《全文检索》专题
-
composer文件中的Docker健康检查
问题是,我的数据库容器需要比启动我的主应用程序的容器更多的时间来启动和初始化数据库。结果:主容器无法正确启动,导致缺少数据库连接。我编写了一个healthcheck.sh脚本来检查数据库容器的连通性,因此主容器在连通性可用后开始引导。但我不知道如何在Dockerfile和我的docker-compose.yml中正确地集成它 healthcheck.sh类似于: mysql容器DockerFile
-
检查Java中损坏的JPEG文件
我需要一个快速的Java方法来检查JPEG文件是否有效,或者它是否是一个被截断/损坏的图像。 我试着用几种方法: > 使用javax.imageio库 我正在寻找一个Java替代UNIX程序jpeginfo,它大约快10倍(在我的PC上,大约10个图像/秒)。
-
如何使用POP3检索gmail子文件夹/标签?
问题内容: 下面的代码使用javamail API访问gmail, 问题在于此代码仅列出了INBOX文件夹,而定义的标签不少于20个。如何使代码列出/访问这些嵌套的文件夹/标签,该怎么做? 问题答案: 不要使用POP,如果需要标签/文件夹,请使用IMAP。 如javamail docs 中所述,由于POP协议的性质,POP消息存储区始终 仅包含一个文件夹“ INBOX”。
-
MySQL / SQL检索文本字段的前40个字符?
问题内容: 如何从mysql db表中检索文本字段,而不是整个文本,仅检索40个左右的字符。 可以在sql中完成此操作,还是需要使用php完成? 基本上我想做的是显示前x个字符,然后让用户单击以查看全部内容。 问题答案: 参见功能。 根据 经验 ,您永远不应该在PHP中做MySQL可以为您做的事情。这样想:您不希望从数据库向请求的应用程序传输超出严格必要的内容。 编辑 如果 要经常使用 同一页面上
-
Java 如何通过SFTP从服务器检索文件?
问题内容: 我正在尝试使用Java从使用SFTP(而不是FTPS)的服务器检索文件。我怎样才能做到这一点? 问题答案: 另一个选择是考虑查看JSch库。JSch似乎是一些大型开源项目的首选库,其中包括Eclipse,Ant和Apache Commons HttpClient。 它很好地支持用户/通过和基于证书的登录,以及所有其他许多美味的SSH2功能。 这是通过SFTP检索的简单远程文件。错误处理
-
如何在JavaFX中检索文本字段的内容?
本文向大家介绍如何在JavaFX中检索文本字段的内容?,包括了如何在JavaFX中检索文本字段的内容?的使用技巧和注意事项,需要的朋友参考一下 文本字段接受并显示文本。在最新版本的JavaFX中,它仅接受一行。在JavaFX中,javafx.scene.control.TextField类表示文本字段,该类继承javafx.scene.control.TextInputControl (所有文本控
-
如何使用mongodb聚合和检索整个文档
我对mongoDB的聚合函数感到非常困惑。我只想在我的收藏中找到最新的文档。假设每个记录都有一个“创建”的字段 产生正确的结果,但我希望结果中包含整个文档?我将如何做到这一点? 这是文档的结构:
-
Mongoose findOne方法检索丢失_id的有效文档
我目前在一个非常奇怪的猫鼬错误,我不知道是什么导致了这个问题。当我调用方法时,我得到一个有效的实例,只有字段未初始化。当我试图保存文档中的更改时,它会崩溃 我有一个简单的模式定义: 当我打电话给你 Mongoose返回文档,但只有未初始化。当我试图保存修改过的文档时,整个函数崩溃,而不是在此之前。我还将该文档记录到控制台,以验证是否缺少了“\u id”字段。 注意,是从另一个查询中提取的,是一个有
-
使用tweepy for python按时间顺序检索推文
我编写了一个Python脚本,将每条推文中的6个URL上传到Twitter。我使用API调用来拉下所有发布的帖子,有效地缩短了我发布到twitters t.co URL的URL。 我的问题是调用没有按时间顺序排列tweet。 在Twitter时间线中,最新的tweet发布在顶部。如果我能从底部读回时间线,我会更喜欢它,这是我第一条推文的开始。 这是我用来从推特上检索我时间轴上推文的代码: 有人知道
-
在索引之前检查Elasticsearch文档的相似性
问题内容: 好了,在整日努力梳理头发之后,我决定从社区中获取一些建议。 应该提到的是,我对Elasticsearch还是相当陌生。 我的想法是,我有一个包含一些文档的ES索引,并且仅当尚未索引具有相似字段内容(但不一定等于)的现有文档时,才需要索引新文档。 我可以在多个字段上执行匹配查询并获得查询的全局分数,但是由于该分数不是可用最大分数的百分比,因此我不确定如何设置阈值来确定是否可以插入文档。
-
如何检索[]符文的第一个“完整”字符?
我在试着写一个函数 匿名的名字。下面是一些输入和输出对的示例,让您了解它应该做什么: 该函数应该适用于由任意字符组成的名称。在实现此功能时,我有以下问题: 给定一个或,我如何计算出我必须使用多少个符文才能获得一个完整的字符,完整的意思是与该字符对应的所有修饰符和组合重音也被使用。例如,如果输入是(对应于字符串BC,其中δ表示为A和组合diaresis的组合),该函数应该返回2,因为前两个符文会产生
-
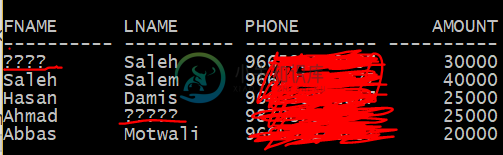 在Oracle 12C上插入/检索阿拉伯文数据
在Oracle 12C上插入/检索阿拉伯文数据我正面临着从Oracle数据库12c获取阿拉伯语内容的问题,我已经回答了大多数问题,但没有任何问题与我一起工作。 我的阿拉伯字符返回如下“?????” 即使在java上,当我获得数据时,它也不会返回阿拉伯值 windows 10笔记本电脑(使用windows 10管理用户登录) Oracle 12C(使用系统用户登录) Java版本“1.8.0_152” 我在这里和网上找到了很多问题,比如: 无法
-
从boto3检索S3 bucket中的子文件夹名称
使用boto3,我可以访问我的AWS S3桶: 您可以看到,检索了特定的文件,在本例中是,而我只想获取目录的名称。原则上,我可以从所有路径中删除目录名,但在第三级检索所有内容以获得第二级是丑陋和昂贵的! 我也尝试了这里报道的一些东西: 但是我没有得到所需级别的文件夹。
-
Apache Camel FTP获取无法检索文件:RemoteFile错误
我正在尝试使用Camel FTP组件(Camel 2.19.0)检索文件: 从跟踪日志中,我可以看到Camel正在正确地列出目录中的文件: 但是,当Camel试图处理每个文件时,它似乎将相对目录预置到绝对目录,并且无法找到结果的乱码路径: FTPComponent构造的日志中的此路径不正确:
-
通过驱动器Api检索文件资源列表
我正在使用Drive api从Google Drive检索文件列表,使用以下Java代码: 使用getAlternateLink方法,我得到了这个URL。 我的问题是如何编写一个代码来获取'/spreadsheet'位置,而不是URL中的'/file'。即-