《运筹优化》专题
-
优化器optimizers
优化器是编译Keras模型必要的两个参数之一 from keras import optimizers model = Sequential() model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,))) model.add(Activation('tanh')) model.add(Activation('soft
-
优化器optimizers
优化器是编译Keras模型必要的两个参数之一 model = Sequential() model.add(Dense(64, init='uniform', input_dim=10)) model.add(Activation('tanh')) model.add(Activation('softmax')) sgd = SGD(lr=0.01, decay=1e-6, momentum=0
-
3.7.3 OPPO 优化
给 OPPO 手机做的优化 该优化代码只在 Cocos2d-x 3.17.2 及以上的版本起效,并且目前只在 OPPO Reno 有效果。 具体优化方案 引擎内部在两个地方添加了优化代码: 场景加载 编译引擎内置的 shader 脚本 场景加载指的是从 Scene 创建到 Scene::onEnter() 被调用这段时间,所以加载资源的代码要放在 Scene::onEnter() 前,且需要在 S
-
性能优化
imi 为性能做了以下努力: 框架核心运行时缓存 项目运行时缓存 热更新重启采用增量方式 数据库 Statement 复用 减少不必要的注入处理 使用框架核心运行时缓存+热更新重启采用增量方式,我们的实际项目原本重启需要 6 秒,现在只需几毫秒,提升可谓是巨大的。 使用项目运行时缓存后,每次启动和热重启worker进程时,硬盘读写压力不再巨大。 我们将持续为性能优化,为可靠性优化。 上面提到的框架
-
优化建议
架构及开发过程优化建议: 路由尽量使用域名路由或者路由分组; 在路由中进行验证和权限判断; 合理规划数据表字段类型及索引; 结合业务逻辑使用数据缓存,减少数据库压力; 在应用完成部署之后,建议对应用进行相关优化,包括: 如果开发过程中开启了调试模式的话,关闭调试模式(参考调试模式); 通过命令行生成类库映射文件; 通过命令行生成配置缓存文件; 生成数据表字段缓存文件;
-
优化缓存
When users hit the URL of your application they will need to download different assets. CSS, JavaScript, HTML, images and fonts. The great thing about Webpack is that you can stop thinking how you sho
-
优化开发
We talked about how you could use the minified versions of your dependencies in development to make the rebundling go as fast as possible. Let us look at a small helper you can implement to make this
-
算法优化
将浮点转成定点运算,就一个目的,减少算法运算的 cycles 数,提高算法的效率。
-
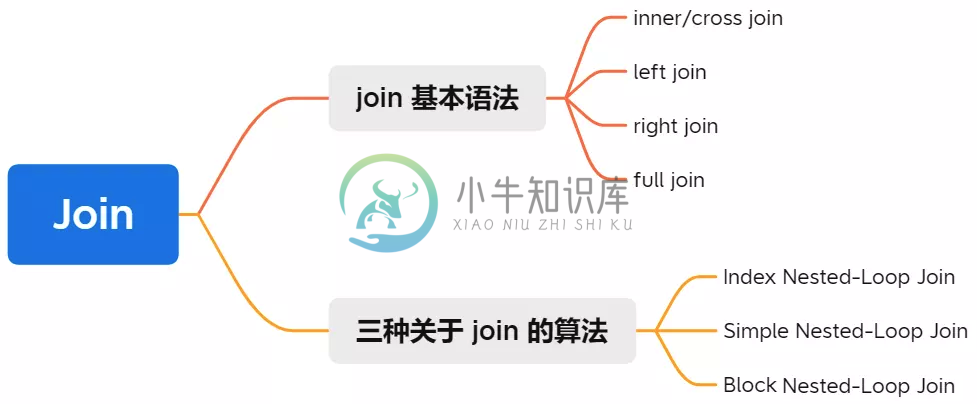 Sql优化-Join
Sql优化-Join主要内容:1.join 基本语法,2.inner join,3.left join,4.right join,5.full join,6.针对 join 语句该如何建立索引、如何选择驱动表,7.Index Nested-Loop Join,8.Simple Nested-Loop Join,9.Block Nested-Loop Join,10总结1.join 基本语法 inner join:内连接(等值连接) left join:左连接 right join:右连接 2.inner join
-
 Sql优化-2
Sql优化-2主要内容:1.用连接查询代替子查询,2.join的表不宜过多,3.join时要注意,4.控制索引的数量,5.选择合理的字段类型,6.提升group by的效率,7.索引优化1.用连接查询代替子查询 mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。 子查询 子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。 子查询比较简单和结构化,但是如果涉及的数量比较多的话不
-
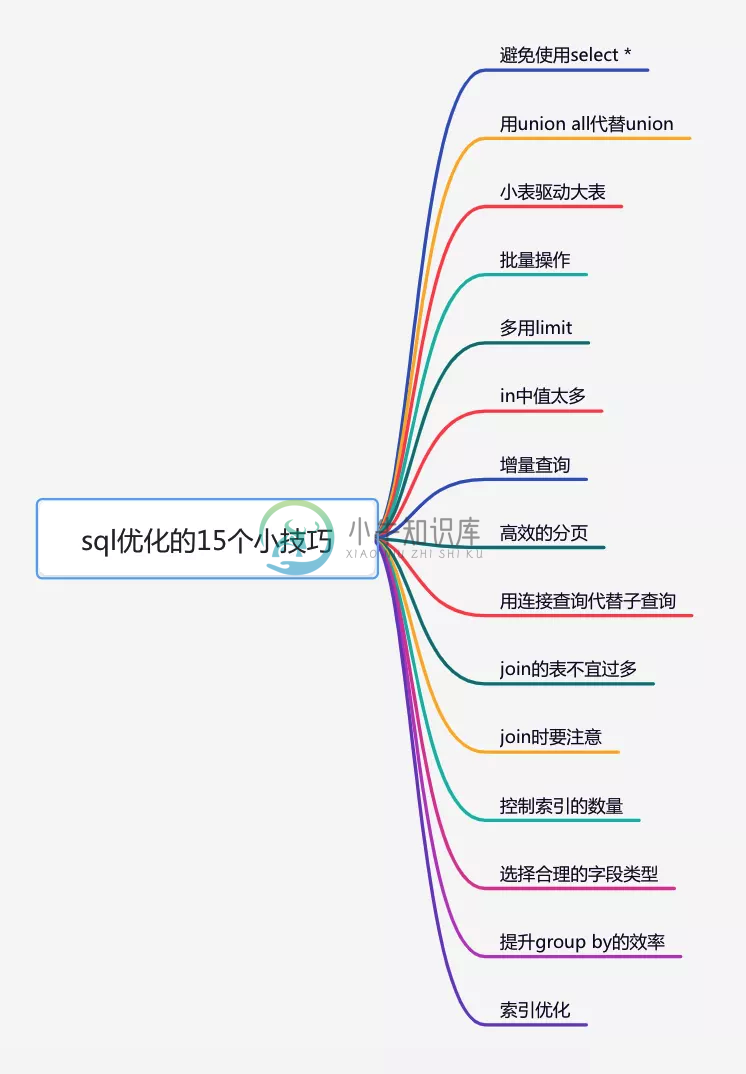 Sql优化-1
Sql优化-1主要内容:1.避免使用select *,2.用union all代替union,3.小表驱动大表,4.批量操作,5.多用limit,6.in内东西过多,7.增量查询,8.高效的分页1.避免使用select * 因为select * 查出来的数据是全部的数据,需要的数据包含其中,但是也有不需要的数据,效率低 select*不走索引,会出现大量的回表操作,而从导致查询sql的性能很低。 sql语句查询时,只查需要用到的列,多余的列根本无需查出来。 2.用union all代替union sql语句使
-
算法优化
将浮点转成定点运算,就一个目的,减少算法运算的 cycles 数,提高算法的效率。
-
java - Java优化?
在完成一个模块后,应该从那几个方面对代码进行优化,有哪些方法可以进行优化
-
createElement优于innerHTML的优势?
问题内容: 在实践中,相比于innerHTML,使用createElement有什么优势?我之所以问是因为,我坚信使用innerHTML在性能和代码可读性/可维护性方面会更加有效,但是我的团队成员已经决定使用createElement作为编码方法。我只是想了解createElement如何更有效。 问题答案: 除了安全之外,使用其他方法还具有一些优点,而不是修改(而不是仅仅丢弃已有的内容并替换它)
-
字符串的plus运算符的线程安全性,包括优化
问题内容: 这篇文章说,相当于 假设我有以下代码: 假设beginmt在MultiThreading类的单个实例上同时运行多次(线程号为1至15500)。是否可能存在这样的实例,它可以打印以下内容,即某些线程号丢失并且某些数字加倍? 编辑: 可以肯定地说+运算符不会引起某些不安全的发布问题吗?我认为StringBuilder可以优化为类似于实例变量的东西,在这种情况下,它可能会不安全地发布。 编辑