《搜狐畅游》专题
-
MavenSpring数据弹性搜索依赖未找到
我有一个spring boot应用程序,我想使用依赖项spring data elasticsearch。我在服务器上使用的是最新版本的Elasticsearch(v5.4.x),所以我不得不使用最新的spring数据快照Elasticsearch(3.0.0.BUILD-snapshot)。 根据git页面(下面的链接): https://github.com/spring-projects/s
-
没有v8-profiler的Node.js内存泄漏搜寻
问题内容: 我正在尝试追踪Node.js应用程序中的内存泄漏。我已经尝试安装v8-profiler,但无法编译…看起来像一个死项目,很多人都在尝试使用它,但是遇到了同样的问题- 大约在节点0.3.2上已经很多了前。 有谁知道一种不使用v8-profiler来查找Node.js应用程序中的内存泄漏的方法吗?我在运行V8远程调试的Eclipse上运行,但是找不到找到内存使用情况/堆等的方法。 问题答案
-
 ubuntu16.04安装搜狗拼音的图文教程
ubuntu16.04安装搜狗拼音的图文教程本文向大家介绍ubuntu16.04安装搜狗拼音的图文教程,包括了ubuntu16.04安装搜狗拼音的图文教程的使用技巧和注意事项,需要的朋友参考一下 首先在官网上面,下载最新的搜狗拼音输入法 Linux 版本。 双击运行,发现安装不了。 于是改在命令行运行。 运行后,发现提示少了一些依赖包,于是运行下面的命令:sudo apt-get -f ins
-
在沙发床中搜索或通过elasticsearch河
问题内容: 我了解我们可以在沙发上创建视图,然后进行搜索。另一个有趣的方法是通过河将couchdb与elasticsearch连接,然后在elasticsearch中进行搜索。我有两个问题: 就磁盘空间使用而言,elasticsearch会更有效吗? 与使用ouchddb顶部的elasticsearch相比,使用couchdb搜索的利弊是什么? 谢谢! 问题答案: 在磁盘使用方面: https:/
-
使用elastic4s在搜索中获得零结果
问题内容: 这是我用来进行简单搜索的一小段代码: 这是我得到的结果: 创建索引并将文档添加到该索引运行良好,但是简单的搜索查询没有任何结果。我什至在Sense上检查了这一点。 给 如何解决这个问题? 问题答案: 我怀疑正在发生的事情是您在代码中的索引操作之后立即进行搜索。但是,在Elasticsearch中,文档尚未准备好立即进行搜索。请参阅此处的刷新间隔设置。(因此,当您使用其余客户端时,由于必
-
全文搜索和200M +记录的数据库
问题内容: Iam将创建一个包含至少2亿个条目的庞大数据库。该数据库需要使用全文本进行搜索,并且应该是快速的。 我的数据库从许多不同的数据源获取数据,我需要定期导入新数据或更新数据。 将我的所有数据存储在诸如mysql之类的关系数据库中,然后创建一个nosql文档数据库(例如mongodb或elasticsearch)只是出于搜索目的,还是在可靠性和预防方面没有任何好处,这是一个好主意吗?多余的信
-
根据单词索引更改搜索顺序
问题内容: 有什么方法可以增加文档开头的用语吗?例如,我有3个文档。 XXX应该在搜索词“ Sulpher”的顶部列出,因为那是该文档中的第一个单词。如果YYY列在顶部,则可以,因为与XXX相同。但是ZZZ应该永远是最后一个。换句话说,在“左侧”找到的术语应比在“右侧”找到的术语具有更高的优先级。 问题答案: 您可以通过小写标准化术语位置来提高: 然后 屈服
-
用于elasticsearch中的通配符搜索的ngram
问题内容: 我正在尝试为最终用户提供搜索类型,这更像sqlserver。我能够为给定的SQL场景实现ES查询: 在ES中,我使用ngram tokenizer来达到预期的结果: 所以,如果我的文档行像 上面的查询只显示了两个文档,但是当我尝试输入Peter sims或Peter simson时,除非我输入Peter tomson robert sims或Peter tomson robert si
-
Hazelcast:搜索结果较大时缓慢/阻塞
我们看到缓慢/阻塞 我已经启用了一个慢速操作检测器来记录耗时超过1秒的慢速操作。运行搜索时未检测到慢速操作,因此服务器端的查询执行速度应该更快。 将客户端套接字缓冲区大小从32 kb增加到1024 kb。性能没有改善 我正在使用Hazelcast便携式序列化。Hazelcast版本3.11。 我正在使用IMap。getAll以获取多个对象。Hazelcast慢速运行检测器能够检测耗时超过1秒的查询
-
弹性搜索中无节点可用异常
我对弹性搜索概念非常陌生。我试图建立一个简单的应用程序使用弹性搜索。 我的类看起来像, 谢谢你。
-
C在一组区间内有效搜索值
假设我有一组由成对描述的间隔。我想找到所有包含给定值的区间集。 我制定了这个在O(n)时间内有效的解决方案,作为我追求的一个例子: 找到所有可能的集合非常重要,而不仅仅是一个。 我现在正在寻找一种计算效率更高的解决方案,可能在对数时间内。我认为可能有多集/多映射、lower_bound/upper_bound等解决方案,但迄今为止我还没有任何成功。 这可以通过使用区间树来实现,但我相信可能有一个解
-
散列如何具有o(1)搜索时间?
问题内容: 当我们使用a 来存储数据时,据说搜索需要o(1)时间。我很困惑,有人可以解释吗? 问题答案: 好吧,这 只是 个谎言-可能需要更长的时间,但通常不会。 基本上,哈希表是一个包含所有要搜索的键的数组。每个键在数组中的位置由 哈希函数 确定, 哈希函数 可以是始终将同一输入映射到同一输出的任何函数。我们将假设哈希函数为O(1)。 因此,当我们在哈希表中插入内容时,我们使用哈希函数(将其称为
-
详细描述一下Elasticsearch搜索的过程?
本文向大家介绍详细描述一下Elasticsearch搜索的过程?相关面试题,主要包含被问及详细描述一下Elasticsearch搜索的过程?时的应答技巧和注意事项,需要的朋友参考一下 面试官:想了解ES搜索的底层原理,不再只关注业务层面了。 解答: 搜索拆解为“query then fetch” 两个阶段。 query阶段的目的:定位到位置,但不取。 步骤拆解如下: 1)假设一个索引数据有5主+1
-
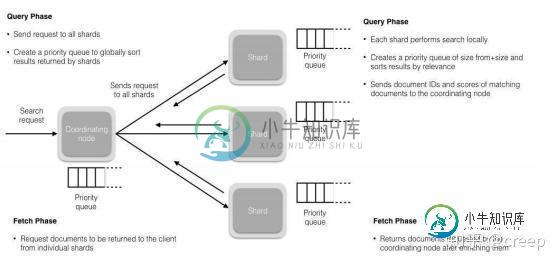 详细描述一下 Elasticsearch 搜索的过程?
详细描述一下 Elasticsearch 搜索的过程?本文向大家介绍详细描述一下 Elasticsearch 搜索的过程?相关面试题,主要包含被问及详细描述一下 Elasticsearch 搜索的过程?时的应答技巧和注意事项,需要的朋友参考一下 1、搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch; 2、在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为
-
如何对淘宝搜索框进行测试
本文向大家介绍如何对淘宝搜索框进行测试相关面试题,主要包含被问及如何对淘宝搜索框进行测试时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 一, 功能测试 输入关键字,查看: 返回结果是否准确,返回的文本长度需限制 1.1输入可查到结果的正常关键字、词、语句,检索到的内容、链接正确性; 1.2输入不可查到结果的关键字、词、语句; 1.3输入一些特殊的内容,如空、特殊符、标点符、极限值等,可引入