《新国都集团》专题
-
 如何在VSCode集成终端中打开新的Ubuntu 20.04 shell (WSL2)
如何在VSCode集成终端中打开新的Ubuntu 20.04 shell (WSL2)在我的机器上,我已经在Windows 10 Pro和Ubuntu 20.04 LTS发行版上安装了WSL2。我还使用VSCode作为编程编辑器。我在Windows中启动VSCode(不在WSL2 Ubuntu中),并且可以使用配置文件“New Ubuntu-20.04(Standard)(WSL)”创建新终端。 但是,这不起作用,因为它调用命令“wsl-d Ubuntu-20.04(Standar
-
编辑文本集选择清除文本,然后重新输入
我一直有一些来自EditText的奇怪行为的问题。setSelect,我希望你们都能帮忙! 我正在开发的应用程序有一个搜索字段,需要让它的行为非常类似于浏览器的搜索栏。例如,如果用户键入“fo ”,我们希望EditText自动完成“foobar ”,并突出显示自动完成的“obar”文本,以便在自动完成的文本与用户想要键入的内容不匹配时,用户可以很容易地替换它。 为了实现这一点,我设置了一个带有Te
-
JS实现的集合去重,交集,并集,差集功能示例
本文向大家介绍JS实现的集合去重,交集,并集,差集功能示例,包括了JS实现的集合去重,交集,并集,差集功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS实现的集合去重,交集,并集,差集功能。分享给大家供大家参考,具体如下: 1. js 实现数组的集合运算 为了方便测试我们这里使用nodejs,代码如set_operation.js 2. 测试 我们这里使用nodejs来测试 测试
-
 美团成都闪购3.24前端一面凉经
美团成都闪购3.24前端一面凉经自我介绍 项目相关 为什么学前端 怎么看待vue和react。为什么学了vue,对react了解多少 vue和react这些框架的出现解决了哪些问题(答复用和前端工程化)。面试官反问组件复用和前端工程化原生都可以做到,有多少了解(没了解,反问是微前端吗,不是) node了解多少 nodejs的事件循环和浏览器的事件循环区别(没答上来) tcp/udp,为什么需要四次挥手 for in for
-
 联影集团(offer)
联影集团(offer)8月19号投递,21号测评,8月31号运维部门面试,9月1号开发部门面试(好像简历被两个部门都查看,导致被两个部门进行了约面),9月19号hr面试 不知道为什么联影和其他公司有个不同的点,联影是部门leader直接约面,而不是经由hr约面 一、运维部门:8月31号 1、自我介绍 2、聊了之前实习的工作,聊了下docker和k8s 3、聊了自己的研究方向 4、问了自己获得的奖项,在校成绩,在校比赛,
-
 东软集团 C++
东软集团 C++1、面向对象三大特性 2、static的用法和作用 3、介绍下引用 4、常用的STL容器(vector、list、map) 5、分别都介绍一下 6、了解socket吗?socket中三次握手的建立 7、进程通信 8、共享内存函数有什么?(这个忘了...) 9、死锁产生的条件 10、堆和栈都存储的什么 11、I/O多路复用介绍一下 12、设计模式了解哪些 13、C++11新标准知道哪些?Lambda
-
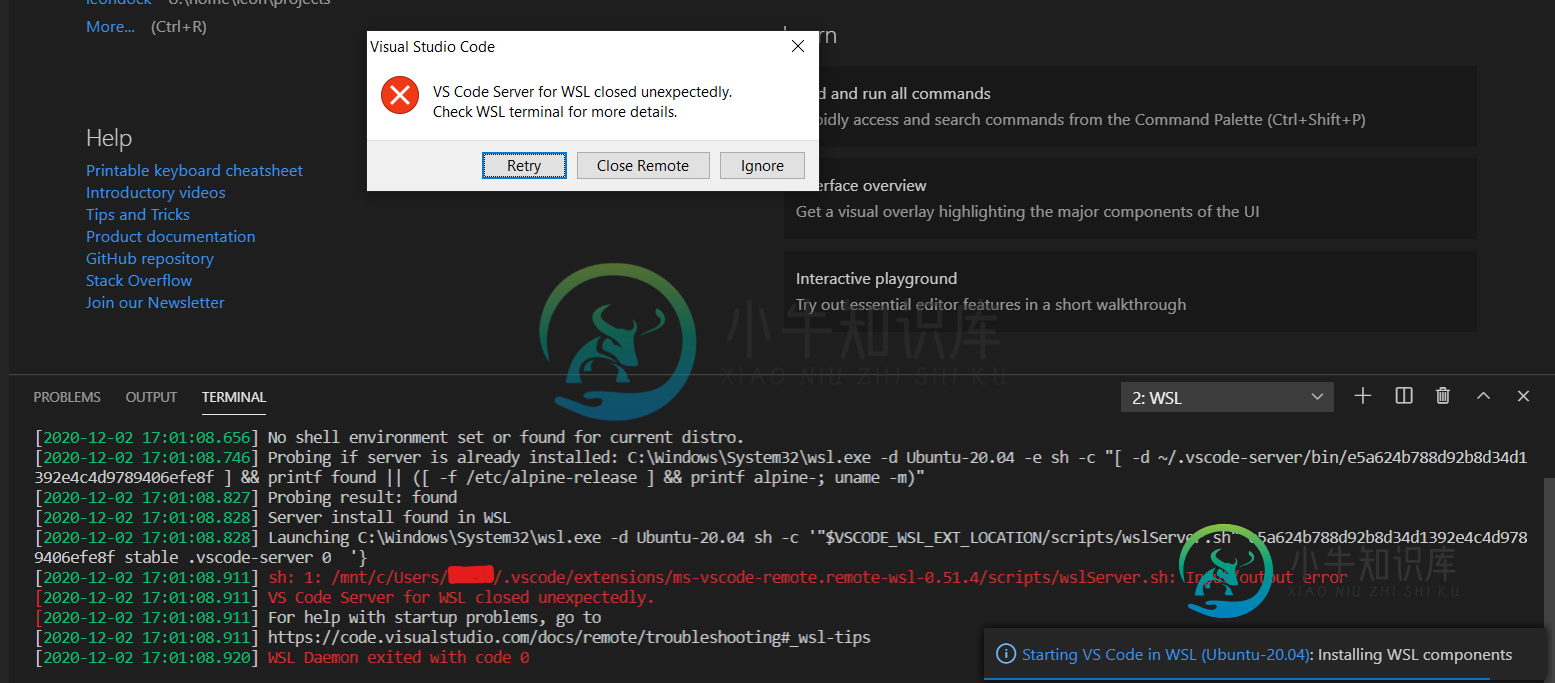 每次在 Windows 启动后都需要重新启动 wsl,然后才能使用 vscode 远程
每次在 Windows 启动后都需要重新启动 wsl,然后才能使用 vscode 远程我正在运行带有 WSL2 的视窗 10。我正在使用带有远程 - WSL扩展名的VSCode从我的wsl文件系统中打开文件。 当我启动我的Windows笔记本电脑并打开VSCode时,我收到以下错误: 当我执行<code>wsl时。exe——关闭PowerShell中的</code>,然后重新启动Docker Desktop,一切正常。但每次笔记本电脑重启后,我都必须这样做。 远程WSL扩展版本:v
-
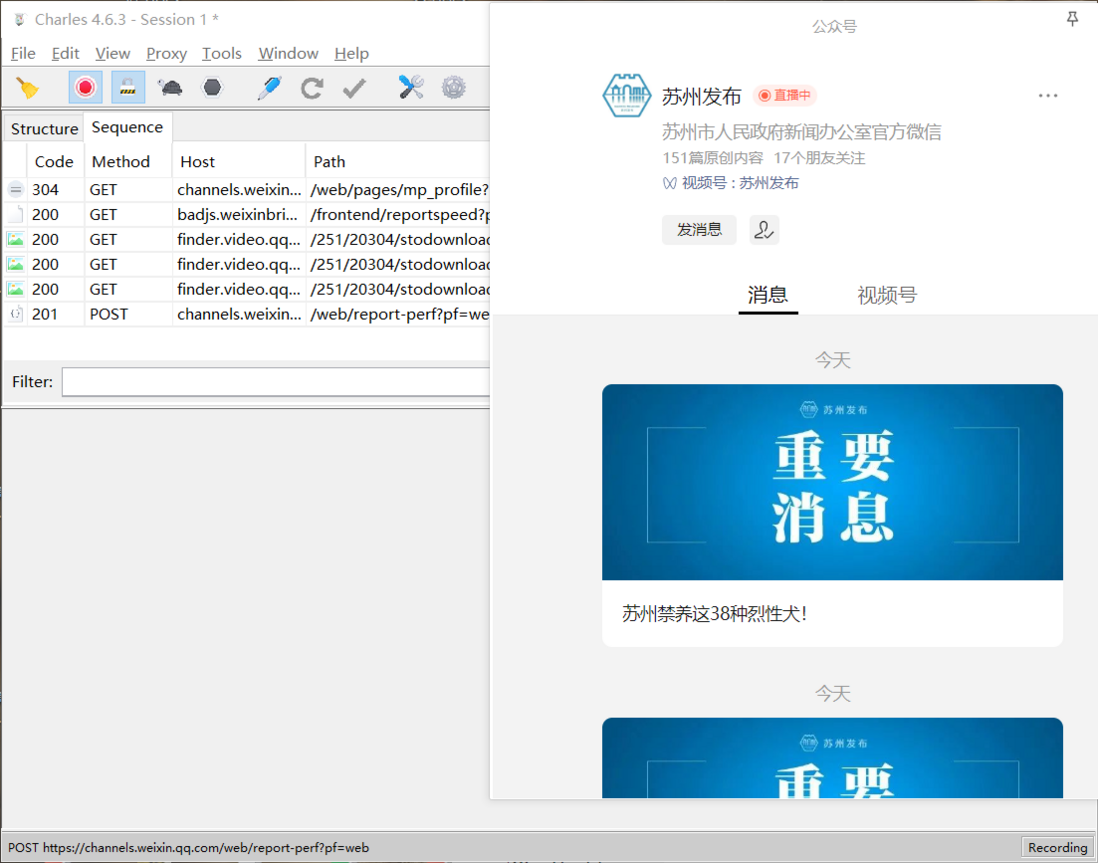 python - 微信公众号新闻列表如何抓包?使用charles和fiddler都无法抓到?
python - 微信公众号新闻列表如何抓包?使用charles和fiddler都无法抓到?如题,我尝试了使用Fiddler抓包,但是Fiddler似乎并不支持微信现在的H2协议,于是又尝试了用charles去抓包,发现使用charles仍旧抓不到列表中新闻的包。(只能抓到某一新闻详情页的包) 如下图左边部分。 之前我也尝试过用proxifer和Burp去抓包(当时也没有抓包成功),想请问有哪位大佬尝试过现在的抓包是否能够成功?如果是软件原因的话有没有其他推荐的抓包软件?
-
2.3.3 Dubbo 负载均衡策略和集群容错策略都有哪些?动态代理策略呢?
面试题 dubbo 负载均衡策略和集群容错策略都有哪些?动态代理策略呢? 面试官心理分析 继续深问吧,这些都是用 dubbo 必须知道的一些东西,你得知道基本原理,知道序列化是什么协议,还得知道具体用 dubbo 的时候,如何负载均衡,如何高可用,如何动态代理。 说白了,就是看你对 dubbo 熟悉不熟悉: dubbo 工作原理:服务注册、注册中心、消费者、代理通信、负载均衡; 网络通信、序列化:
-
点燃远程群集[无法为缓存映射键(所有分区节点都离开了网格)]
数据插入使用简单的cache.put命令。如果有人能在这件事上帮我,我将不胜感激。
-
Python数组并集交集补集代码实例
本文向大家介绍Python数组并集交集补集代码实例,包括了Python数组并集交集补集代码实例的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Python数组并集交集补集代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 并集 打印结果: 交集 打印结果: 补集 打印结果: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望
-
查找SQL中超集的子集的所有集
问题内容: 我正在考虑一个应用程序的设计,该应用程序的主要功能围绕着找到所有给定集合的子集的集合的能力而展开。 例如,给定输入集A = {1,2,3 … 50}和集合集B = {B1 = {3,5,9,12},B2 = {1,6,100,123,45}。 .. B500 = {8,67,450}},返回所有属于A子集的B。 我想它与搜索引擎类似,除了我并没有设置A小而B大的奢侈。在我的情况下,B通
-
Spring集成子集和Spring子集交互问题
我创建了一个新示例,并将代码分为客户端和服务器端。 完整的代码可以在这里找到。 服务器端有3个版本。 服务器无Spring Boot应用程序,使用Spring Integration RSocket InboundGateway 服务器引导重用Spring RSocket autconfiguration,并通过serverrsocketmessagehandler创建ServerRSocketC
-
收集Firestore收集和子收集文档数据
我的Ionic 5应用程序中有以下Firestore数据库结构。 书(集合) {bookID}(带有book字段的文档) 赞(子集合) {userID}(文档名称作为带有字段的用户ID) 集合中有文档,每个文档都有一个子集合。Like collection的文档名是喜欢这本书的用户ID。 我正在尝试进行查询以获取最新的,同时尝试从子集合中获取文档以检查我是否喜欢它。 我在这里做的是用每个图书ID调
-
集成
可运行和可调用 如果你在Runnable或Callable中包含你的逻辑,就可以将这些类包装在他们的Sleuth代表中。 Runnable的示例: Runnable runnable = new Runnable() { @Override public void run() { // do some work } @Override public String toString()