《运筹优化》专题
-
基于条件优化算法的任务分配与调度
我需要找到一个合适的方法来开发一个优化算法,它做以下工作: 假设我们有N个任务要做,我们有M个房间,每个房间都包含一些特定数量的基础设施/条件。每项任务都要求使用条件适合任务的房间。 例如,为了完成任务,我们需要使用水龙头和煤气管道,所以我们只能使用包含这些管道的房间。 此外,对于每项任务,我们都有一个预定义的截止日期。 我希望我已经解释得够清楚了。 所以,我需要开发一种算法,可以在适当的时间安排
-
Dijkstra最小堆算法的时间复杂度及其优化
Dijkstra算法的这种特殊实现的时间复杂度是多少? 我知道这个问题的几个答案是,当你使用最小堆时,O(E log V),这篇文章和这篇文章也是如此。然而,这里的文章说的是O(V ElogE),它的逻辑与下面的代码类似(但不完全相同)。 算法的不同实现可以改变时间复杂度,我试图分析下面实现的复杂性,但是像检查和忽略中的重复顶点这样的优化让我怀疑自己。 以下是伪代码: 笔记: 从源顶点可到达的每个
-
编译器能优化出两个原子负载吗?[副本]
和是使用同一原子变量的两个加载的两个场景。编译器可以将两个加载的场景折叠为一个加载并重用它吗?
-
为什么优化内联函数比普通函数容易?
我正在阅读每个程序员都应该知道的内存https://people.freebsd.org/~lstewart/articles/cpumemory.pdf,它说内联函数使你的代码更可优化 例如 :特别是函数的内联允许编译器一次优化更大的代码块,这反过来又可以生成机器代码,从而更好地利用处理器的管道架构。 and: 当程序的较大部分可以被视为单个单元时,代码和数据的处理(通过死代码消除或值范围传播等
-
使用 AspectJ Spring优化更改返回值的类型 [重复]
我想完成从控制器收到的JSON响应,例如添加一个状态属性。在这方面,我将使用Aspect类,它的@Around方法返回一个自定义类对象。在这种情况下,我得到一个错误: 有没有办法通过aspectJ注释@Around将@ResponseBody类型中的返回更改为自定义类型?我不能更改控制器代码! 控制器类: 方面类: 自定义类别响应:
-
Hadoop / MapReduce - 优化“前 N”字数列表映射减少作业
我正在做一些类似于标准MapReduce示例的事情——字数统计,但是有所改变,我只希望得到前N个结果。 假设我在HDFS有一个非常大的文本数据集。有大量的例子展示了如何构建一个Hadoop MapReduce作业,为你提供文本中每个单词的字数。例如,如果我的语料库是: “这是对测试数据的检验,也是检验这一点的好方法” 来自标准 MapReduce 字数统计作业的结果集为: 测试:3、a:2、thi
-
使用GLSurfaceview进行媒体编解码和渲染,优化OnDrawFrame
我正在使用媒体编解码器编码帧来自相机和渲染它使用gl表面视图。 这里我们做了两次Draw(surface),这两次将呈现到surface。这会造成系统开销。有没有什么地方我可以只做一次?两次使用着色器是昂贵的操作,有没有办法我们可以共享表面之间的渲染和编码器?
-
为我的Java棋盘游戏优化我的“捕获”算法
棋盘游戏是一个11x11矩阵 ex)白板左边的白板,然后黑板直接移动到白板的右边,这将是一个捕获 到目前为止,我有一个 11 x 11矩阵 (int)0=空,1=白,2=黑,3=白 到目前为止,我的算法是基本的,检查上/下/左/右,如果是对立面,然后检查旁边的那块是否是友好的,如果是,那么抓取。 但我不能简单地这么做,因为如果工件位于两个边缘外的行或列上,使用上述算法,我会得到一个ArrayOut
-
优化内存密集型数据流管道的GCP成本
我们希望提高在GCP数据流中运行特定Apache Beam管道(Python SDK)的成本。 我们已经构建了一个内存密集型Apache Beam管道,这需要在每个执行器上运行大约8.5 GB的内存。一个大型机器学习模型目前加载在转换方法中,因此我们可以为数百万用户预先计算建议。 现有的GCP计算引擎机器类型的内存/vCPU比率低于我们的要求(每个vCPU高达8GB RAM)或更高的比例(每个vC
-
 针对相同颜色的大面积优化图像模糊
针对相同颜色的大面积优化图像模糊我正在努力为一个实心(但不是矩形)对象生成一个投影。输入是表示对象不透明度的灰度图像。然后,我想模糊它,给它上色,然后在物体后面画它。 最常见的情况是,这张图像将具有相同色调的大连续区域,这意味着如果我使用标准模糊算法,我将浪费图像绝大多数的周期。考虑下面的输入和输出: 所有的模糊工作都需要在边缘进行,但是在大平面区域上的工作只是浪费了,并且代表了90%以上的像素。 有没有比模糊任意输入图像更快的
-
使用lambda比较初始化优先级队列的方法
我试图初始化一个自定义优先级队列,它作为成员对象存在于类中。它接受一个元组并使用lambda函数作为比较器。 我尝试了一些不同的方法来设置这个问题,但似乎在不同的协议下都失败了, 在我拥有的文件: 这给了: 错误:“”不是类型 如果我只是做
-
从模板化堆继承的模板化优先级队列
我试图为我的编程类写一个优先级队列,但继续得到以下错误:PriorityQueue.cpp: 7:1:错误:“PriorityQueue::PriorityQueue”命名构造函数,而不是类型PriorityQueue.cpp: 7:1:错误:和PriorityQueue没有模板构造函数 我已经做了几个小时了,不知道出了什么问题。以下是它所指的代码:
-
x86-64汇编对齐和分支预测的性能优化
我目前正在编写一些C99标准库字符串函数的高度优化版本,如< code>strlen()、< code>memset()等,使用带有SSE-2指令的x86-64汇编。 到目前为止,我已经设法在性能方面取得了出色的成绩,但是当我试图进一步优化时,我有时会遇到奇怪的行为。 例如,添加甚至删除一些简单的指令,或者简单地重组一些与跳转一起使用的本地标签会完全降低整体性能。而且在代码方面绝对没有理由。 所以
-
查找字符串中的所有字母表如何优化
给定一个字符串s和一个非空字符串p,在s中找到p的字母表的所有起始索引。 null
-
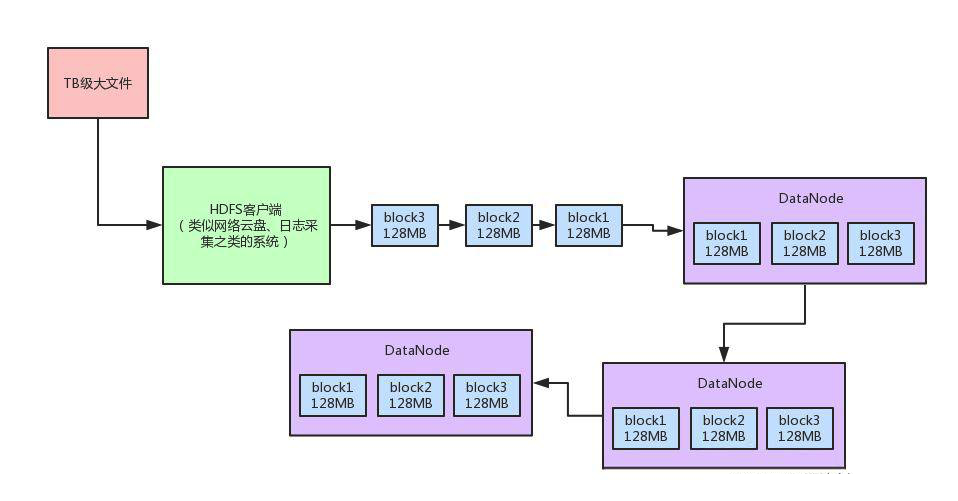 关于超大数据量的系统性能优化设计
关于超大数据量的系统性能优化设计主要内容:1、Chunk缓冲机制,2、Packet数据包机制,3、内存队列异步发送机制,总结:这篇文章,我们来聊一聊在十亿级的大数据量技术挑战下,世界上最优秀的大数据系统之一的Hadoop是如何将系统性能提升数十倍的? 首先一起来画个图,回顾一下Hadoop HDFS中的超大数据文件上传的原理。 其实说出来也很简单,比如有个十亿数据量级的超大数据文件,可能都达到TB级了,此时这个文件实在是太大了。 此时,HDFS客户端会给拆成很多block,一个block就128MB。 这个HDFS客户端