《江南造船厂》专题
-
使用指南 - 代码安装 - 安装方法
使用指南 - 代码安装 - 安装方法 百度统计的跟踪代码会收集您网站的用户访问数据,并在报告中展示供您查看。当您在账户中添加网站时,百度统计会生成一段带有唯一ID的跟踪代码,您需要将其添加在网站的每个页面中,推荐使用异步代码。注意:代码中的ID是唯一生成的,同一个网站删除后再添加,代码中的ID会变。 安装方法 如何手动安装代码 如何自动安装代码 建站工具中的安装方法 在 AMP 页面中添加百度统计
-
使用指南 - 代码安装 - 代码跟踪
使用指南 - 代码安装 - 代码跟踪 百度统计的跟踪代码会收集您网站的用户访问数据,并在报告中展示供您查看。当您在账户中添加网站时,百度统计会生成一段带有唯一ID的跟踪代码,您需要将其添加在网站的每个页面中,推荐使用异步代码。注意:代码中的ID是唯一生成的,同一个网站删除后再添加,代码中的ID会变。 代码跟踪 百度统计代码介绍 如何获取统计代码
-
一个完整的初学者指南 Django-part2
介绍 欢迎来到 Django 教程的第二部分!在上一课中,我们安装了项目所需要的一切软件,希望你们在学习这篇文章之前,安装了 Python 3.6,并且在虚拟环境中运行Django 1.11。因为,在本篇文章中,我们将继续在这个项目中编写我们的代码。 在这一篇文章中,可能不会有太多的代码操作,主要是讨论分析项目。在下一篇中,我们就开始学习 Django 的基础知识,包括模型(models),管理后
-
一个完整的初学者指南 Django-part1
介绍 今天我将开始一个关于 Django 基础知识的新系列教程。这是一个完整的 Django 初学者指南。材料分为七个部分。我们将从安装,开发环境准备,模型,视图,模板,URL 到更高级主题(如迁移,测试和部署)来探索所有基本概念。 我想做一些不同的事情。一个教程,易于遵循,信息丰富和有趣的阅读。因此我想出了在文章中创建一些漫画的想法来说明一些概念和场景。希望你喜欢这种阅读方式! 但在我们开始之前
-
什么是门罗币?终极入门指南
根据 Monero(门罗) 官网: Monero 是一个安全,隐私和不可追踪的加密货币。通过使用密码学中一种特殊的方法,门罗确保了所有交易保持 100% 的不可关联和不可追溯性(unlinkable and untraceable)。在一个日益透明的世界,你会明白为什么门罗会被人们所期待。通过本文,我们将会看到门罗背后的机制,到底是什么使它如此特别。 起源 2012 年 7 月,Bytecoin
-
Docker用户过渡到kubectl命令行指南
对于没有使用过 kubernetes 的 docker 用户,如何快速掌握 kubectl 命令? 在本文中,我们将向 docker-cli 用户介绍 Kubernetes 命令行如何与 api 进行交互。该命令行工具——kubectl,被设计成 docker-cli 用户所熟悉的样子,但是它们之间又存在一些必要的差异。该文档将向您展示每个 docker 子命令和 kubectl 与其等效的命令。
-
 面向程序员的数据挖掘指南
面向程序员的数据挖掘指南这是一本用于学习基本数据挖掘知识的书籍。大部分关于数据挖掘的书籍都着重于讲解理论知识,难以理解,让人望而却步。不要误会,这些理论知识还是非常重要的。但如果你是一名程序员,想对数据挖掘做一些了解,一定会需要一本面向初学者的入门书籍。这就是撰写本书的初衷。
-
 Google 开源项目风格指南(中文版)
Google 开源项目风格指南(中文版)本项目并非 Google 官方项目, 而是由国内程序员凭热情创建和维护,如果你关注的是 Google 官方英文版,请移步 Google Style Guide。 每个较大的开源项目都有自己的风格指南:关于如何为该项目编写代码的一系列约定 (有时候会比较武断),当所有代码均保持一致的风格, 在理解大型代码库时更为轻松。 “风格” 的含义涵盖范围广,从 “变量使用驼峰格式 (camelCase)” 到
-
 Powershell 攻击指南 黑客后渗透之道
Powershell 攻击指南 黑客后渗透之道一段时间以来研究Powershell,后来应朋友们对 Powershell 的需求,让我写一个Powershell安全入门或者介绍方面的文章,所以这篇文章就出现了。
-
 鲜活的数据数据可视化指南
鲜活的数据数据可视化指南本书是一本系统介绍数据可视化的图书。书中主要阐述了如何将冰冷枯燥的数据转换成易于理解、生动有趣、主题清晰的图表。作者根据数据可视化的一般顺序,先后介绍了如何获取数据,将数据格式化,然后用可视化工具(如R)生成图表,最后在图形处理软件(如 Illustrator)中修改完善,使图表达到最佳的可视化效果。本书详细介绍了柱形图、饼图、折线图和散点图等图表的绘制方法及各自的优缺点,还用专门的一章介绍与地图
-
TCC 理论及设计实现指南介绍
Fescar 0.4.0 版本发布了 TCC 模式,由蚂蚁金服团队贡献,欢迎大家试用, Sample 地址:https://github.com/fescar-group/fescar-samples/tree/master/tcc, 文末也提供了项目后续的 Roadmap,欢迎关注。 一、TCC 简介 在两阶段提交协议(2PC,Two Phase Commitment Protocol)中,资源
-
 河南电信云网运营维护面试
河南电信云网运营维护面试今年各地市的岗都在省公司统一面试。 自我介绍 OSI七层模型 用过哪些linux发行版 国产操作系统有哪些 关系型数据库和非关系型数据库 云计算超算相关
-
 南京亚信科技后端面经(已oc)
南京亚信科技后端面经(已oc)因为楼主是走出国方向的,所以现在这个阶段所有的材料都准备好了,文书也交给中介在准备,已经基本上没啥事了,就想着找个实习做做。昨天面了亚信,下午面完后hr直接微信说通过给offer,我说周五下午给准信(主要是因为我比较想去第一家面的公司,他说周五下午给我通知)虽然亚信点击就送但毕竟是人生第一个实习offer,还是整个面经纪念一下。 雨花台那边的亚信,跟hr约的2点面试,到了之后没想到居然要做题。。。
-
 学前端面产品经理?自埋指南!
学前端面产品经理?自埋指南!1.目标意向是前端开发还是产品经理? 答:产品经理,但我在校主要学习前端开发方面 2.可以随时入职吗? 答:应该是吧!😥 3.实习可以全职是吧 答:论文答辩可能需要回校几天,日常还有网课! 4.你还有什么想了解的吗? 答:想了解一下这个公司😨 在深圳亲戚家(租房)住45天,我都不好意思住下去了,但自己来深圳这么久都没用找到一份工作! 前端知识两天每条代码学习、八股文又忘了! 感觉自己啥都不会?
-
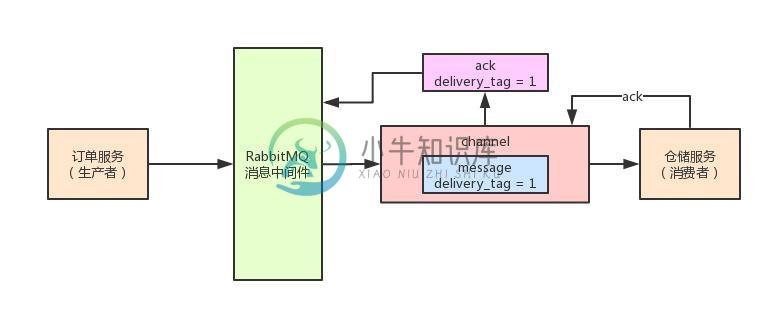 一份透彻的RabbitMQ性能优化指南!
一份透彻的RabbitMQ性能优化指南!主要内容:一、前情提示,二、unack消息的积压问题,三、如何解决unack消息的积压问题,四、高并发场景下的内存溢出问题,五、低吞吐量问题,六、合理的设置prefetch count,七、阶段性总结一、前情提示 这篇文章,我们将会对ack底层的delivery tag机制进行更加深入的分析,让大家理解的更加透彻一些。 面试时,如果被问到消息中间件数据不丢失问题的时候,可以更深入到底层,给面试官进行分析。 二、unack消息的积压问题 首先,我们要给大家介绍一下RabbitMQ的prefetch