《长鑫存储面试》专题
-
SQL Server存储过程
SQL Server存储过程将一个或多个Transact-SQL语句分组到逻辑单元中,并作为对象存储在数据库服务器中。 当第一次调用存储过程时,SQL Server会创建执行计划并将其存储在计划缓存中。 在之后的存储过程执行中,SQL Server重用该程序,以便存储过程可以非常快速地执行并具有可靠的性能。 本系列教程将介绍存储过程,并演示如何开发灵活的存储过程以优化数据库访问。 第1节. SQL
-
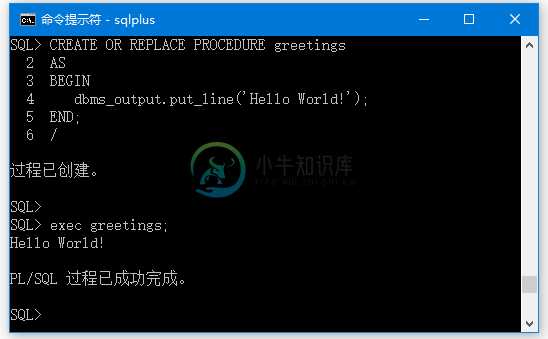 PL/SQL存储过程
PL/SQL存储过程主要内容:PL/SQL子程序的部分,创建存储过程,执行独立程序,删除独立存储过程,PL/SQL子程序中的参数模式,传递参数的方法在本章中,我们将讨论PL/SQL中的存储过程。 子程序是执行特定任务的程序单元/模块。 这些子程序组合起来形成更大的程序。这种做法被称为“模块化设计”。 子程序可以被称为调用程序的另一个子程序或程序调用。 可以在以下几个地方中创建一个子程序 - 在模式(schema)级别中 一个程序包中 在PL/SQL块中 在模式(schema)级别中,子程序是一个独立的子程序。它是使
-
 GitLab导入存储库
GitLab导入存储库在本章中,我们将讨论如何从一个Bitbucket导入一个仓库到GitLab: 步骤(1): 登录到您的GitLab帐户并点击仪表板中的New project按钮: 步骤(2): 单击导入项目选项卡下的按钮: 步骤(3): 接下来,您需要登录到您的帐户。 如果您没有帐户,请点击注册链接创建一个新帐户,然后登录到帐户。 步骤(4): 当点击按钮(如步骤2所示)时,它将显示下面的屏幕并点击授予访问按钮:
-
用Java存储状态
问题内容: 广泛的讨论问题。是否已经有任何库可以让我在Java中存储应用程序的执行状态? 例如,我有一个处理文件的应用程序,现在该应用程序可能在某个时刻被迫关闭。我想存储所有已处理文件和未处理文件的信息,以及处理正在进行的阶段正在进行的流程。 是否已经有抽象此功能的库,或者我将不得不从头开始实现它? 问题答案: 似乎您正在寻找的是可以使用Java Serialization API 执行的序列化。
-
GraphX点切分存储
在第一章分布式图系统中,我们介绍了图存储的两种方式:点分割存储和边分割存储。GraphX借鉴powerGraph,使用的是点分割方式存储图。这种存储方式特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上。 当点被分割到不同机器上时,是相同的镜像,但是有一个点作为主点,其他的点作为虚点,当点的数据发生变化时,先更新主点的数据,然后将所有更新好的数据发送到虚点所在的所有机器,更新虚点
-
存储可变数据
问题内容: 我正在ASP.NET,C#,MVC3和SQL Server 2008中构建应用程序。 将向用户显示一个表单以进行填写(姓名,电子邮件,地址等)。我想允许应用程序的管理员向此表单添加额外的动态问题。 额外问题的数量和返回的数据类型将有所不同。例如,管理员可以添加0、1或多个以下类型的问题: 您是否拥有完整,整洁的驾驶执照? 从1到5对您的驾驶技巧进行评分。 请描述您上一次长途旅行的时间?
-
gradle 添加存储库
本文向大家介绍gradle 添加存储库,包括了gradle 添加存储库的使用技巧和注意事项,需要的朋友参考一下 例子 您必须将Gradle指向插件的位置,以便Gradle可以找到它们。为此添加一个repositories { ... }到您的build.gradle。 这是添加三个存储库(JCenter,Maven存储库和提供Maven样式的依赖关系的自定义存储库)的示例。
-
访问saga存储库
我需要从消费者内部访问saga存储库,以读取与正在消费的消息相关的saga的当前状态。 场景:我有一个外部服务,当这个服务使用来自传奇的事件时,我想看看传奇是否仍然处于正确的状态,因为如果同时传奇改变了状态,消费者必须跳过事件。 如何:我当然可以通过使用它的本机框架来查询选择的saga存储库实现,但是我想使用一个抽象,一个接口,从消费者内部加载saga状态,以便将来能够切换到不同的存储库实现。 感
-
添加Firebase存储桶
更新:在联系了Firebase的支持后,他们告诉我,在修复了他们的后端之后,这个问题确实被修复了。
-
SpringData存储库错误
我对SpringData和JPA有问题。当我向HomeRepository接口添加方法时,我得到一个错误。我使用的是JPararePository接口,在pom.xml文件中有一个MySQL数据库集。这些只是我对spring的开始,所以我需要一些了解spring的人的帮助。下面是我的代码和日志: 主页库: 用户存储库: 日志:
-
Maven到SVN存储库
-
Google云存储传播
谷歌云存储中的文件更改需要多长时间才能传播? 我遇到了一个非常令人沮丧的问题,我改变了一个文件的内容,并通过gsutil重新上传,但是这个改变几个小时后才显示出来。有没有办法强制一个改变的文件立即传播所有内容? 如果我查看谷歌云存储控制台中的文件,它会看到新文件,但如果我点击公共网址,它是旧版本,在某些情况下,是2个版本前的版本。 有没有我没有设置的标题? 编辑: 我尝试了,但它没有帮助,但也许旧
-
在hashmap中存储Arraylist
我正在尝试使用put方法将arraylist存储在hashmap中。我在下一步中清除了列表,以便在下一次迭代中添加下一组值。一旦清除列表,地图中的值也会被清除。虽然我在清理清单之前已经把清单放在地图上了。 sysout打印{key=[]} 有人请让我清楚如何坚持hashmaphash地图。
-
Java包存储位置
我是Java新手,刚刚下载了Eclipse并编写了我的第一个Hello World程序 我想知道包java.util的存储位置是什么?这个包存储在我的电脑上的哪里?我使用苹果电脑。
-
自定义存储库
在我的项目中有几个实体具有相同的属性(对于示例'name'),所以,有可能创建一个存储库,其中使用自定义的select(实体)?因此,我从JpaRepository扩展了我的存储库,我扩展了MyCustomJpaRepository,MyCustomJpaRepository也扩展了JpaRepository,使其能够从JpaRepository授予基本功能? TKS