《缓存》专题
-
UIWebView离线缓存
实现UIWebView页面离线缓存功能。作者QQ:867187831
-
Redis中的Azure缓存/数据缓存样式区域
问题内容: 我正在计划将C#ASP.Net Web应用程序移到Azure(当前托管在单个专用服务器上)的过程中,并且正在研究缓存选项。当前,因为我们一次只能运行一个应用程序实例,所以我们有一个“进程中”内存缓存来缓解SQL DB的某些相同请求。 当前的过程是在管理器/服务对数据库的那些部分进行更改时清除缓存的某些部分,例如,我们有一个用户表,并且我们将拥有诸如“ User。{0}”之类的键,返回一
-
Nginx作为缓存代理不缓存任何内容
问题内容: 我正在尝试缓存静态内容,这些内容基本上位于虚拟服务器配置中的以下路径内。由于某些原因,文件没有被缓存。我在缓存目录中看到了几个文件夹和文件,但总是像20mb一样高或低。例如,如果要缓存图像,则将至少占用500mb的空间。 这是nginx.conf缓存部分: 这是默认的虚拟服务器。 问题答案: 确保您的后端不返回标头。如果Nginx看到它,它将禁用缓存。 如果是这种情况,最好的选择是修复
-
二级缓存 - 同步本地和分布式缓存
我们可以通过下面的简单算法实现该目的: 检查本地缓存的键(key); 如果本地缓存存在该键,则返回它的值; 如果本地缓存不存在该键,则尝试在分布式缓存中找; 如果分布式缓存存在该键,则返回它的值并把它添加到本地缓存; 如果分布式缓存不存在该键,则从数据库中获取,并添加到本地和分布式缓存,最后返回该值。 当在本地缓存服务器中缓存一些信息时,使用这种方式,它还将信息缓存到分布式缓存,但这一次,如果其他
-
本地缓存 - 用户简介(User Profile)缓存示例
假设我们网站有一个使用多个查询生成的简介页面。我们有此页的模型,如 UserProfile 类,它包含用户所有简介数据,及一个获取指定用户 id 简介的 GetProfile 方法。 public class UserProfile { public string Name { get; set; } public List<CachedFriend> Friends { get;
-
说一下 MyBatis 的一级缓存和二级缓存?
本文向大家介绍说一下 MyBatis 的一级缓存和二级缓存?相关面试题,主要包含被问及说一下 MyBatis 的一级缓存和二级缓存?时的应答技巧和注意事项,需要的朋友参考一下 一级缓存:基于 PerpetualCache 的 HashMap 本地缓存,它的声明周期是和 SQLSession 一致的,有多个 SQLSession 或者分布式的环境中数据库操作,可能会出现脏数据。当 Session f
-
使用Spring缓存抽象的异步缓存更新
使用Spring的缓存抽象,如何让缓存异步刷新条目,同时仍返回旧条目? 我试图使用Spring的缓存抽象来创建一个缓存系统,在相对较短的“软”超时之后,缓存条目可以刷新。然后,当查询它们时,返回缓存的值,并启动异步更新操作来刷新条目。我也会 Guava的缓存生成器允许我指定缓存中的条目应该在一定时间后刷新。然后可以用异步实现覆盖缓存加载器的reload()方法,允许返回陈旧的缓存值,直到检索到新值
-
从BigQuery-Dataflow Python Streaming SDK缓慢更改查找缓存
查找缓存的引用表位于BigQuery中,我们可以读取它并将其作为ParDo操作的侧输入传入,但无论我们如何设置触发器/窗口,它都不会刷新。 根据这里的I/O页面(https://beam.apache.org/documentation/io/build-in/),它说Python SDK只支持BigQuery接收器的流,这是否意味着BQ读取是一个有界源,因此不能在此方法中刷新? 试图在源上设置非
-
二级逐出时从一级缓存逐出缓存
我有一个关于内存系统遵循的策略的基本问题。 考虑一个具有私有L1和L2缓存的核心。在L2缓存之后,我们有一个相干流量运行的总线。现在,如果从L2高速缓存中逐出地址(X)的高速缓存行,是否有必要从L1高速缓存中逐出该地址?? 逐出的原因可能是它有助于保持一致性协议的不变[如果l2中的一行显示无效,则此核心不包含此地址]。
-
System.out是缓冲还是未缓冲?
问题内容: 是缓冲还是无缓冲? 我读到这是的对象,并且是所引用的对象的类型。 而且它们都是Unbuffered的,所以为什么要刷新unbuffered …是否可以刷新unbuffered,我已经读过它们被立即写入。 问题答案: 是“标准”输出。在大多数操作系统上,终端io被缓冲,并且支持分页。 在Javadoc中, “标准”输出流。该流已经打开并且准备接受输出数据。通常,此流对应于主机环境或用户指
-
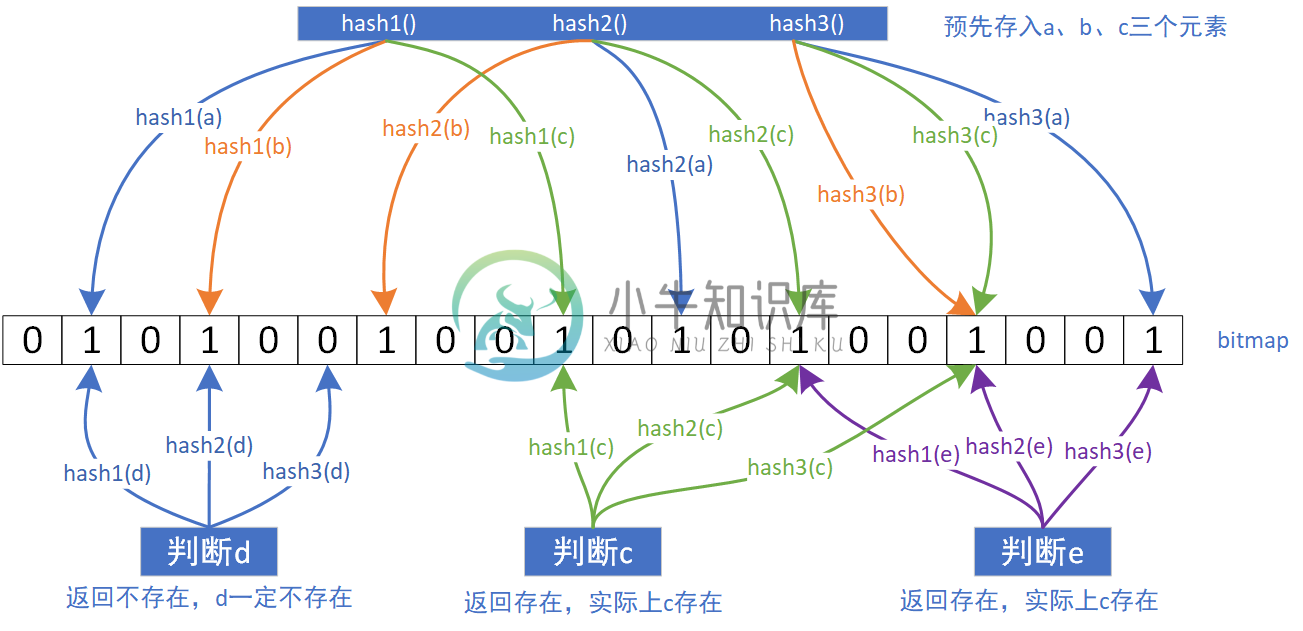 Redis的缓存穿透、缓存雪崩、缓存击穿问题的概念与解决办法
Redis的缓存穿透、缓存雪崩、缓存击穿问题的概念与解决办法主要内容:1 缓存穿透,1.1 什么是缓存穿透?,1.2 怎么解决,1.3 Bloom Filter布隆过滤器,2 缓存雪崩,3 缓存击穿,4 缓存预热,5 防止Redis宕机详细介绍了Redis的缓存穿透、缓存雪崩、缓存击穿等问题的概念与解决办法。 1 缓存穿透 1.1 什么是缓存穿透? 缓存穿透是指查询一个在缓存和数据库中一定不存在的数据,按照传统使用缓存流程:由于缓存不命中,接着查询数据库,但是数据库也无法查询出结果,因此也不会将空值写入到缓存中,这将会导致每个这样的查询都会去请求数据库,
-
Buffer (缓冲)
稳定性: 2 - 稳定的 在 ECMAScript 2015 (ES6) 引入 TypedArray 之前,JavaScript 语言没有读取或操作二进制数据流的机制。 Buffer 类被引入作为 Node.js API 的一部分,使其可以在 TCP 流或文件系统操作等场景中处理二进制数据流。 TypedArray 现已被添加进 ES6 中,Buffer 类以一种更优化、更适合 Node.js 用
-
10 缓冲
生活和艺术一样,最美的永远是曲线。 -- 爱德华布尔沃 - 利顿 在第九章“图层时间”中,我们讨论了动画时间和CAMediaTiming协议。现在我们来看一下另一个和时间相关的机制--所谓的缓冲。Core Animation使用缓冲来使动画移动更平滑更自然,而不是看起来的那种机械和人工,在这一章我们将要研究如何对你的动画控制和自定义缓冲曲线。
-
Buffer(缓冲)
正如我们先前所指出的,网络数据的基本单位永远是 byte(字节)。Java NIO 提供 ByteBuffer 作为字节的容器,但它的作用太有限,也没有进行优化。使用ByteBuffer通常是一件繁琐而又复杂的事。 幸运的是,Netty提供了一个强大的缓冲实现类用来表示字节序列以及帮助你操作字节和自定义的POJO。这个新的缓冲类,ByteBuf,效率与JDK的ByteBuffer相当。设计Byte
-
6.4.4 缓冲
6.4.4 缓冲 当一个人饿了,面对一大碗饭,他该怎么吃呢?任务的目标是将这一碗饭送到肚子里去, 解决饿的问题,而达成目标的最快方法是将一碗饭一口吞下,可惜没人有这么大的嘴。事实 上,人们采取的是每次吃一口的方式,一口一口地将饭吃到肚子里去。这个例子很好地说明 了计算机解决问题时的“缓冲”技术。 利用计算机解决问题时,经常需要将大量数据从一个地方传送到另一个地方,并且一次 性地传送所有数据会遇到种