《大数据研发实习》专题
-
 京东-数据开发-校招一面
京东-数据开发-校招一面零售数据部门,看到帖子说态度很差,吓得我慌的一批 结果是个姐姐,态度很好 详细问了简历、项目、实习经历,对沟通过程、难点、技术点进行了深挖 数仓问了几个八股,不重要 然后就是什么性格、抗压能力、职业规划之类的 我反正周周面,面麻了,面试好不代表能进,爱咋咋地,巴不得地球爆炸
-
 同程旅行 数据开发 面经
同程旅行 数据开发 面经Timeline: 9.1 投递 9.14 笔试 9.25 一面 11.1 二面 技术+HR面 9.25 一面 23min: 1.项目经历 2.数仓分层 3.数仓执行引擎 4.Sql关键字执行顺序 5.Mysql索引引擎 6.Innodb和myisam区别 7.Flink基本算子 8.Map和flatmap 9.Keyby 10.数据倾斜 怎么定位 11.Hive分区表和非分区表 12.增加或删
-
 作业帮二面 数据开发 40min
作业帮二面 数据开发 40min最喜欢的一种面试方式,全程问实习和项目。 1.自我介绍+技术栈介绍+实习介绍+难点介绍(第一次做了十多分钟的自我介绍) 2.你的难点为什么不用oltp引擎解决呢,应该多拓展一下oltp的宽度(针对oltp讨论了快⑩分钟) 3.bitmap详细讨论 4.用户怎么使用你们的数据产品 5.实时了解吗 6.base地只考虑武汉还是都可以 许愿hr面 #数据人的面试交流地#
-
 美团数据开发一面面经
美团数据开发一面面经马上入职一个月了 记录一下面经~ 一面:(50min) 1.自我介绍 2.介绍实习项目 3.实习过程中遇到了问题是怎么排查的? 4.介绍一下你自己写的项目 5.讲一下java内存模型 6.scala和java有什么区别?说一下你的理解 7.手撕代码:两道sql,一个算法,算法是反转链表 8.你对数据仓库了解多少?对大数据了解多少? 反问: 1.评价 2.部门技术栈 #美团##美团25届转正实习##
-
 特斯拉数据开发技术面
特斯拉数据开发技术面#软件开发2024笔面经# 1说说你对数仓里分层的理解,越详细越好? 2说说你对数仓里数据建模的认知理解,越详细越好? 3之前做过数仓么? 4请简要说明什么是数据仓库,以及它与数据库的主要区别。 5列举几种常见的数据抽取、转换和加载(ETL)工具,并简述其特点。 6如何处理数据中的缺失值?请举例说明至少两种方法。 7讲一讲你对分布式数据处理框架(如 Hadoop、Spark 等)的理解。 8在大数
-
 美团一面凉经 | 数据开发
美团一面凉经 | 数据开发笔试 90min 选择题+sql*1+算法*2 简单sql,困难算法 一面 共 50min 自我介绍 sql 3小问 15min 实习经历 项目经历 数仓分层的意义 从hdfs如何到ODS层 介绍维度表和事实表 有没有使用zookeeper hadoop节点之间如何进行联系 hive sql脚本是在哪里运行 一共有多少张表,都是自己写的吗 做数仓的时候遇到了哪些困难,怎么解决的 在实习期间的困难和
-
 作业帮 数据开发 一面 40min
作业帮 数据开发 一面 40min1.自我介绍 2.介绍项目,数据哪来的,数据量级,数仓模型,曝光率怎么算的 3.难点介绍,随spark版本变化会不会有一些函数不适用 4.bitmap的JAVA实现,哈希冲突怎么做的 5.数据倾斜介绍 6.除了数据倾斜,还有哪些优化手段 7.开窗函数 8.udf用过吗 9.JAVA实现过什么项目 10.sql:去掉一个最高分去掉一个最低分求用户平均分 很常规的一次面试,没什么好细说的 #数据人的面
-
 9-4 海亮集团-数据开发
9-4 海亮集团-数据开发数仓有哪几层,每层作用 星型模型和雪花模型 累计快照事实表,拉链表 如何进行维度建模 遇到的数据倾斜问题 大小表join 内部表和外部表区别 拉链表如何设计 spark为什么快 指标体系的建设和管理 用过bi报表之类的吗 炸裂函数,开窗函数 rdd和dataframe的区别
-
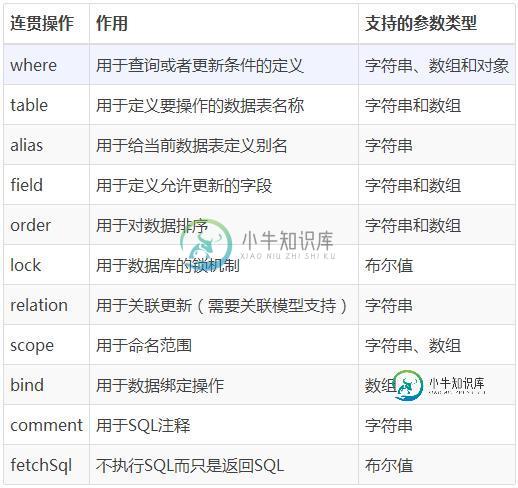 ThinkPHP实现更新数据实例详解(demo)
ThinkPHP实现更新数据实例详解(demo)本文向大家介绍ThinkPHP实现更新数据实例详解(demo),包括了ThinkPHP实现更新数据实例详解(demo)的使用技巧和注意事项,需要的朋友参考一下 在没介绍正文之前先给大家介绍下数据更新方法支持的连贯操作方法有: 在上一篇文章中我们实现了数据的删除和批量删除,这一篇文章我们将实现数据的更新。 首先依然是预期效果图: 点击修改后进入modi.html页面,然后进行修改,如此处修
-
C#实现窗体间传递数据实例
本文向大家介绍C#实现窗体间传递数据实例,包括了C#实现窗体间传递数据实例的使用技巧和注意事项,需要的朋友参考一下 本文以实例详述了C#两个窗体之间传递数据的实现方法,具体的操作步骤如下: 1.建立两个窗体,并采用公用变量值传递: 2.使用地址方式传递
-
JavaScript实现的链表数据结构实例
本文向大家介绍JavaScript实现的链表数据结构实例,包括了JavaScript实现的链表数据结构实例的使用技巧和注意事项,需要的朋友参考一下 此例是javascript来建立链表。。 并对此进行了排序。。 还可以在GenericList一般链表上进行扩展。 实现各种排序及增,删,改结点。。
-
PowerShell函数参数指定数据类型实例
本文向大家介绍PowerShell函数参数指定数据类型实例,包括了PowerShell函数参数指定数据类型实例的使用技巧和注意事项,需要的朋友参考一下 本文介绍在PowerShell创建自定义函数时,为必选参数设置强类型有什么好处,应该如何设置。 为了提高必选参数的安全性,PowerShell函数定义的最佳实践告诉我们,要为必选参数设置强类型。这是为什么呢,我们来看一个例子。 上面这个例子是接收用
-
如何在Pandas中的超大型数据框上创建数据透视表
问题内容: 我需要从大约6000万行的数据集中创建一个2000列,大约30-50百万行的数据透视表。我曾尝试过旋转100,000行的数据块,但这种方法行得通,但是当我尝试通过先执行.append()然后再执行.groupby(’someKey’)。sum()来重组DataFrame时,我的所有内存都被占用了和python最终崩溃。 如何在有限的RAM量下处理如此大的数据? 编辑:添加示例代码 下面
-
超大数据量存储常用数据库分表分库算法总结
本文向大家介绍超大数据量存储常用数据库分表分库算法总结,包括了超大数据量存储常用数据库分表分库算法总结的使用技巧和注意事项,需要的朋友参考一下 当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而
-
如何在Quarkus中通过REST从数据库流式传输大型数据
我正在Quarkus中实现一个方法,它应该向客户端发送大量数据。使用JPA/Hibernate从数据库中读取数据,序列化为JSON,然后发送到客户端。如果没有整个数据在内存中,如何有效地完成此操作?我尝试了以下三种可能性,但都没有成功: 使用JPA中的getResultList,返回一个以列表为主体的响应。MessageBodyWriter将负责将列表序列化为JSON。然而,这会将所有数据拉入内存