《探探》专题
-
 PHP分页初探 一个最简单的PHP分页代码的简单实现
PHP分页初探 一个最简单的PHP分页代码的简单实现本文向大家介绍PHP分页初探 一个最简单的PHP分页代码的简单实现,包括了PHP分页初探 一个最简单的PHP分页代码的简单实现的使用技巧和注意事项,需要的朋友参考一下 PHP分页代码在各种程序开发中都是必须要用到的,在网站开发中更是必选的一项。 要想写出分页代码,首先你要理解SQL查询语句:select * from goods limit 2,7。PHP分页代码核心就是围绕这条语句展开的,SQL
-
使用性能探针监视特定功能期间的性能统计信息
问题内容: 我正在尝试使用linux perf工具监视特定功能期间的性能统计信息。 我正在按照https://perf.wiki.kernel.org/index.php/Jolsa_Features_Togle_Event#Example_- _using_u.28ret.29probes上 给出的说明进行操作 我试图获得一个简单的C程序的指令计数。(如下所示) 1)我的简单C代码 2)编译和添
-
如何从云侦探跟踪中排除一些带有假动作的调用
有一个带有Spring-Boot1.5的微服务,它使用假动作与其他服务通信,还有spring-cloud-starter-zipkin,它通过假动作包装所有调用,并将跟踪发送到zipkin服务器。问题是我不想包装所有的电话并跟踪它们,只有几个最重要的做到这一点。我如何从跟踪中排除一些带有假动作的调用(方法),或者驱逐一些整个假动作的客户端(接口)?
-
Spring云网关集成Spring云侦探比单独使用Spring云网关慢22%
当我使用spring cloud gateway集成spring cloud sleuth时,我发现性能比单独使用spring cloud gateway慢得多。是否有优化方案? 机器配置:6芯,16g Spring云网关:5331.9 tps Spring云网关Spring云侦探:4119.47 tps “Spring云网关”比“Spring云网关Spring云侦探”慢约1000-2000tps
-
如何正确配置Kubernetes探测器定时(适用于Spring Boot应用程序)
我们有一个简单的Spring Boot web应用程序,启动时间不到30秒。因此,我将探测配置如下: 我的理解是Readision probe等待30秒,然后将成功(如果应用程序启动)。而且活动性探测延迟30秒(从部署开始)开始并将在几乎同时就绪探测成功(如果应用程序准备就绪)的同时成功。但我在日志中看到的是准备状态探测器等待30秒然后成功,但之后还有30秒的等待时间,然后旧的吊舱就会关闭:
-
第5章 多线程 - 多个线程之间共享数据的方式探讨
内容摘要 多个线程之间共享数据,按照每个线程执行代码是否相同,我们可以采取不同的处理方式,这里通过简单的卖票示例说明了当每个线程执行相同代码的情况,对于多个线程执行不同代码的情况,处理方式比较灵活,这里主要介绍了2种方式,通过2种方式的对比和归纳,我们可以总结出在多个线程执行不同的代码情况下,如何进行代码的设计 1. 如果每个线程执行的代码相同 可以使用同一个Runnable对象,这个Runnab
-
为什么除了init之外,Linux设备驱动程序还需要探测方法?
问题内容: 在linux内核中,驱动程序提供的方法有什么作用?它与驾驶员的功能有何不同,即为什么不能在驾驶员的功能中执行功能动作? 问题答案: 不同的设备类型可以具有probe()函数。例如,PCI和USB设备都具有probe()函数。 如果您在谈论PCI设备,我建议您阅读Linux设备驱动程序的第12章,其中涵盖了驱动程序初始化的这一部分。第13章介绍了USB。 简短的回答,假设使用PCI:驱动
-
.Net core 的热插拔机制的深入探索及卸载问题求救指南
本文向大家介绍.Net core 的热插拔机制的深入探索及卸载问题求救指南,包括了.Net core 的热插拔机制的深入探索及卸载问题求救指南的使用技巧和注意事项,需要的朋友参考一下 一.依赖文件*.deps.json的读取. 依赖文件内容如下.一般位于编译生成目录中 使用DependencyContextJsonReader加载依赖配置文件源码查看 二.Net core多平台下RID(Runti
-
探究数组排序提升Python程序的循环的运行效率的原因
本文向大家介绍探究数组排序提升Python程序的循环的运行效率的原因,包括了探究数组排序提升Python程序的循环的运行效率的原因的使用技巧和注意事项,需要的朋友参考一下 早上我偶然看见一篇介绍两个Python脚本的博文,其中一个效率更高。这篇博文已经被删除,所以我没办法给出文章链接,但脚本基本可以归结如下: fast.py slow.py 如你所见,两个脚本有完全相同的行为。都产生一个包
-
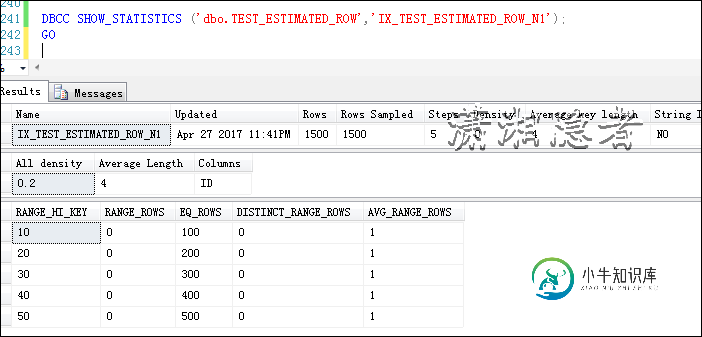 SQL Server中关于基数估计计算预估行数的一些方法探讨
SQL Server中关于基数估计计算预估行数的一些方法探讨本文向大家介绍SQL Server中关于基数估计计算预估行数的一些方法探讨,包括了SQL Server中关于基数估计计算预估行数的一些方法探讨的使用技巧和注意事项,需要的朋友参考一下 关于SQL Server 2014中的基数估计,官方文档Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator里有大量细节
-
linux上的Jprofiler远程评测。如何更改探查器数据文件的路径
我在linux box上运行java(java 6)应用程序,带有附加设置-agentpath:/home/myuser/janalyiler/bin/linux-x64/libjprofilerti.so=noatt, port=7777在Win box上使用JProfiler 7.2.1我可以连接到进程并检索分析数据。 我可以看到,在Linux机器上,JProfiler在“/tmp”目录下生成
-
当容器转换为就绪时,Kubernetes就绪探测是否应该发出事件?
现在,我注意到具有,但是events列表中的最后一个事件将状态列为,因为准备状态探测失败。(在应用程序日志中,我可以看到,自那以后,有更多的请求传入准备状态探测,并且它们都成功了。) 我应该如何解释这些信息?Kubernetes认为我的豆荚准备好了,还是没有准备好?
-
Spring Interceptor对于Spring侦探3. x. x的后完成方法具有不同的traceId
我目前正在从事Spring boot项目。最近,我将Spring boot的版本从2.3.3升级到2.6.6。在Spring boot 2.3.3中,我使用的是Spring cloud sleuth 2.x.x,由于Spring cloud依存关系管理BOM,它现在已经升级到3.x.x。POM如下 我有一个拦截器如下 早些时候,这段代码为该特定请求的所有日志提供了相同的traceId。但是使用Sp
-
Spring的云侦探如何允许某些URL模式单独导出跟踪到zipkin
要求是从应用程序向zipkin导出匹配url模式的请求跟踪。我知道在sleuth属性中有选项可以从导出中排除跟踪。但我的情况恰恰相反。包括仅用于导出指定url模式的跟踪。 我尝试使用一个自定义的httpSampler,并提到了基于url模式导出跟踪的逻辑。但它并没有像预期的那样起作用。有没有相同的样品,真的有帮助吗?非常感谢。
-
哈希表中的冲突和探测长度有什么区别?如何追踪他们?
大家好,我是Python新手,我实现了一个哈希表类,它通过线性探测解决冲突。 现在我正在尝试编写一个函数来跟踪碰撞次数和探针长度。我已经编写了函数来跟踪碰撞次数,但是我不知道如何跟踪探针长度,因为我认为它们是相同的? 编辑:好的,显然冲突意味着哈希(键)给定的位置已经被占用。探针长度是指在找到一个位置(在开放寻址中)之前,你要做多少次尝试。 所以我猜应该是这样: