《数据分析科学实习》专题
-
 上海银行-数据分析应用岗 一面
上海银行-数据分析应用岗 一面原定14.30进场(14.37才进。。。) 1. 自我介绍2min 2. 上一段实习都做了什么 3 4问的两个实习项目用到的算法 5. hive sql 区别 6. hive底层原理知道吗(不知道) 7. Python数据处理用啥包 8. 实习算法实现是调包还是(当然是调包呀😬) 8. 反问 出面试间的时间倒是贼准😅。。。(14.50) 呜呜呜可能是对我不感兴趣?别人问20min为啥俺就13m
-
 深圳联通-大数据分析-一面二面
深圳联通-大数据分析-一面二面一面 10.12 10min 一个面试官,主要挖简历。 好长时间没消息我都以为g了,又收到了二面通知 二面 10.31 10min 一个面试官,挖简历+期望薪资+家是哪的,为啥来深圳等 一面面试官有点丧丧的,感觉好困好困。二面的面试官很和蔼,戴口罩也能看出来全程笑嘻嘻的。 不知道是不是KPI,有没有后续。 #广东联通##深圳联通##面试#
-
 滴滴-国际化部门数据分析-凉经
滴滴-国际化部门数据分析-凉经写在前面:jd只写了滴滴国际化部门招实习生,并不知道是数分,所以答得稀烂,很多数理统计知识都忘光了。。。。 一、自我介绍 1、上一段实习中主要使用到的数据分析工具,是否会建模进行数据分析 2、在上一段实习中觉得自己做的最好的一个case 二、概率统计部分: 1、z检验和t检验分别是什么 2、大数定律和中心极限定理的内容和条件 3、假设检验的原理,两类错误分别是什么,之间的关系,怎样使两类错误的概率
-
 tplink 大数据分析工程师 春招面经
tplink 大数据分析工程师 春招面经- 3/9笔试 - 选择题大概三四十个 - 问答题10个,涉及python,HSFS八股,Java八股 - 3/14一面,全是快问快答25min - 问简历,项目介绍,项目中提到的模型被揪出来问了细节 - 常见的机器学习算法讲讲,深度学习会多少呢? - 编程语言?希望会Java - 各种排序算法,时间复杂度,随便介绍几个呗 - Python的装饰器 - 指针和引用的区别(这是C++,但是当时并不知
-
 中信银行-数据挖掘分析岗一面
中信银行-数据挖掘分析岗一面提问: 自我介绍 介绍一下你简历上的项目? 除了这个还做过其他的项目吗? 有没有参加过建模比赛? 对机器学习有了解吗? 总结: 面试官看起来是人事部门的,不像是技术人员,都没怎么问技术,很快就结束了。 心态上凑合,没上次那么紧张了。 老毛病又犯了呀我真的,跟对面那姐姐聊的太诚实了,机器学习那里我跟人说没怎么用过,回想起来就应该说一直有学习,也了解过,我真的悔死。虽然我也说了几种有监督和无监督的算法
-
 青岛芯恩数据分析面试(一二面)
青岛芯恩数据分析面试(一二面)第一面上来说我简历写的太简洁不知道该问什么,直接开始问虚拟机系统和数据库系统的问题,幸好早有准备。问题主要两个方面,虚拟机和数据库:首先是虚拟机,这个主要问各种命令:如何创建新的用户,如何创建逻辑卷;如何查看内存情况,如何查看虚拟机进程等。数据库方面也是基础知识,什么叫索引,如何创建索引,索引和自增ID的区别等。 、半小时后通知下午还有二面 第二面纯纯的HR面试啊,自我介绍,问我为什么选择芯恩?为
-
 OPPO数据分析师 GPT等AI技术洞察
OPPO数据分析师 GPT等AI技术洞察共34min 两个面试官,一个应该是业务负责人,另一个是懂技术的~ 首先一来就是自我介绍,然后他们详细地介绍了该岗位干嘛的。 首先深挖了一个实习项目,问了一些项目的具体细节,然后还有我主要负责的部分。 然后问我了不了解爬虫,我说学过但是用的不多。(谢谢MKT3310) 问我平时数据分析工具,我说Mysql python R。 最后问了一个开放性的问题:GPT怎么对人们的生活、工作产生积极影响? 真
-
 字节跳动-Data-数据分析三面面经
字节跳动-Data-数据分析三面面经大家好,我是乐乐,我是一个23fall的校招生,上岸后来回馈社会啦~ 这次分享的是我面试“字节跳动-Data-数据分析-抖音/剪映/电商/直播”的第三轮面试面经和经验,供后续的同学们参考呀,具体面经看图片哦~,更多信息资料可看xhs,同名可关注哦~ 面试总结 1. 难度:⭐⭐⭐⭐⭐ - 感受:感觉自己像在面试数据分析,又感觉自己好像在面试产品。同时,面试官给人有种深不可测的感觉。 - 评价:这次面
-
 面经|武汉兴盛优选数据分析岗
面经|武汉兴盛优选数据分析岗1.离职原因、离职时间点 2.上一份工作所在的部门、小组、小组人员数、小组内的分工 3.个人负责的目标,具体是哪方面的成本 4.为了降低专员成本,做了哪些方面的工作 偏向于机制、分析方法、思维,当下主要是对于部分高收入专员收入不合理的情况进行分析,可能是作弊、单价等,怎么去识别,识别到之后怎么去处理 (1)高收入人群识别(2)拆分高收入原因(3)线下排查这种是否正常 5.针对怎么识别高收入原因,怎
-
 字节跳动-Data-数据分析二面面经
字节跳动-Data-数据分析二面面经大家好,我是乐乐,我是一个23fall的校招生,上岸后来回馈社会啦~ 这次分享的是我面试“字节跳动-Data-数据分析-抖音/剪映/电商/直播”的第二轮面试面经和经验,供后续的同学们参考呀,具体面经看图片哦~,更多信息资料可看xhs,同名可关注哦~ 面试总结 1. 难度:⭐⭐⭐⭐⭐ - 感受:说实话我有被紧张到,面试结束的那天晚上没有睡好,因为自己是有可能被挂的。 - 评价:从整体上看,这次面试是
-
 招联金融数据分析师春招面试
招联金融数据分析师春招面试3月底做的笔试,4月初通知面试,笔试是20道统计学题目和30道行测题目,比较简单 一面属于半结构化面试,用时30min,我对Hadoop和数据仓库不甚了解,寄 自我介绍、项目简述、职业规划 如何向缺乏专业数学知识的普通人介绍正态分布 逻辑回归模型的原理和优缺点,gbdt的优缺点,gbdt和xgb的区别 是否熟悉Hadoop、数据仓库,目前处理过最大的数据量是多少 列举SQL的窗口函数,如何提高SQ
-
 字节跳动-Data-数据分析一面面经
字节跳动-Data-数据分析一面面经大家好,我是乐乐,我是一个23fall的校招生,上岸后来回馈社会啦~ 这次分享的是我面试“字节跳动-Data-数据分析-抖音/剪映/电商/直播”的第一轮面试面经和经验,供后续的同学们参考呀,具体面经看图片哦~,更多信息资料可看xhs,同名可关注哦~ 面试总结 1. 难度:⭐⭐⭐⭐ - 感受:不得不说,23fall的字节跳动Data-数据分析在一面就已经面到这种级别的程度,已经是完全超出了我的预期,
-
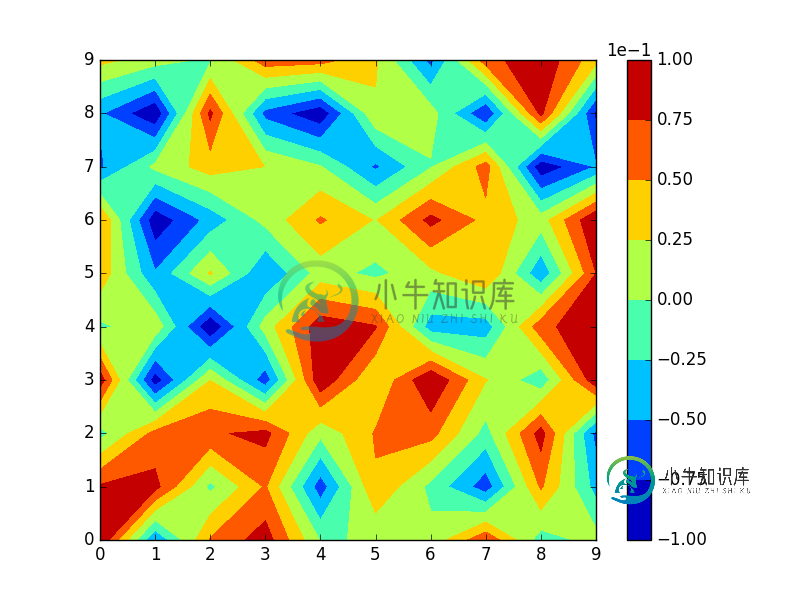 Python Matplotlib Colorbar科学符号库
Python Matplotlib Colorbar科学符号库问题内容: 我正在尝试在我的matpllotlib Contourf图上自定义颜色条。虽然我能够使用科学记数法,但我尝试更改记数法的基础- 本质上是使我的价格变动范围在(-100,100)而不是(-10,10)内。 例如,这产生了一个简单的情节… 像这样: 但是,我希望颜色栏上方的标签为1e-2,数字范围为-10至10。 我将如何处理? 问题答案: 一种可能的解决方案是按以下问题子类化并固定其数量
-
 计算机科学的基础
计算机科学的基础本书全面而详细地阐述了计算机科学的理论基础,从抽象概念的机械化到各种数据模型的建立,用算法、数据抽象等核心思想贯穿各个主题,很好地兼顾了学科广度和主题深度,帮助读者培养计算机领域的大局观,学习真正的计算机科学。
-
1.5 Scipy:高级科学计算
scipy 包含许多专注于科学计算中的常见问题的工具箱。它的子模块对应于不同的应用,比如插值、积分、优化、图像处理、统计和特殊功能等。 scipy 可以与其他标准科学计算包相对比,比如GSL (C和C++的GNU科学计算包), 或者Matlab的工具箱。scipy是Python中科学程序的核心程序包;这意味着有效的操作 numpy 数组,因此,numpy和scipy可以一起工作。 在实现一个程序前