《索引》专题
-
MySQL索引和顺序
问题内容: 这是我永远遇到的一个问题。 据我所知,索引的顺序很重要。因此,类似的索引与 并不相同,对吧? 如果我仅定义第一个索引,是否意味着它将仅用于 而不是 由于我使用的是ORM,所以我不知道这些列的调用顺序。这是否意味着我必须在所有排列上添加索引?如果我有2列索引,那是可行的,但是如果我的索引是3列或4列怎么办? 问题答案: 当查询条件仅适用于 部分 索引时,索引顺序很重要。考虑: 如果你的索
-
索引布尔字段
问题内容: 这可能是一个非常愚蠢的问题,但是对数据库表中的布尔字段建立索引是否会有很多好处? 在常见情况下,例如标记为“无效”的“软删除”记录,因此大多数查询都包含,这将有助于对该字段进行单独索引,还是应将其与其他常见搜索字段组合在一起?不同的索引? 问题答案: 没有。 您可以对要搜索的字段具有较高的选择性/基数进行索引。几乎所有表都消除了布尔字段的基数。如果有的话,它将使您的写入速度变慢(降低的
-
PHP未定义索引
问题内容: 这听起来真的很愚蠢,但我无法弄清楚为什么会收到此错误。 我创建了一个选择框,以我的html形式命名为“ query_age”: 在相应的php形式中,我有: 运行页面时,出现此错误: 注意:未定义的索引:第19行的index.php中的query_age 我不明白为什么会这样,我很想知道如何解决它。 问题答案: 我没有看到php文件,但是可能就是这样- 在您的php文件中替换: 与:
-
负面清单索引?
问题内容: 我正在尝试理解以下代码: 具体来说,我不明白索引所指的是什么。如果索引指向第一个元素,那么它指的是什么? 问题答案: 负数表示您是从右数而不是从左数。因此,指的是最后一个元素,是倒数第二个,依此类推。
-
JSON上的PostgreSQL索引
问题内容: 我想使用Postgres 9.4 在json列上创建一个索引,该索引将在搜索列中的特定键时使用。 例如,我有一个带有json列“ animals”的“农场”表。 animals列具有通用格式的json对象: 我已经尝试了多个索引(分别): 我想运行如下查询: 并让该查询使用索引。 当我运行此查询时: 那么(1)索引就可以了,但是我无法获得任何索引来解决不平等问题。 这样的索引可能吗?
-
索引= FieldIndexOption.No与OptOut = true?
问题内容: 之间有什么区别 和 根据这里的回答,据说没有索引属性。我以为正在这样做。 问题答案: 为了便于说明,请考虑以下类: 当您索引class的对象时,field的值将被完全忽略。简而言之,Elasticsearch不了解该领域。它只是供您的客户端应用程序使用,可能用于某些簿记目的。类型的映射定义如下: 请注意该字段存在。如果标记为,则无法在该字段中搜索值,但是可以在搜索请求的匹配文档中检索其
-
ElasticSearch索引问题TransportSerializationException
问题内容: 我正在尝试为Elasticsearch中的一些文档建立索引并出现一些错误。但是我不知道原因,所以我无法解决它。错误如下: 什么会导致此错误?感谢帮助。 问题答案: 如果您的Elasticsearch服务器和索引应用程序正在运行不同的计算机,并且这些计算机包含不同的jvm版本,则可能会出现此问题。您必须安装相同的Java版本。希望能帮助到你。
-
MySQL Integer与DateTime索引
问题内容: 首先,我已经看过很多类似的问题,但是所有这些问题都与字段类型有关,而没有索引。至少那是我的理解。 众所周知,DateTime具有某些优势。把它们放在一边了一分钟,并假设表的引擎是用,它查询将更快地执行时标准基于: 带索引的DateTime 带索引的int 换句话说,最好将日期和时间存储为?或UNIX时间戳。请记住,不需要使用任何内置的MySQL函数。 更新资料 使用MySQL 5.1.
-
MySQL varchar索引长度
问题内容: 我有一张这样的桌子: 和这样的一个: 和这样的SQL语句 如果我解释给我这个: 对于一百万行,这非常慢。我尝试使用以下方法在products.name上添加索引: 这给出了: 我认为Sub_part列显示已在索引中(以字节为单位)的前缀,如本页中所述。 当我重新解释查询时,我得到: 看起来好像没有使用新索引。如 本页所述,如果索引是前缀索引,则不会用于排序。实际上,如果我用以下方法截断
-
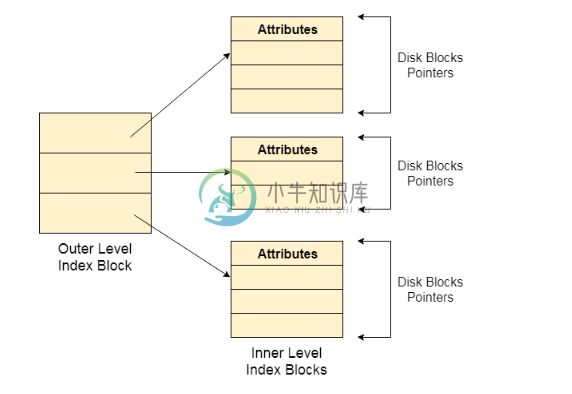 链接索引分配
链接索引分配主要内容:多级索引分配单级链接索引分配 在索引分配中,文件大小取决于磁盘块的大小。 要允许大文件,我们必须将几个索引块链接在一起。在链接索引分配中, 提供文件名称的小标题 前100个块地址的集合 指向另一个索引块的指针 对于较大的文件,索引块的最后一个条目是一个指向另一个索引块的指针。 这也被称为链接模式。 优点: 它消除了文件大小限制 缺点: 随机访问变得有点困难 多级索引分配 在多级指数分配中,有各种索引级别。 有
-
Python Pandas分层索引
主要内容:创建分层索引,应用分层索引,分层索引切片取值,聚合函数应用,局部索引,行索引层转换为列索引,列索引实现分层,交换层和层排序分层索引(Multiple Index)是 Pandas 中非常重要的索引类型,它指的是在一个轴上拥有多个(即两个以上)索引层数,这使得我们可以用低维度的结构来处理更高维的数据。比如,当想要处理三维及以上的高维数据时,就需要用到分层索引。 分层索引的目的是用低维度的结构(Series 或者 DataFrame)更好地处理高维数据。通过分层索引,我们可以像处理二维数据
-
Pandas index操作索引
主要内容:创建索引,设置索引,重置索引索引(index)是 Pandas 的重要工具,通过索引可以从 DataFame 中选择特定的行数和列数,这种选择数据的方式称为“子集选择”。 在 Pandas 中,索引值也被称为标签(label),它在 Jupyter 笔记本中以粗体字进行显示。索引可以加快数据访问的速度,它就好比数据的书签,通过它可以实现数据的快速查找。 创建索引 通过示例对 index 索引做进一步讲解。下面创建一个带有 i
-
Pandas reindex重置索引
主要内容:重置行列标签,填充元素值,限制填充行数,重命名标签重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。 重置行列标签 看一组简单示例: 输出结果: 现有 a、b 两个 DataFrame 对象,如果想让 a 的行
-
Numpy索引和切片
主要内容:基本切片,多维数组切片在 NumPy 中,如果想要访问,或修改数组中的元素,您可以采用索引或切片的方式,比如使用从 0 开始的索引依次访问数组中的元素,这与 Python 的 list 列表是相同的。 NumPy 提供了多种类型的索引方式,常用方式有两种:基本切片与高级索引。本节重点讲解基本切片。 基本切片 NumPy 内置函数 slice() 可以用来构造切片对象,该函数需要传递三个参数值分别是 start(起始索引
-
输出变鼠索引
这是一个按照字母顺序排序的,Autoconf将在它所创建的文件(通常是一个或更多'Makefile') 中进行替换的变鼠的列表。关于这些是如何实现的,请参见 设定输出变鼠 。 a ALLOCA AWK b bindir build build_alias build_cpu build_os build_vendor c CC, CC, CC CFLAGS, CFLAGS configure_in