《欢聚时代实习》专题
-
后http2时代
http2做了许多艰难的折衷和妥协。随着http2逐渐部署,将会带来一个健全的协议升级方式,而这为将来更多的协议升级奠定了基础。同时,它也引入了一套概念和基础架构来并行处理多个不同版本协议。也许我们并不需要在引入新协议时就完全将旧的淘汰掉。 http2仍然背负了许多HTTP1的历史包袱,主要是为了保证数据流量能够在HTTP 1和http2之间无碍转发。这些包袱会阻碍进一步的的开发和创造,期待htt
-
Mysql:按喜欢排序吗?
问题内容: 假设我们正在使用关键字执行搜索:keyword1,keyword2,keyword3 数据库中有“名称”列的记录: 现在查询: 它会选择记录:1,2,3(按此顺序),但我想按示例在关键字中进行排序, 因此应按关键字列出:1,3,2(因为我想在搜索后搜索“ Doe”搜索“约翰”) 我当时在想, 但是用另一种方式订购它会容易得多(实际查询时间很长) 有什么技巧可以创建这样的订单? 问题答案
-
喜欢在Elasticsearch中搜索
问题内容: 我正在使用elasticsearch从json文件过滤和搜索,并且我是这项技术的新手。所以我有点困惑如何在elasticsearch中写像查询一样的东西。 这是mysql查询。如何在Elasticsearch中编写此查询?我正在使用Elasticsearch 0.90.7版。 问题答案: 如果可能的话,我强烈建议您更新ElasticSearch版本,自0.9.x版本以来发生了重大变化。
-
SQL存储过程喜欢
问题内容: 这是一个简单的问题,我似乎想不出解决方案。 我在存储过程中定义了这个: @communityDesc是“ aaa,bbb,ccc” 在我的实际查询中,我尝试使用 但这不起作用,因为我的逗号在字符串内,而不是像这样的“ aaa”,“ bbb”,“ ccc” 所以我的问题是,对@communityDesc我可以做些什么,使其与我的IN语句一起工作,例如重新格式化字符串吗? 问题答案: 首先
-
CPUID的Intrinsics喜欢信息?
考虑到我是用C编写代码的,如果可能的话,我想使用类似于Intrinsics的解决方案来读取有关硬件的有用信息,我的关注点/注意事项是: 我不太了解汇编,仅仅获得这种信息将是一项相当大的投资(尽管它看起来像CPU,但它只是关于翻转值和读取寄存器。) asm至少有2种流行的语法(Intel和AT 我必须回答的最后一个问题是:如何用内在函数做类似的事情?因为除了CPUID操作码之外,我还没有找到任何东西
-
用户 喜欢的回答
喜欢 喜欢一个回答 取消喜欢一个回答 一个回答的喜欢列表 喜欢一个回答 POST /api/v2/question-answers/:answer/likes 响应 Header 201 Created { "message": [ "操作成功" ] } 取消喜欢一个回答 DELETE /api/v2/question-answers/:answer/likes 响应 Hea
-
欢迎来到 Ceph 世界
Ceph 独一无二地在一个统一的系统中同时提供了对象、块、和文件存储功能。div.body h3{margin:5px 0px 0px 0px;} CEPH 对象存储 REST 风格的接口 与 S3 和 Swift 兼容的 API S3 风格的子域 统一的 S3/Swift 命名空间 用户管理 利用率跟踪 条带化对象 云解决方案集成 多站点部署 灾难恢复 Ceph 块设备 瘦接口支持 映像尺寸最大
-
聚合和合成之间的代码差异[重复]
任何人都可以给出代码示例来显示聚合和组合之间的区别。我已经阅读了这篇文章,但不明白它们在代码上有何不同。 请通过代码显示差异。
-
Spring data Elasticsearch将Elasticsearch聚合查询转换为代码
Spring数据ElasticSearch 3.2 现在,由于NativeSearchQueryBuilder的addAggregation方法接受AbstractAggregationBuilder,并且sumBucket的类型为PipelineAggregationBuilder,因此无法将此值传递给addAggregation(sumBucket(“sum\u bucket”,“sequen
-
在“类内聚”或“类内聚”代码度量的上下文中,“抽象”是什么意思?
我在这个网站上讨论Eclipse中的代码度量时遇到了这个短语,特别是在讨论“缺乏内聚”的概念时: 内聚是面向对象编程中的一个重要概念。它指示类是表示单个抽象还是表示多个抽象。其思想是,如果一个类表示多个抽象,那么应该将其重构为多个类,每个类表示一个抽象。 在这种情况下,“单一抽象”是什么? 从封装和抽象的区别中,我得到抽象通常只是向用户展示必要的细节(通过使用接口和抽象类)。这里:什么是抽象?,我
-
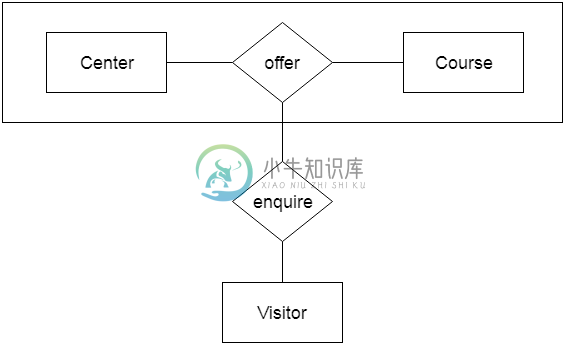 DBMS聚合
DBMS聚合在聚合中,两个实体之间的关系被视为单个实体。 在聚合中,与其对应实体的关系被聚合到更高级别的实体中。 例如:中心(Center)实体提供课程(Course)实体充当关系中的单个实体,该实体与另一个实体访问者处于关系中。 在现实世界中,如果访问者访问教练中心,那么他将永远不会询问有关课程或只是关于中心,而是他会询问有关两者的询问。
-
Elasticsearch聚合
框架集合由搜索查询选择的所有数据。框架中包含许多构建块,有助于构建复杂的数据描述或摘要。聚合的基本结构如下所示 - 有以下不同类型的聚合,每个都有自己的目的 - 指标聚合 这些聚合有助于从聚合文档的字段值计算矩阵,并且某些值可以从脚本生成。 数字矩阵或者是平均聚合的单值,或者是像一样的多值。 平均聚合 此聚合用于获取聚合文档中存在的任何数字字段的平均值。 例如, 请求正文 响应 如果该值不存在于一
-
 Maven聚合
Maven聚合主要内容:聚合,继承和聚合的关系在实际的开发过程中,我们所接触的项目一般都由多个模块组成。在构建项目时,如果每次都按模块一个一个地进行构建会十分得麻烦,Maven 的聚合功能很好的解决了这个问题。 聚合 使用 Maven 聚合功能对项目进行构建时,需要在该项目中额外创建一个的聚合模块,然后通过这个模块构建整个项目的所有模块。聚合模块仅仅是帮助聚合其他模块的工具,其本身并无任何实质内容,因此聚合模块中只有一个 POM 文件,不像其
-
Scipy簇聚
主要内容:SciPy中实现K-Means,用三个集群计算K均值K均值聚类是一种在一组未标记数据中查找聚类和聚类中心的方法。 直觉上,我们可以将一个群集(簇聚)看作 - 包含一组数据点,其点间距离与群集外点的距离相比较小。 给定一个K中心的初始集合,K均值算法重复以下两个步骤 - 对于每个中心,比其他中心更接近它的训练点的子集(其聚类)被识别出来。 计算每个聚类中数据点的每个要素的平均值,并且此平均向量将成为该聚类的新中心。 重复这两个步骤,直到中心不再移动或
-
8. 聚合
如果你需要从一个模型中获取一些聚合值,你可以使用Model.aggregate()。下面通过一个例子来展示: Person.aggregate({ surname: "Doe" }).min("age").max("age").get(function (err, min, max) { console.log("The youngest Doe guy has %d years, whi