《吉利》专题
-
直接流入BigQuery与通过Google发布/订阅数据流流入BigQuery的利弊
我们有一个托管在Google Kubernetes引擎上的NodeJS API,我们想开始将事件记录到BigQuery中。 我可以看到三种不同的方法: 使用API中的节点BigQuery SDK将每个事件直接插入BigQuery(如此处“流式插入示例”下所述):https://cloud.google.com/bigquery/streaming-data-into-bigquery或此处:htt
-
Apache Hadoop纱线-芯线利用不足
无论我如何修改中的设置,即使用以下所有选项 我只是仍然无法让我的应用程序即Spark利用集群上的所有内核。火花执行器似乎正确地占用了所有可用内存,但每个执行器只保留一个内核,仅此而已。 以下是spark defaults中配置的选项。形态 请注意,
-
为什么每个Spark任务都没有利用所有分配的内核?
假设我每个执行器有36个核心,每个节点有一个执行器,以及3个节点,每个节点有48个可用核心。我注意到的基本要点是,当我将每个任务设置为使用1个内核(默认值)时,我对workers的CPU利用率约为70%,每个执行器将同时执行36个任务(正如我所预期的那样)。然而,当我将配置更改为每个任务有6个内核时(conf spark.task.cpus=6),每个执行器一次会减少到6个任务(如预期的那样),但
-
利用java api实现Elasticsearch多条件查询
有多个文档,每个文档包含大约100个字段。我想执行以下搜索槽elasticsearch Java API5.x: 有3个字段我想用于这个搜索,即。
-
使用ES6生成器的redux-saga与使用ES2017 Async/Await的redux-thunk的利弊
现在有很多关于redux镇最新的孩子的讨论,Redux-Saga/Redux-Saga。它使用生成器函数来监听/调度操作。 在仔细考虑它之前,我想知道使用而不是下面使用和Async/await的方法的利弊。 组件可能如下所示,像往常一样分派操作。 然后我的行为如下所示:
-
当内存利用率超过限制时扩展GAE
我正在使用GAE执行高内存需求的繁重任务。我得到了以下错误: 由于任务很昂贵,我假设两个应用程序可以在一个实例中工作。但它不适用于三种应用: 我的当前设置: 我还尝试了以下设置: 执行任务的失败是“超出了软内存限制”。因此,为了解决这个错误,我认为扩展应该基于“内存利用率”而不是“cpu利用率”。 当内存利用率超过限制时,如何进行横向扩展?
-
Azure内存不足,利用率为50%
我遇到了这样一种情况,在我们的Azure应用程序服务中为生成了内存不足异常。Net核心Web API,即使内存 我已经查看了这篇SO文章来检查私有字节和其他东西,但仍然没有看到耗尽的内存来自哪里。我看到内存工作集上的最大使用量为1.5GB,远低于7GB。 支持故障排除下没有显示任何内容- 我不知道下一步该去哪里,任何帮助都将不胜感激。
-
应用服务中的内存利用率是否可以提高
我有一个相当简单的web应用程序,它运行在Azure的应用程序服务计划中,运行在B1服务计划中。此计划提供1个CPU和1.75GB RAM。 CPU使用率永远不会超过5%左右,内存使用率永远不会低于52%。 我确实停止了计划中唯一一个运行的站点,内存使用率没有下降。我创建了一个新的应用程序服务计划,并让它运行了一天,在此期间,内存使用率最低为50%,其中没有运行任何应用程序。 我知道这样做的原因很
-
在Laravel中使用常量利用VS代码中的语法检查的最佳实践是什么?
我知道在Laravel中使用常量的最佳实践中已经发布了很多答案。我来自Java世界,在编辑器中检查常量的有效性。在Laravel中,使用config/constants。php方法, 因此,我们使用Config::get('constants.options.balance_outstanding'))语法引用常量,我似乎无法触发语法检查也无法自动完成。如果我们能把鼠标放在上面,看看常数的真实值是
-
利用kafka和cassandra进行事件来源的类别预测
> 聚合命令处理程序基本上是一个kafka使用者,它使用与某一主题相关的消息: 1.1当它接收到命令时,它会加载聚合的所有事件,并为每个事件重放聚合事件处理程序,以使聚合达到当前状态。 1.2根据命令和businiss逻辑,它将一个或多个事件应用到事件存储区。这涉及到将新事件插入到Cassandra中的事件存储表中。事件被标记为聚合的版本号--对于新的聚合,从版本0开始,这使得预测成为可能。此外,
-
如何利用RSA/ECB/PKCS1Padding算法通过Node.js加密加密字符串
我已经用RSA/ECB/PKCS1padding算法加密了字符串,通过Java代码,现在同样需要用Node.js加密。我不知道如何使用RSA/ECB/PKCS1Padding算法通过Node.js加密。有什么建议吗?Java代码是:
-
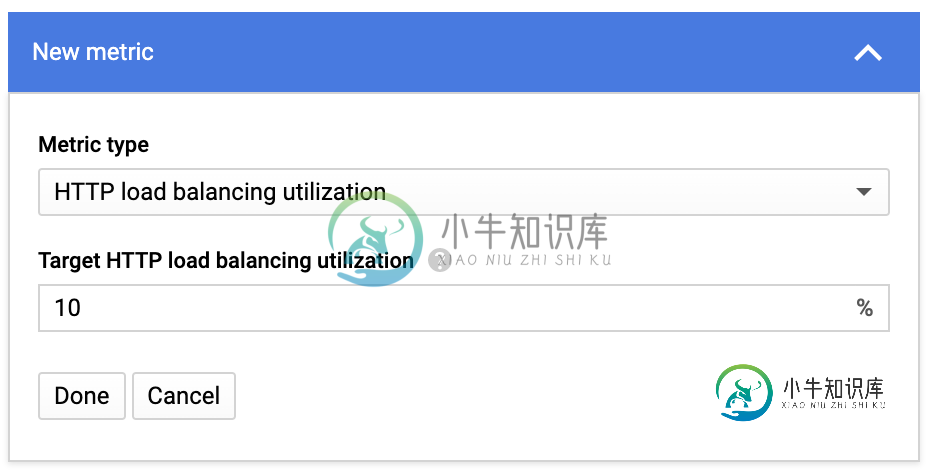 当自动缩放策略设置为目标HTTP负载平衡利用率时,MIG如何自动缩放?
当自动缩放策略设置为目标HTTP负载平衡利用率时,MIG如何自动缩放?我正在学习负载平衡器和托管实例组自动扩展。我不理解MIG在使用HTTP负载平衡利用率时如何自动缩放: 因此,在MIG自动缩放设置中,我将目标HTTP负载平衡利用率设置为10%: 在设置外部HTTP负载平衡器时:我有以下两个选项: 利用: 速率: 我可以理解基于CPU的MIG自动缩放,如果平均CPU使用量大于我输入的数量,那么MIG将添加更多VM以降低数量。它非常简单明了。 但我不知道在使用HTTP
-
如何使一个周期性的背景工作(15分钟的周期性间隔)无限期运行在奥利奥和以后?
使用AlarmManagerApi设置重复警报: 其中getAlarmPendingIntent方法如下所示: 设置一个BroadcastReciever来累加警报:它在前台启动一个服务来完成所需的后台工作 BatteryCheckAsync任务从后台获取电池电量,并在日志中显示当前电池电量。 从https://developer.android.com/training/monitoring-d
-
利用R?
我将一个随机森林模型与R中测试点的表格数据相匹配,现在希望使用与模型中相同预测值(例如坡度、海拔、pH)对应的光栅数据生成一个光栅,显示预测概率值。 RF模型用于使用不同的环境和地球物理数据预测0/1二元变量SITE\u NONSITE。 dcc。s、 假人包括以下数据: 然后,我在整个研究区域内获取与这些相同预测值对应的光栅,并将它们组合成光栅堆栈: 但是,尝试在光栅::predict()中使用
-
什么时候应采用流而不是传统循环来获得最佳性能?流是否利用分支预测?
问题内容: 我刚刚阅读了有关Branch-Prediction的文章,并想尝试一下Java 8 Streams的工作原理。 但是,Streams的性能总是比传统循环差。 输出: 对于排序数组: Branch Statement Time : 272992442 ns, (0.272992 sec) Streams Time : 806579913 ns, (0.806580 sec) Parall