《蔚来内推》专题
-
内核栈
内核栈 为什么 / 怎么做 在实现内核栈之前,让我们先检查一下需求和我们的解决办法。 不是每个线程都需要一个独立的内核栈,因为内核栈只会在中断时使用,而中断结束后就不再使用。在只有一个 CPU 的情况下,不会有两个线程同时出现中断,所以我们只需要实现一个共用的内核栈就可以了。 每个线程都需要能够在中断时第一时间找到内核栈的地址。这时,所有通用寄存器的值都无法预知,也无法从某个变量来加载地址。为此,
-
 Spark内核
Spark内核主要内容:spark内核结构:,Spark通用流程spark内核结构: 1、Application 2、spark-submit 3、Driver 4、SparkContext 5、Master 6、Worker 7、Executor 8、Job 9、DAGScheduler 10、TaskScheduler 11、ShuffleMapTask and ResultTask yarn环境: 除了yarn环境外还有k8s和mesos环境 1.sub
-
内存块
简介 内存管理是操作系统内核中最复杂的部分之一(我认为没有之一)。在讲解内核进入点之前的准备工作时,我们在调用 start_kernel 函数前停止了讲解。start_kernel 函数在内核启动第一个 init 进程前初始化了所有的内核特性(包括那些依赖于架构的特性)。你也许还记得在引导时建立了初期页表、识别页表和固定映射页表,但是复杂的内存管理部分还没有开始工作。当 start_kernel
-
代号一个来自互联网来源的圆角图像
但是我似乎不明白为什么在标签上调用也不起作用。
-
来自CV::CalibrateCamera的RVEC/TVEC和来自CV::StereterC整流的R1
相关岗位: 谢谢!
-
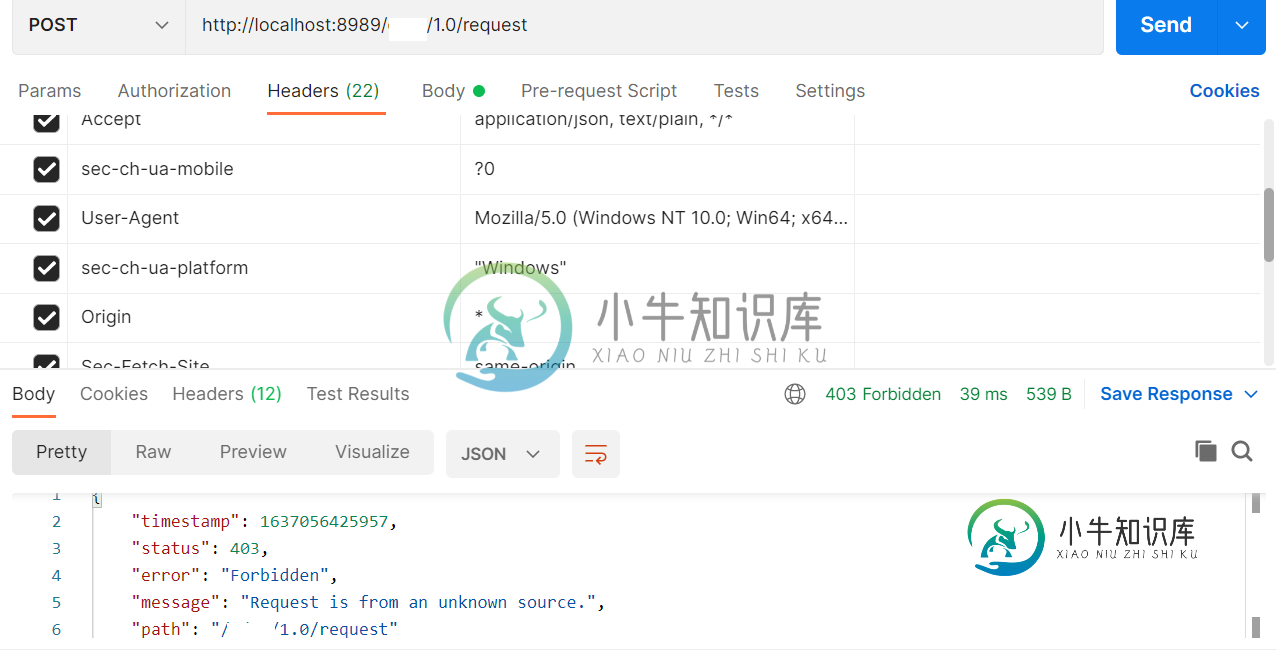 来自邮递员的邮件请求的跨来源问题
来自邮递员的邮件请求的跨来源问题我正在编写一个具有交叉源配置的API 我的websecurity配置有 控制器类 身份验证过滤器检查 匹配。匹配总是变假 我是不是漏掉了什么? 我添加了什么额外的参数吗? 期待着迅速的回应。
-
当收到来自websocket的来电时,如何处理Voip Push?
问题从这里开始,似乎还没有人给出正确的答案。 ================================== 嗨,德夫斯, 我正在开发一个社交网络应用程序,其中包括音频通话功能。我与插座IO网络对话器集成了这个音频呼叫。我通过两种方式接收音频呼叫。连接套接字时的套接字呼叫 仅供参考,为什么我有两种接听电话的方式,如上所述, < li >默认情况下启用VoIP,因为有时套接字调用没有响应,并且
-
 字节面经 都来看 原来hr面才是最难的
字节面经 都来看 原来hr面才是最难的1.自我介绍 基本信息+简历上没有的点,一般是实习的时候负责过哪些项目,怎么策划的,结果怎样,这块在于一定要说和岗位相关的以及自己熟悉的,不熟悉一定不要说。 2.一定要有逻辑性 面试官会问项目或者如何策划以及思路,一定要说第一,第二,第三或者首先其次,最好是每段开始说之前要有总结性语句,例如:我主要负责过**,结果是**,然后再详细说过程。 3.笔试时的错误 这个一定要避免,而且就算发生了也一定要
-
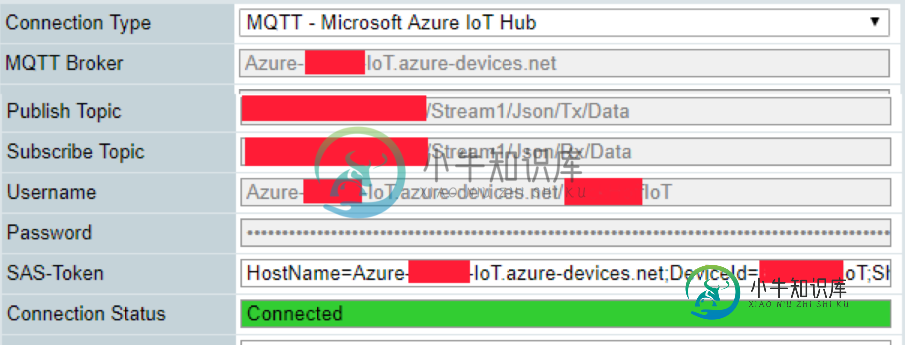 蔚蓝物联网枢纽。云到设备消息(MQTT,自定义主题)
蔚蓝物联网枢纽。云到设备消息(MQTT,自定义主题)蔚蓝物联网枢纽。云到设备消息(MQTT,自定义主题) 我有一个蔚蓝物联网中心。在这里我创建了一个自定义设备。此设备已成功连接到Azure IoT集线器。我也可以从这个设备接收数据(设备到云)。 但我也想给这个设备发个消息。 run.csx
-
如何判断来电是否来自OpenVBX,但仍能看到主叫方的来电显示信息?
我有一个OpenVBX/Twilio设置,在那里我使用它的拨号小程序给我公司的特定人员打电话。然而,当我在电话上查看来电时,我无法知道主叫者是否通过OpenVBX进行呼叫。 有没有一种方法可以定制OpenVBX/Twilio,以便在我的手机上查看主叫用户的来电显示时,我可以看到主叫用户的来电显示信息和一些通过Twilio进行呼叫的指示器?
-
想知道Linux机器上是否有足够的可用内存来部署新应用程序
问题内容: 我有一个Linux机器,在执行/ proc / meminfo时其内存快照为: 这是一台16 GB的计算机,我要在其上部署Java应用程序,它将有3个jvm实例,并且它们的组合典型内存需求将接近1 GB。 我想知道在不影响当前正在该计算机上运行的其他应用程序的情况下部署该应用程序是否安全。通过查看上面的内存快照,我们可以发现吗? 还有哪些其他统计数据可以帮助我决定这一点以及如何收集这些
-
有没有一种内存高效且快速的方法来在python中加载大json文件?
问题内容: 我有一些500MB的json文件。如果我使用“平凡”的json.load一次加载所有内容,它将消耗大量内存。 有没有办法部分读取文件?如果它是文本行分隔文件,则可以在行上进行迭代。我正在寻找一个比喻。 有什么建议?谢谢 问题答案: 更新资料 请参阅其他答案以获取建议。 2010年的原始答案,现在已经过时 简短的回答:不。 正确地分割json文件将需要对json对象图有深入的了解。 但是
-
使用来自A值的数据作为新的键,将内容从HashMap A移动到HashMap B
是否可以使用源映射中的数据使用另一个哈希映射的 KV 对填充哈希映射。例如,让我们假设我们有一张如下所示的地图: 现在考虑 Place 类同时包含字符串和对象。 有没有可能使用一个循环,并使用place-object中的< code>category字符串作为新HashMap的键,将Place对象从positionMap转移到categoryMap中,该HashMap的值将是Places集合?所以
-
直接在Scipy稀疏矩阵上使用Intel MKL库来计算内存较少的A点AT
问题内容: 我想从python调用mkl.mkl_scsrmultcsr。目的是计算压缩的稀疏行格式的稀疏矩阵C。稀疏矩阵C是A和A的转置之间的矩阵乘积,其中A也是csr格式的稀疏矩阵。在计算C =带有scipy的点(AT)时,scipy似乎(?)分配新的内存以保存A(AT)的转置,并且肯定为新的C矩阵分配内存(这意味着我不能使用现有的C矩阵)。因此,我想尝试直接使用mkl c函数来减少内存使用量
-
我可以内省一个变量来直接发现它是用什么子集声明的吗?
有没有一种方法可以内省一个变量,直接找出它是用什么子集声明的?在这里,我创建了一个子集,但内省指出了它的基本类型: 我知道它必须将信息存储在某个地方,因为如果我尝试重新分配与子集不匹配的值,它会失败: 我试着搜索代码,但我很快就找到了像container这样的文件。c和perl6\U操作。c代码让我眼前一亮。我认为X::TypeCheck::Assignment可能会有所帮助(请参见核心/异常.p