《中邮消费金融有限公司》专题
-
 招联金融面试
招联金融面试10月15号一面(20min) 1. 进程和线程 2. 为什么要有线程 3. tcp/ip模型 4. 三次握手过程 5. 输入一个URL的过程 6. jvm的内存结构 7. 元空间会不会溢出 8. 栈放什么东西,会不会溢出 9. 类加载的过程 10. spring aop的原理和应用 11. 接到一个需求是怎么考虑落地的 12. 排名 13. 为什么想来深圳 14. 想不想读博 反问:业务和建议
-
 招联金融 笔试
招联金融 笔试选择题 *20 基本上方方面面都会涉及,比较综合 填空题*10 SQL题 lz的sql题一向很菜,先写后面了 最后回来第一问都没时间写了 C++/Java编程(填空题) *3 第一题好难啊跟线程池具体实现相关 应用题*1 一个场景下给一些建议 逻辑题*40 这个真费时间啊,做完看SQL只有2分钟了 #23届找工作求助阵地# #春招# #招联金融2023春招#
-
 招联金融笔试
招联金融笔试我愿称之为一场神奇的笔试 做完之后我疑惑的打开了它的官网并且确定了我投的岗位是前端 题目类型如下: 选择➕填空➕SQL简答题➕Java/c++二选一代码填空题➕leetcode某贪心算法题➕逻辑题 选择填空就正常的数据库➕操作系统➕机网 废话篇: 首先鼓励一下自己 凭借着我三年来的科班知识磕磕绊绊的编完了很多 然后就是 咱们就是说你要是不想招前端你可以不找 你只出Java c++我也不怪你 但是你
-
没有Spring boot的Spring Kafka消费者不消费消息
消费者使用Spring的JavaConfig类如下: Kafka主题侦听器使用@KafkaListener注释,如下所示: 我的pom包括依赖项: 现在当我打包到war并部署到tomcat时,它不会显示任何错误,即使在调试模式下也不会显示任何错误,只是部署war什么都没有。 请帮助我了解是否缺少触发kafkalistner的某些配置。 谢谢Gary我添加了上下文。xml和web。xml,但我得到了
-
 中讯邮电咨询设计院有限公司-产品经理笔试
中讯邮电咨询设计院有限公司-产品经理笔试刚做完笔试题,虽然投的是产品经理岗位,但是笔试内容包括 行测 英语阅读 计算机专业知识 性格测试 考试时间2个小时。看到计算机专业知识题人麻了,虽然是计算机专业,但我属实很久没复习这些了。似乎考试是按照专业分,不管投递的是否是技术岗位。看来国企笔试不能一概而论啊,除了行测还有很多……应该是凉凉了…… #国企招聘#
-
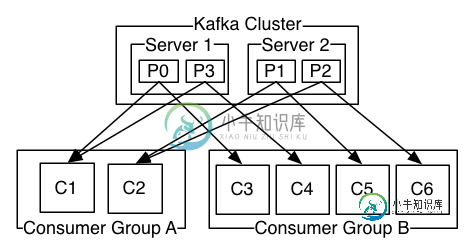 消费者和消费者组有什么关系?
消费者和消费者组有什么关系?本文向大家介绍消费者和消费者组有什么关系?相关面试题,主要包含被问及消费者和消费者组有什么关系?时的应答技巧和注意事项,需要的朋友参考一下 每个消费者从属于消费组。具体关系如下:
-
Kafka消费群体中只有一个消费者的再平衡
当一个组中只有一个消费者,并且认为消费者无法在session.time.out内进行轮询时,将触发重新平衡,但是在这种情况下,组中只有一个消费者,现在假设session.time.out是30秒和消费者民意调查后50秒组协调员将识别消费者后50秒,并允许它提交偏移或协调员将断开消费者和没有偏移得到提交,并将重新平衡消费者与新的消费者标识?如果上次提交的偏移量是345678,在下一次轮询中,它处理了
-
Kafka消费者可以从所有分区消费吗
我有一个多分区主题,由多个使用者(同一组)使用。我的目标是最大化消费处理,即任何消费者都可以消费来自任何分区的消息。 我知道这看起来是不可能的,因为只有一个消费者可以从一个分区中消费。 有没有可能使用REST代理来实现这一点?例如,轮询所有代理消费者实例。 谢了。
-
PayPal金库交易费/收费
我正在使用贝宝保险库服务,从存储的信用卡转移金额到贝宝pro帐户。 下面是我跟踪的文档链接:https://developer.paypal.com/docs/integration/direct/rest-vault-overview。 成功整合后,我已经检查它是收取5.9%的交易费,而我听说贝宝收费只有2.9%的情况下,一个专业帐户。 请确认从信用卡向贝宝帐户转账的贝宝保险库服务的费用。如有任
-
 【2023校招】TCL金融 Java
【2023校招】TCL金融 Java1027 - HR 面 25min 自我介绍 手头 Offer,期望薪资 对 TCL 金融的了解,为什么投 选择公司会考虑什么 若有相同薪资的 Offer,如何选择 实习收获 个人优缺点 反问 1101 - 技术面 35min 自我介绍 个人优势,什么时候开始写博客 MySQL: SQL 性能分析与优化 大数据量如何优化查询(索引,缓存,分库分表) 反范式的优缺点 索引失效的场景,索引建立原则,多
-
 招联金融 Java一面
招联金融 Java一面23.10.21 记错时间导致迟到二十分钟, 但是几十分钟后又重新安排时间开始面试 不太算面经, 因为面试时间太短, 没涉及太多技术 1. 自我介绍 2. 实习经历 3. Spring的IOC和AOP的理解 4. 为什么选择这个企业 5. 反问, 为什么周六面试, 加班情况 想起来再补充吧, 今天没睡好, 记不住了, 也没多少问题
-
Kafka消费者停止消费消息
我有一个简单的Kafka设置。生成器正在以较高的速率向单个分区生成具有单个主题的消息。单个使用者正在使用来自此分区的消息。在此过程中,使用者可能会多次暂停处理消息。停顿可以持续几分钟。生产者停止产生消息后,所有排队的消息都将由使用者处理。生产者产生的消息似乎不会立即被消费者看到。我使用的是Kafka0.10.1.0。这里会发生什么?下面是使用消息的代码部分: 代理上的所有配置都保留为kafka默认
-
Kafka消费者:消费者与消费者的抵消滞后
是否有一种方法以编程方式访问和打印使用者滞后偏移,或者说使用者读取的最后一条记录的偏移与某个生产者写入该使用者分区的最后一条记录的偏移之间的位置差。 要知道我的最终目标是将这个值发送到prometheus进行监视,我应该在上面添加哪些语句来得到滞后偏移值?
-
 金山办公
金山办公一面 10.12 (40min) 1、自我介绍 2、keys命令 3、聚簇索引和非聚簇索引 4、abc联合索引,查c的查找过程(select c from xx where a = 1 and b = 1) 5、找到叶子节点后innodb引擎会做什么,还需要回表么(因为是联合索引,c被覆盖了不需要回表,叶子节点直接拿到) 6、tcp三次握手 7、握手时,客户端不返回ack,不断重新连接,服务端会怎
-
 金山办公
金山办公bg双非本,Java选手,明确需要转码golong,实习ing中投递 笔试:基础题40分,考差的golong,Java技术栈做出来了大部分,算法题三道,60分,ak了,隔天状态变为用人部门筛选,一周约面 服务端一面 近1h 常规八股+八股底层(大概20分钟) 项目理解+sql场景+业务设计(40分钟) 反问流程:3-5天会有结果 面完大概30分钟,电话约了隔天的二面,推掉了 服务端二面 50min