《大数据测试》专题
-
 字节data大数据开发一面6.19-50min
字节data大数据开发一面6.19-50min1.问本科经历,对大数据的接触 2.问项目是否是真实项目或者实习项目,,不是demo 3.项目介绍,毕设项目讲了15分钟 4.where和having区别(having能单用) 5.Spark宽窄依赖 6.leftrightinnerjoin 7.sql写题,统计所有月销售额超过1w的员工 8.反问,ABtesting--是否是埋点-PVUV-灰度策略的流程
-
将可观测数据馈送到其他可观测订阅
我正在创建一个应用程序,希望用户打开他们的活动聊天。它由Firebase作为后端提供动力。但是,在从第一个可观察订阅中检索数据(我需要将其用作第二个可观察订阅中的参数)之后,第二个订阅不会返回任何数据:它是空的。 在第一个订阅中,我检索一个唯一的ChatID。对于第二次订阅,我希望使用此ChatID接收Firebase集合中的所有邮件。 我已经发现它与观测对象的异步风格有关,但是我不知道如何嵌套观
-
 蔚来 数字化业务 大数据开发工程师
蔚来 数字化业务 大数据开发工程师投nlp挂,转岗大数据开发 一面 算法题:一个只包含1,2,3的数组,排序使得3在最前,2在中间,1在最后。要求时间复杂度O(n),空间复杂度O(1)。 用双指针,类似快排的思路。 二面 算法题:数组中,第一个非0的数位置索引,时间复杂度O(log n)。 二分查找。 两个面试官都很nice,没有因为岗位不匹配为难。#我的秋招日记#
-
 中信银行 大数据中心 数分 一面面经
中信银行 大数据中心 数分 一面面经背景:双211,研究方向:计算机视觉(遥感变化检测) 一志愿:AI算法(应该是挂了一志愿) 二志愿:数分 10.26上午 腾讯会议视频面试 1个hr/3个面试官 1.自我介绍 2.有没有实习? 3.介绍一个项目所做的工作 4.技术栈:会什么编程语言,数据处理都是自己用python写的方法吗?有没有使用过什么大型数据处理软件或许使用过哪些python数据分析库 ? 5.了不了解结构化数据,大数据?(
-
 蔚来一面-质量数字化与大数据处理
蔚来一面-质量数字化与大数据处理自我介绍 实习经历介绍 质量数字化最重要的作用是什么 你的工作对部门的贡献是什么 项目介绍 关于项目内容,例如什么是PCA、项目落地情况、 反问:岗位主要职责
-
如何在Pandas中的超大型数据框上创建数据透视表
问题内容: 我需要从大约6000万行的数据集中创建一个2000列,大约30-50百万行的数据透视表。我曾尝试过旋转100,000行的数据块,但这种方法行得通,但是当我尝试通过先执行.append()然后再执行.groupby(’someKey’)。sum()来重组DataFrame时,我的所有内存都被占用了和python最终崩溃。 如何在有限的RAM量下处理如此大的数据? 编辑:添加示例代码 下面
-
超大数据量存储常用数据库分表分库算法总结
本文向大家介绍超大数据量存储常用数据库分表分库算法总结,包括了超大数据量存储常用数据库分表分库算法总结的使用技巧和注意事项,需要的朋友参考一下 当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而
-
如何在Quarkus中通过REST从数据库流式传输大型数据
我正在Quarkus中实现一个方法,它应该向客户端发送大量数据。使用JPA/Hibernate从数据库中读取数据,序列化为JSON,然后发送到客户端。如果没有整个数据在内存中,如何有效地完成此操作?我尝试了以下三种可能性,但都没有成功: 使用JPA中的getResultList,返回一个以列表为主体的响应。MessageBodyWriter将负责将列表序列化为JSON。然而,这会将所有数据拉入内存
-
当输入的数据量很大时,执行者将如何处理数据?
Q2-缓存如何帮助这里获得更好的性能,可以使用什么缓存策略?(仅限Mem、Mem和磁盘等)
-
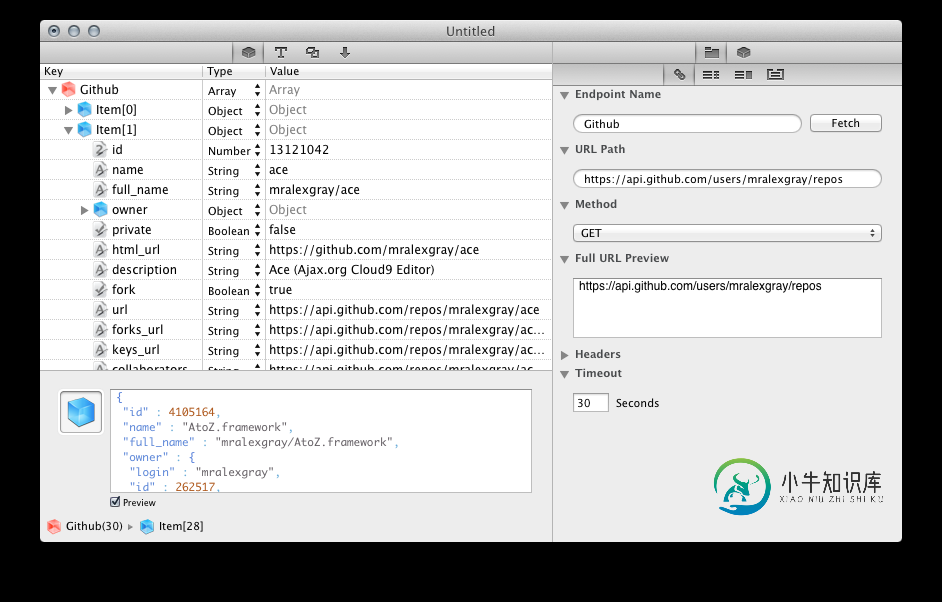 是否有任何可公开访问的JSON数据源可用于测试实际数据?
是否有任何可公开访问的JSON数据源可用于测试实际数据?问题内容: 我正在研究JavaScript动态加载的树视图用户控件。我想用现实世界的数据进行测试。 是否有人知道有任何公共服务带有API,该API提供了对JSON格式的分层数据的访问? 问题答案: Twitter有一个 返回JSON 的公共API,例如- 一个请求: , 编辑: 由于Twitter限制了其API的要求而被删除… 用Github API的简单示例替换它-返回一个树,在本例中为我的存储
-
当我们不考虑数据帧的大小时,如何快速地从PySpark中的大数据中采样?
我有两个pyspark数据帧和,其中比大得多。这些数据流的大小每天都在变化,我不知道它们。我想从中随机选取数据组成一个新的数据帧,其中的大小大约等于的大小。目前我有以下几行: 这些线产生正确的结果。但当的大小增加时,需要几天才能完成。你能建议另一种在Pyspark更快的方法吗?
-
Spring启动(数据)海森布格与检测数据库驱动程序
在开发Spring BootRESTendpoint时,我的应用程序会遇到奇怪的(heisenbug)行为。我为每个endpoint项目制作了单独的模块,这也可能与此相关。在细节上,它可以运行一次,但在重新运行后会失败,可能运行一个endpoint,但不会运行另一个,反之亦然。 描述: 无法确定数据库类型 NONE 的嵌入式数据库驱动程序类 行动: 如果你想要一个嵌入式数据库,请在类路径上放置一个
-
Google play console不再在大多数设备上测试应用程序
自2019年1月15日更新我的android studio以来,google play console不再在P8 Lite以外的任何设备上测试我的应用程序。所有其他设备状态为“此时无法测试此设备,请上载新的APK”。 我在任何地方都找不到关于为什么会发生这种情况的任何信息。是不是因为谷歌不再支持这些设备上的测试?或者这是对我的代码进行的更新? 我已经包括了我的gradle代码,以防它是由于SDK冲
-
如何以编程方式为Spring中的集成测试填充测试数据?
我正在寻找使用spring/Spring Boot在集成测试中以编程方式填充测试数据的推荐方法。我正在使用HSQLDB(inmemory)。 在spring中执行SQL脚本进行集成测试的可能性如下: 与编写SQL脚本不同,我希望在一个集成测试中以编程方式插入多个测试方法的数据,如下所示: 这个例子的每个测试在单独执行时都运行得很好。但是第二个(getByIsbn)在一起运行时会失败。因此,这里使用
-
 2023秋招-大数据开发面试-阿里国际-一面
2023秋招-大数据开发面试-阿里国际-一面1、 确认专业,保研,成绩,排名 2、 课程内容,研究生课程等 3、 数据库底层索引的优劣势? 4、 我现在有一张表把所有字段都加索引了,这样好吗? 5、 存储过程和视图? 6、 视图字段是单独存储的吗? 7、 MR原理用你自己话简单描述。 8、 MR中数据倾斜的产生情况,你如何解决? 9、 一个复杂的SQL中发生了数据倾斜,你怎么确定是哪个group by还是join发生的? 10、 count