《国企招聘》专题
-
 阿巴国际-1面凉经
阿巴国际-1面凉经客户端开发,电话面,二十多分钟给我结束了,问得很基础 自我介绍 介绍一下JVM作用和结构,类的加载过程,每一步的作用原理等 讲讲过滤器和拦截器的作用,怎么使用,过滤器链,怎么排序的?(md,好久没看了,接口名都忘了,哭死...) ArrayList和LinkedList说一下? Spring中的AOP讲解一下,原理、作用场景和使用? Mysql中执行一条sql语句过程,步骤处理过程说一下? Red
-
 字节 国际电商 三面
字节 国际电商 三面面试岗位:前端开发 base 珠海杭州 面试时间: 9.9 时长:60min 问题 1.自我介绍 2.wxzf转正了吗,怎么没有继续实习 3.实习项目拷打(20min) 4.闲聊(兴趣爱好、一直坚持的爱好、最近在学的新东西) 5.索引 6.left join和right join的区别 7.进程和线程的区别 8.thsi指向输出题 9.代码题:最大岛屿面积 感觉不是很有参考价值,因为二面全是八股,
-
 中国银行实习笔试
中国银行实习笔试0offer,发笔试攒人品。 信息科技岗,2023.4.22 14:00-16.10,130分钟,线上易考客户端,单摄像头。 题型: 第一单元:行测、中行相关基础知识。(70道题,单选,多选) 没有啥离谱的考记忆力的题 第二单元:四级难度英语。(20道单选,一篇选词填空,一篇阅读理解单选) 第三单元:计算机基础+JAVA编程题(简单语法题)。(70道题,单选,多选) 编程题不需要编程,题目一般问这
-
MySQL企业版的身份验证插件问题
我已经安装了一个MySQL企业版的试用版,当使用捆绑工作台软件连接时,我得到以下错误: 无法加载身份验证插件缓存\u sha2\u密码:找不到指定的模块 在那里我能找到的信息很少。大多数解决方案返回到旧的身份验证方法,但我不想这样做,而且它似乎无论如何都不起作用。。。 HeidiSQL给出了相同的错误消息。 有什么建议吗?
-
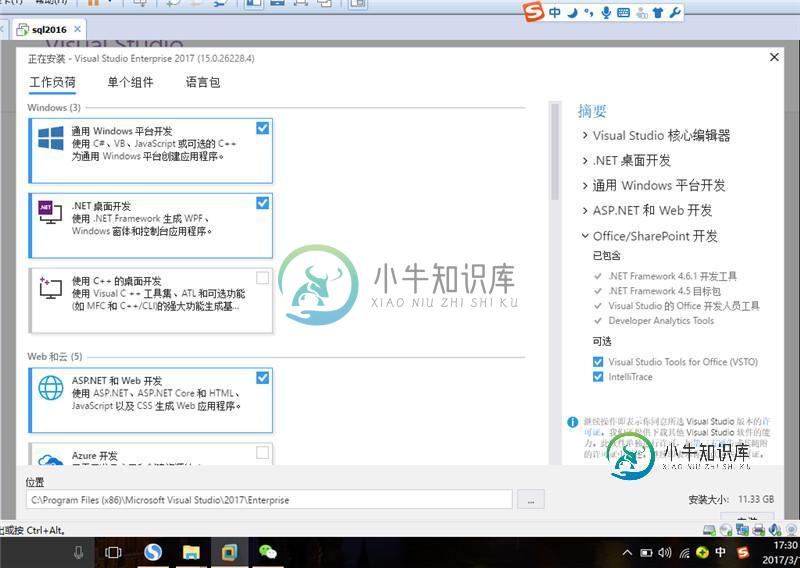 visual studio 2017企业版本安装(附序列号)
visual studio 2017企业版本安装(附序列号)本文向大家介绍visual studio 2017企业版本安装(附序列号),包括了visual studio 2017企业版本安装(附序列号)的使用技巧和注意事项,需要的朋友参考一下 记录了vs2017企业版本安装和序列号,分享给大家。 离线包大概下载为19G,可以选择的选择项很多,很不错,安装如下: 安装完成 启动效果 SharePoint插件自带了 离线包(19G) Visual Studio
-
C++实现企业职工工资管理系统
本文向大家介绍C++实现企业职工工资管理系统,包括了C++实现企业职工工资管理系统的使用技巧和注意事项,需要的朋友参考一下 课程设计目的和要求 工资管理要和人事管理相联系,生成企业每个职工的实际发放工资。 企业职工人事基本信息包括:职工编号、姓名、性别、出生日期、职称(助工、工程师、高级工程师)和任职年限。 企业职工工资信息包括:职工编号、姓名、职务工资、职务补贴、住房补贴、应发工资、个人所得税、
-
Spring Security性和企业LDAP身份验证错误
我使用Spring Security(基本身份验证)+LDAP身份验证,这与嵌入式测试ldif很好,但与我的域LDAP不一样。但是,我可以使用LDAP浏览器/编辑工具使用相同的筛选器搜索我的帐户(SAMAccountName=NAPO) 错误消息为:LDAP:错误代码32-0000208D:Nameerr:DSID-0310020A,problem 2001(NO_OBJECT)
-
 美团企业平台研发部前端面经
美团企业平台研发部前端面经一面4.20 二面4.21(回人才库,求捞) (面试官都很温柔地引导,面试体验感很好) 一面: 1、自我介绍 2、什么时候接触前端,为什么学习前端 3、学完做了哪些成果、项目 4、实习期间主要工作、项目相关问题 5、项目管理模块如何实现 6、组件的定义 7、项目遇到最大的困难是什么,如何解决的 8、对vue的理解 9、vue的生命周期有哪些 10、vue2、vue3卸载前的钩子名字一样吗 11、c
-
4.7 如何与企业自有 IT 系统对接
当一款产品需要与其他产品集成时,往往意味着漫长的对接流程,从零开始了解对方的系统架构、低效的沟通,开发 API 等等,其中耗费的时间与精力,拖慢了很多公司的工作效率。 金数据目前已经拥有完整的 API,可以让你免去很多对接工作,也有附带参数跳转的功能,方便你将数据写入自己的系统内。 开启 API 金数据 API 为具备编程能力的用户提供了极强的扩展功能。开发者可以通过表单API获取表单定义、通过数
-
4.5 如何用企业版改造出差系统
一般出差的流程是这样的: 申请人填写出差申请表 行政为申请人选择航班和酒店信息 发送邮件,确认航班与酒店 根据确认情况进行预定,允许出差 很多 HR 按照这个流程做了这个一个表单,如图 1 所示: 图1 出差申请表 可依然会遇见问题,因为出差的航班和酒店需要从外部网站预定,一直处于变化中,而且每个人的需求又千差万别。且不说出差人数多时带来的管理成本,单单每次翻来覆去地确认都极费功夫。辛辛苦苦确定方
-
2.1.11 借款企业法人、股东、高管信息
描述 创建借款方为企业,关联关系为法定代表人、总经理、财务负责人、实际控制人、直接关联人、间接关联人、控股股东、股东的关联人信息 规则 与借款企业关联关系为法定代表人时:必须添加一个 与借款企业关联关系为总经理时:可以添加一个或多个 与借款企业关联关系为财务负责人时:可以添加一个或多个 与借款企业关联关系为实际控制人时:可以添加一个或多个 与借款企业关联关系为直接关联人时:可以添加一个或多个 与
-
审批通过后如何企业支付用车
当用车审批通过时,可按照以下流程使用企业支付用车 员工操作步骤 1.登录滴滴企业版app 2.选择审批通过的用车制度 3.根据制度要求填写行程信息
-
在企业和应用市场发布Office Add-in
作者:陈希章 发表于 2017年12月20日 我已经写了很多关于Office Add-in的内容,而且我相信你已经尝试过创建一两个Add-in了吧。作为一个开发人员,你有多种方式在自己的机器上使用你的作品,例如 如果你是用Visual Studio开发,这是最简单的,你直接按F5就可以了 你可以将manifest文件(其实就是一个XML文件)保存到一个共享目录,然后通过在Office客户端中,添加
-
兑吧荣膺金芒奖十大创新企业
当前,企业服务市场处于从探索到高速发展的转变时期,市场竞争日趋激烈。但与消费互联网时代相比,产业互联网时代的最大特征,是无法再单纯依靠市场驱动造就一家飞速增长的企业。在下半场的寒冬中,创新能力成为照亮toB企业前行的火把,助力具备前瞻性眼光的企业构筑行业壁垒,在细分领域中实现迅猛发展。 12月22日,由微链主办的“2018金芒奖年度创新创业颁奖盛典”在杭州电视台隆重举办。本届峰会上,兑吧凭借着在企
-
 腾讯 wxg 企业微信 后台开发 秒挂
腾讯 wxg 企业微信 后台开发 秒挂最小丑的一集,我是蠢比🤡🤡🤡🤡🤡🤡🤡🤡🤡🤡 2024.03.15 半小时 秒挂 1.自我介绍 2.Linux Kill进程后内存会不会回收,谁来回收的,怎么回收的。 3.redis热key问题,有一个热key,如果redis宕机了怎么办,直接打到数据库上面吗,回答降级限流,他说有没有更优雅的方式 4.微服务远程调用,或者说网络远程调用接口的时候,操作系统内核干了什么 5.red