的教程本文向大家介绍用Python实现一个简单的多线程TCP服务器的教程,包括了用Python实现一个简单的多线程TCP服务器的教程的使用技巧和注意事项,需要的朋友参考一下 最近看《python核心编程》,书中实现了一个简单的1对1的TCPserver,但是在实际使用中1对1的形势明显是不行的,所以研究了一下如何在server端通过启动不同的线程(进程)来实现每个链接一个线程。 其实python在类的
-
Winform基于多线程实现每隔1分钟执行一段代码
本文向大家介绍Winform基于多线程实现每隔1分钟执行一段代码,包括了Winform基于多线程实现每隔1分钟执行一段代码的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Winform基于多线程实现每隔1分钟执行一段代码的方法,分享给大家供大家参考。具体实现方法如下: 1.定义相关的类Timer.cs,代码如下: 2.在主线程部分引用此类。在需要执行的event加入: 希望本文所述对大家的
-
如何最大限度地降低多线程C#代码的复杂性
本文向大家介绍如何最大限度地降低多线程C#代码的复杂性,包括了如何最大限度地降低多线程C#代码的复杂性的使用技巧和注意事项,需要的朋友参考一下 分支或多线程编程是编程时最难最对的事情之一。这是由于它们的并行性质所致,即要求采用与使用单线程的线性编程完全不同的思维模式。对于这个问题,恰当类比就是抛接杂耍表演者,必须在空中抛接多个球,而不要让它们相互干扰。这是一项重大挑战。然而,通过正确的工具和思维模
-
MapFragment-应用程序可能在其主线程上做了太多工作
我有以下错误 关于它的研究。。。确保使用Runnable尽可能多地在新线程中启动所有内容。但不断地出错。我几乎注释了我所有的代码,但在我开始一个新活动时仍然得到了它。然后,我对第一次活动中的这个mapfragment进行了注释,错误就消失了。因此,错误是由以下代码引起的: 我从Android文档的谷歌地图API中得到了这个。。。有点奇怪,它没有得到优化。如何确保错误消失?我可以延迟mapFragm
-
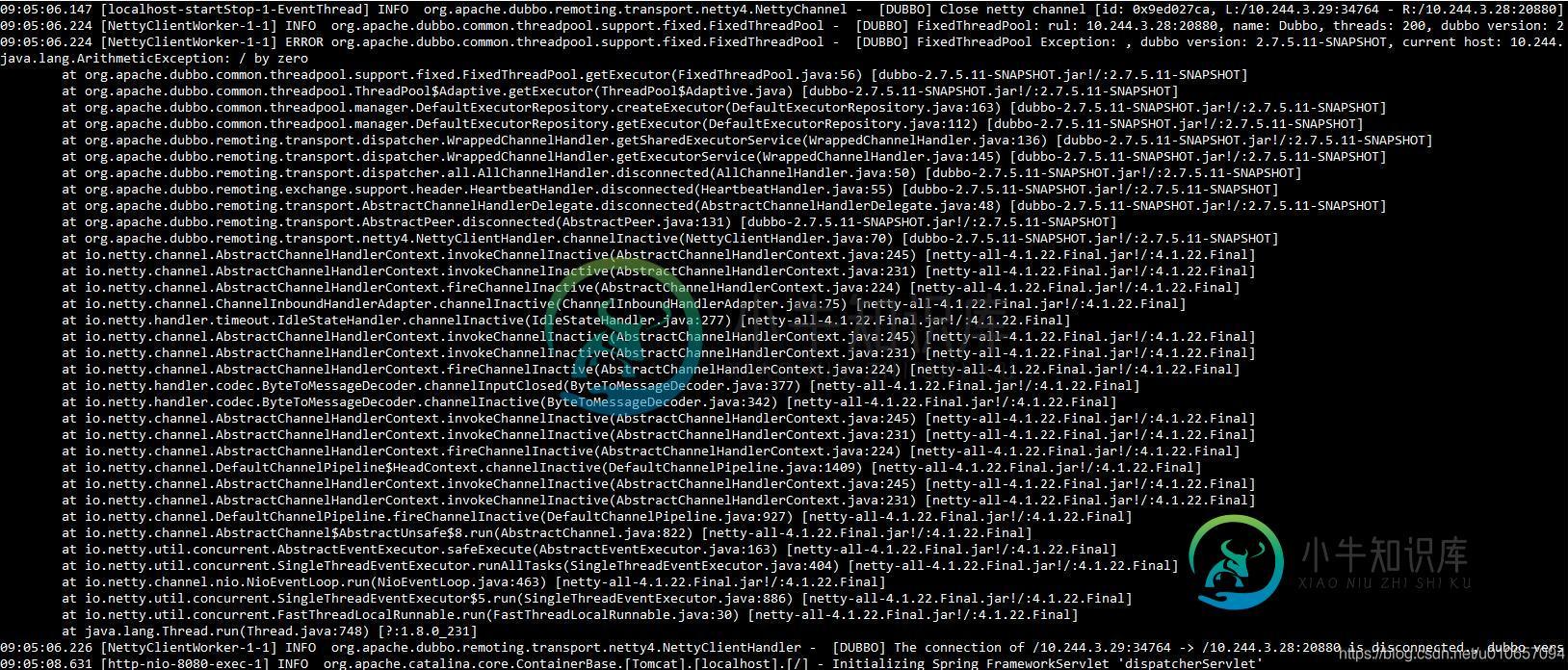 为什么程序中突然多了 200 个 Dubbo-thread 线程的说明
为什么程序中突然多了 200 个 Dubbo-thread 线程的说明本文向大家介绍为什么程序中突然多了 200 个 Dubbo-thread 线程的说明,包括了为什么程序中突然多了 200 个 Dubbo-thread 线程的说明的使用技巧和注意事项,需要的朋友参考一下 背景 在某次查看程序线程堆栈信息时,偶然发现有 200 个 Dubbo-thread 线程,而且大部分都处于 WAITING 状态,如下所示: 为什么会有这么多 Dubbo-thread 线程呢?
-
JMeter:如何在多个线程组循环中重用/重新打开CSV?
在JMeter中,我有一个用户的CSV列表,每个用户都应该上传一定数量的文件。这些文件列在第二个CSV中。每个用户必须上载所有文件。由于服务器不能同时处理所有线程,我将线程组设置为使用X个用户并循环Y次,这样最终所有用户都上传所有文件。 作为一个示例,使用3个线程/用户和2个循环的结果如下所示: 来自第二个循环的用户也应该遍历files-CSV并上传文件。知道我做错了什么吗?提前谢谢!!
-
Python:在两个线程之间共享变量源于多进程。过程
Python 3.1.2 我对多处理产生的两个线程之间的变量共享有问题。过程这是一个简单的bool变量,它应该决定线程是应该运行还是应该停止执行。下面是三种情况下显示的简化代码(但使用与我的原始代码相同的机制): 主要用于Thread加工。Thread类型和自紧度。正在运行布尔类型[工作正常] 我想了解的是为什么它是这样工作的,而不是另一种。(即,为什么第2点没有像我认为的那样起作用)。 测试是从
-
使用任务(TPL)库会使应用程序成为多线程的吗?
最近在接受采访时,我得到了这个问题。 Q: 您编写过多线程应用程序吗? 甲:是的 问:介意解释更多吗? 答:我使用了< code>Tasks(任务并行库)来执行一些任务,比如< code >加载UI时等待来自互联网的一些信息。这提高了我的应用程序的可用性。 问:但是,仅仅您使用了就意味着您编写了应用程序? 我:(不知道该说什么) 那么,究竟什么是多线程应用程序?它与使用不同吗?
-
多线程实际上是并行处理还是只是一种错觉?
因为一次只能运行一条指令,并且假设CPU只运行这个进程。多线程难道不是线程之间快速的上下文切换,给人一种并行处理的错觉,但实际上并不是在处理吗? 那么,既然CPU要执行的指令数是一样的,不管是单线程还是多线程,完成的时间不应该是一样的吗?如果是,说明多线程是并行处理的一种方式不是错的吗?
-
如何在Java中复制/克隆ResultSet中的一行?多线程实现
有什么建议吗? 样品真的很感谢!谢谢!
-
多线程环境集成测试类上使用@Transactional注释的问题
应用程序堆栈:Spring boot 2.1V+测试容器PostgreSQL 1.10.3V+JUnit 4.12V DB testcontainers配置 基本集成测试类 在任何事情发生的地方调用服务的集成测试 逻辑简化的服务
-
应用程序可能在其主线程上做了太多的工作
我是Android SDK/API环境的新手。这是我第一次试着画一张图/图表。我尝试使用3个不同的免费库在模拟器上运行不同类型的示例代码,但布局屏幕上没有显示任何内容。logcat将重复以下消息: 当我运行与一个许可库的评估副本相关的示例代码时,问题并没有持续存在,并且图表工作了。
-
多个线程是否会在受约束集上导致重复更新?
在postgres中,如果我运行以下语句 在默认的 级别中,我可以保证从多个并发会话中: 在单个匹配的情况下,只有1个线程将获得1的ROWCOUNT(意味着只有一个线程写入) 在多匹配的情况下,只有1个线程将获得ROWCOUNT
-
cassandra java驱动程序-高延迟,同时用多线程提取数据
我可以在datastax cassandra driver(3.0)中看到一个奇怪的行为。我创建了一个新集群,然后使用同一个集群对象启动了一组线程。如果我将线程数保持在1或2,我会看到平均提取时间为5ms,但如果我将线程数增加到60,提取时间将增加到200ms(每个线程)。奇怪的是,如果我让60个线程的应用程序运行,并在同一台机器上启动另一个只有1个线程的进程,那么单线程应用程序的提取时间又是5毫
-
Jmeter:如何从多个jmeter从设备中获得合并的线程数
我正在使用jeter分布式环境并在多台从机上分配负载。我正在运行 中,图表仅显示一个从机线程数,而不是x轴上的组合线程数。 例如,如果我的从机1和从机2各运行10个线程,但生成的图表显示X轴上有10个活动线程,但应该是20个。