《索引》专题
-
Git索引
Git索引是一个在你的工作目录和项目仓库间的暂存区(staging area). 有了它, 你可以把许多内容的修改一起提交(commit). 如果你创建了一个提交(commit), 那么提交的是当前索引(index)里的内容, 而不是工作目录中的内容. 查看索引 使用 git status 命令是查看索引内容的最简单办法. 你运行 git status命令, 就可以看到: 哪些文件被暂存了(就是在
-
索引量
什么是站点索引量 站点中有多少页面可以作为搜索候选结果,就是一个网站的索引量。 站点内容页面需要经过搜索引擎的抓取和层层筛选后,方可在搜索结果中展现给用户。页面通过系统筛选,并被作为搜索候选结果的过程,即为建立索引。 目前site语法的数值是索引量估算值,比较不准。推荐站长们使用我们的新工具,同时我们也正在努力改进site语法。 如何使用百度索引量工具 第一步,注册并登录百度搜索资源平台
-
API 索引
Api文档使用Swagger工具生成,具体请前往API文档查看。
-
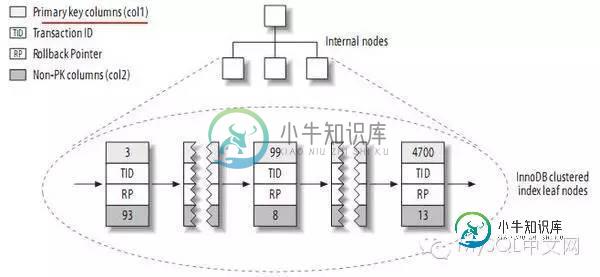 MySQL索引之聚集索引介绍
MySQL索引之聚集索引介绍本文向大家介绍MySQL索引之聚集索引介绍,包括了MySQL索引之聚集索引介绍的使用技巧和注意事项,需要的朋友参考一下 在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别? 在MySQL中,InnoDB引擎表是(聚集)索引组织表(clustered index organize table),而MyISAM引擎表则是堆组织表(heap organize table)。 也有人把聚集索引
-
查询中的弹性搜索索引
我刚加入弹性搜索公司。而不知道如何在JSON请求中对索引和an类型发出正确的请求?(所以我不想像localhost:9200/myindex/mytype/_search那样在URL中使用索引和类型,而是向localhost:9200/_search发出JSON请求) 我试过这样的东西。但我得到的结果是'AAA'索引而不是'BBB'索引。如何只从bbb索引得到结果或者根本没有结果?
-
弹性搜索索引随机变空
ElasticSearch索引会随机变空,但大多数情况下,它发生在部署用Rails构建的应用程序之后。 以下是有关ElastiSearch的一些信息: curl-xget“http://localhost:9200/_nodes?pretty” curl-xget“http://localhost:9200/_cluster/health?pretty” curl“localhost:9200/_
-
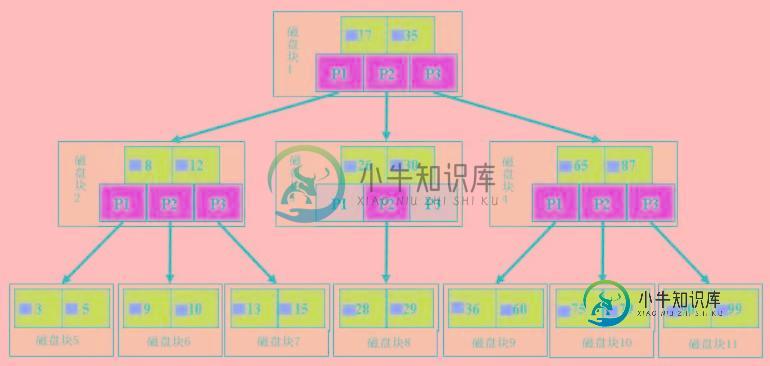 MySQL btree索引与hash索引区别
MySQL btree索引与hash索引区别本文向大家介绍MySQL btree索引与hash索引区别,包括了MySQL btree索引与hash索引区别的使用技巧和注意事项,需要的朋友参考一下 在MySQL中,大多数索引(如 PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)都是在BTREE中存储,但使用memory引擎可以选择BTREE索引或者HASH索引,两种不同类型的索引各自有其不同的使用范围。 B树索引具有范围查
-
在SQL Server索引中搜索单词
问题内容: 我需要在全文搜索和索引搜索之间进行操作: 我想在表的一列中搜索文本(如果很重要的话,该列上也可能会有一个索引)。 问题是,我想搜索列中的单词,但是我不想匹配部分。 例如,我的列中可能包含公司名称: Mighty Muck Miller and Partners Inc. Boy&Butter Breakfast company 现在,如果我搜索“ Miller ”,我想找到第一行。但是
-
弹性搜索-优先排序索引
假设我有三个指数:城市、博物馆和景点。 现在我正在查询一个术语的所有索引(),例如“维也纳” 作为结果,我得到: 维也纳:维也纳艺术博物馆 有没有办法优先考虑指数,这样我就可以得到第一个城市,而不是景点,最后是博物馆,就像这样: 维也纳 维也纳的Riesenrad 维也纳:维也纳艺术博物馆 维也纳:维也纳历史博物馆
-
跨多个索引的Elasticsearch搜索-忽略不存在的索引
问题内容: 我有弹性簇,其中我的索引包含当前日期-例如: 是否可以跨多个索引查询,而忽略不存在的索引。例如,这 WORKS : 而这 会返回404 : 我希望第二个示例仅从25日起返回文档。 问题答案: 如果您使用通配符,则无需担心,ES会找出匹配的索引。 如果您真的想枚举索引,可以在调用中指定: 或者,您也可以使用索引别名并仅查询该别名。在创建新索引时,您还将该别名添加到索引中。这样做的好处是您
-
在跨多个索引进行搜索时,如何在搜索结果中获取索引名称?
当跨多个索引进行搜索时,elasticsearch的“多重匹配”查询将返回搜索结果中的索引名称。 响应包含字段,该字段告诉结果来自的索引 spring-data-elasticsearch中用于的类是和具有字段、、用于获取与elasticsearch查询相似的数据。但它不包含用于存储字段信息的相关字段。 还支持吗?我需要根据哪个客户端应用程序将生成一些URL发送搜索命中类型(name)。 这是我使
-
Python支持多索引检查索引值
我试图比较两个数据帧的差异,使用一个公共键/索引值,该值由帧中的3列组成。 e、 g.假设两列中的列都是:“COL1”、“COL2”、“COL3”、“COL4” 数据帧是df1 然后,我使用了set_index方法: 然后我想遍历df1数据帧,并检查df2数据帧是否有匹配的索引。我尝试过使用以下方法: 但是它返回false(尽管我可以通过打印看到两者的索引都存在)。 我做错了什么? 另外,如何使用
-
Spring弹性搜索重新索引方法
我编写了一个reindex方法,可以执行以下操作: 它确实起到了作用,但我现在确定,仅仅删除然后创建一个索引是否有意义。如何改进此方法?
-
Sitecore Lucene搜索索引和子文件夹
注意: 我只使用“luceneresults”.ascx和.cs。 ----问题更新了,因为我缩小了问题的范围---- 我试图创建一组特定项的索引,用于Lucene搜索。 在web.config中,我指定了一个索引,该索引包含: 完整索引:
-
Liferay 7.3.5GA6自定义索引搜索和ddmFieldArray
我正在尝试使用SearchContext、IndexSearcherHelperUtil和所有其他东西,为Liferay 7.3.5 GA6开发一个定制的web内容搜索portlet。 我有一些不同字段的DDM结构,从我在elasticsearch索引上看到的,这些字段在嵌套文档中被索引,如下所示: 这与我以前知道的旧方法不同,在旧方法中,自定义字段被索引为 现在我明白了 以下是代码: 这仍然是一