《消息》专题
-
奇怪的崩溃消息“试图取消引用垃圾指针”
我的应用程序是ARC应用程序,但我仍然在崩溃报告中看到多个崩溃,并显示消息“试图取消引用垃圾指针”。它们很难诊断。 我的问题是,为什么应用程序会因为内存问题而崩溃,即使我们在ARC上,并且我们不能用相同的步骤复制它。如何应对此类碰撞? 其中一份事故报告如下: CrashReporterKey:896d0c8676c0e02eb292865a654825359de4d427硬件模型:iPod4,1版
-
 本地化Spring Boot验证消息中未解析消息参数
本地化Spring Boot验证消息中未解析消息参数我正在使用Spring Boot 2.1.8构建一个项目,我的POM中有spring-boot-starter-web,我可以看到Maven将hibernate-validator 6.0.17拉到类路径上。 我在资源文件夹中有我的消息,它们似乎可以正确地查找,这样当我更改区域设置时,Spring就可以从正确的文件中加载消息。 my@RESTController中的相关方法采用@Valid和@Re
-
Python kafka消费者不会使用来自生产者的消息
这是我的消费者: 所以当运行我的制作人时,它最终会出错。任何人都知道这意味着什么,如果这可能是错的。
-
Python Kafka:如何从我停止的地方继续消费消息
我正在使用Kafka python版本2.0.2来生成和消费消息:我的生产者: 我的消费者: 当我运行消费者时,它运行得很好。但是当我在它完成所有消息之前停止它时,它不会从我停止的地方继续,如果我的程序崩溃或笔记本电脑没电了怎么办?我如何解决每个问题?我希望消费者继续阅读未阅读的消息?
-
分区数量超过使用者时的Apache Kafka消息消耗
如果我运行的Kafka集群的分区比我的单个消费者组拥有的消费者还多。对消息的排序或跨分区的消息的按时传递是否有任何保证? 简单示例: 2个分区,1个使用者 生产者通过一个密钥控制分区分配。 消息1进入并转到分区a 消息2进入并转到分区B 消息3进入并转到分区a 我知道消息1将在消息3之前被使用,因为它们在同一个分区中。但是第二条信息呢?是在消息3之前消费还是在消息3之后消费?还是会有变化?它可能在
-
如何利用kafka-node控制已消费kafka消息的提交
我第一次在kafka中使用Node,使用Kafka-Node。使用消息需要调用外部API,这甚至可能需要一秒钟的时间来响应。我希望克服我的消费者的突然失败,这样,如果一个消费者失败了,另一个将替换它的消费者将收到相同的消息,即它的工作没有完成。 我正在使用Kafka0.10并尝试使用ConsumerGroup。 我想到了在options中设置,并且只在消息的工作完成后提交消息(就像我以前对一些Ja
-
Android推送消息问题,旧消息总是在显示屏上
请帮帮我。我被GCM推送消息卡住了。所有的工作都很完美,但当我试图在下一个屏幕上显示我的消息时,我总是得到一个旧的或第一个。但如果我检查我的日志猫,我总是从服务器收到新消息。那我不明白的问题在哪里。我在StackOverflow上尝试了很多代码。这是我的代码片段- 我已经试过了- 这两个对我都不起作用。
-
Apache kafka消费者停止和开始之间丢失的消息
我是一个新的Kafka和使用Apache kafka消费者读取消息从生产者。但当我停下来开始一段时间。之间产生的所有消息都将丢失。如何处理这种情况。我正在使用这些属性“auto.offset.reset”、“latest”和“enable.auto.commit”、“false”。 这是我正在使用的代码。任何帮助都是感激的。
-
Spring中未从消息属性文件中获取验证消息
我昨天让它工作,然后我做了一些事情,现在我一直试图修复它几个小时,我只是无法让它工作了。 我有一个包含
-
如何在discordjs中抓取已发送消息的消息链接?
我不知道如何获取消息的消息链接,discordjs文档似乎没有任何关于消息链接的内容。我试过这个: 但其结果是“行会没有定义”。我这样做对吗?
-
春云啊。成功处理消息后手动删除SQS消息
Spring Cloud AWS(1.0.0.rc2)中SimpleMessageListenerContainer类的当前实现似乎会在消息处理程序完成对消息的处理并且方法调用返回之后自动删除消息。 在我们的应用程序中,在从SQS上游队列删除消息之前,我们需要能够处理消息并等待来自下游队列的异步确认。类似于 接收SQS消息->处理消息->将消息发布到RabbitMQ(线程在此完成) 删除SQS消息
-
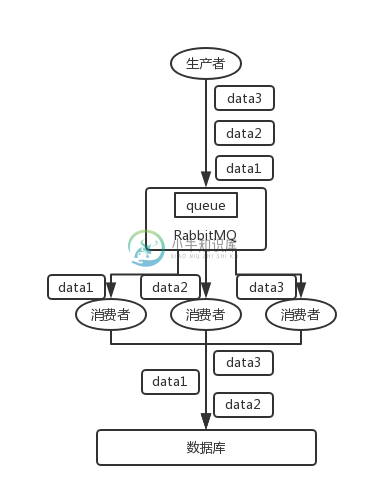 面试-消息队列中,如何保证消息的顺序性
面试-消息队列中,如何保证消息的顺序性主要内容:面试题剖析,解决方案面试题剖析 我举个例子,我们以前做过一个 mysql binlog 同步的系统,压力还是非常大的,日同步数据要达到上亿,就是说数据从一个 mysql 库原封不动地同步到另一个 mysql 库里面去(mysql -> mysql)。常见的一点在于说比如大数据 team,就需要同步一个 mysql 库过来,对公司的业务系统的数据做各种复杂的操作。 你在 mysql 里增删改一条数据,对应出来了增删改
-
Spring云流集成流与Rabbitmq消息传递,消费者提供ASCII号码作为消息有效载荷
我正在使用SpringCloudStream进行消息传递。在消费者部分,我使用IntegrationFlow来监听队列。它正在监听并打印来自制作人的信息。但格式不同,这是我现在面临的问题。生产者的内容类型是application/json,IntegrationFLow消息负载显示ASCII数字。下面给出了为消费者编写的代码 输入接口是, 消费者的yml配置是, 我试过了。类绑定,那一次我从队列中
-
解释段错误消息
问题内容: 以下段错误消息的正确解释是什么? 问题答案: 这是一个段错误,原因是跟随空指针试图查找要运行的代码(即在指令提取期间)。 如果这是一个程序,而不是共享库 运行(并重复给定的其他指令指针值)以查看错误发生的位置。更好的方法是,获得一个带有调试工具的内部版本,并在诸如gdb之类的调试器下重现该问题。 由于是共享库 不幸的是,您被水淹了。事后无法知道动态链接程序将库放置在内存中的位置。重现该
-
Redis Pubsub和消息队列
问题内容: 我的总体问题是: 使用Redis for PubSub,当发布者将消息推送到频道中的速度比订阅者能够阅读它们的速度快时,消息会如何处理? 例如,假设我有: 一个简单的发布者以2 msg / sec的速度发布消息。 一个简单的订户以1 msg / sec的速率读取消息。 我天真的假设是订户只会看到发布到Redis上的消息的50%。为了验证这一理论,我编写了两个脚本: pub.py 子py