《搜狐畅游》专题
-
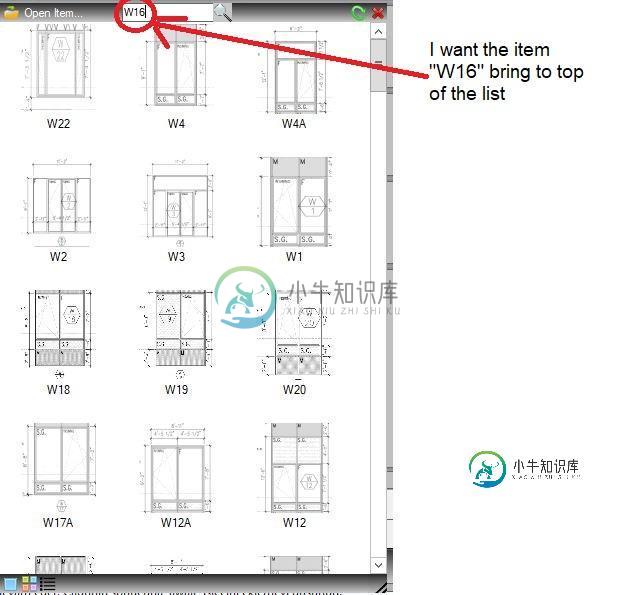 C#ListView搜索项不带清除列表
C#ListView搜索项不带清除列表我有一个C#平台上的winform项目。我有listview和textbox,如下图所示。我想根据用户输入的文本值对列表重新排序。 我在这里询问之前研究过,我通常会看到基于删除和重新添加所有单元到listview的解决方案。我不想这样做,因为我的listview有太多带图片的项目,所以删除和重新添加项目会导致listview工作缓慢。 我想要的是,当用户在文本框中输入字符时,以这些字符开头的项目,
-
如何在arraylist中搜索项目?[副本]
我正在创建一个gui,可以添加、删除和搜索用户输入的名称。我想知道允许我在arraylist中搜索项目的代码。非常感谢。
-
子查询的弹性搜索和聚合
我知道elasticsearch允许子聚合(即嵌套聚合),但是我想对“第一次”聚合的结果应用聚合(或者在通用的任何查询中-聚合与否)。 具体示例:我记录有关用户操作的事件(为简单起见,我有带有和的文档)。我可以进行查询,计算每个用户执行的操作数量。但是我想找出“活跃用户”的百分比(或计数)(例如,执行了10个以上操作的用户)。理想的结果是所有用户的直方图,显示用户的活跃程度。 有没有办法创建这样的
-
在AngularJS中实现搜索:默认方式
我已经在我的angularjs应用程序中实现了默认搜索,代码如下: 我在这里面临的问题是,假设有人碰巧触发了某个关键字,而这些关键字在被重复的记录中并不存在。我想要一条消息,说“什么也没找到”或者别的什么。 我如何实现这个逻辑?我在这里看了不同的文章和几个问题,找不到这方面的任何东西。我如何查看搜索的术语的长度是否为零,以便我可以ng-如果那个东西并显示消息?谢谢!
-
异步搜索promise不按顺序解析
我这里的问题是,获取promise在当前文本之前创建了几个字符,然后在最后创建的promise之后解析。我需要解决的最后一个promise的最新或取消以前的promise时,我改变了文本。 我希望结果总是最新的。 我查找了一些搜索栏示例,但什么也没找到。 我很确定解决方案是保存以前的promise,如果在你创建一个新promise时它仍然悬而未决,就取消它,但是我不知道如何取消promise。 谢
-
如何从NEST连接到弹性搜索
我目前正在运行elastic search和kibana 7.0.0版,在我的项目中有一个docker compose文件 我能够连接到端口5601上的kibana(索引和搜索数据),以及端口9200上的弹性搜索。 我试图使用NEST连接到弹性这里是我的基本配置 当我通过NEST执行任何命令时,如ping、健康检查或搜索等,我检索到以下异常。这让我相信docker容器(linux容器)中存在一些与
-
递归二叉搜索树删除方法
首先,这是家庭作业,所以把它放在外面。 我应该用特定的方法实现二叉查找树: void insert(字符串)、boolean remove(字符串)和boolean find(字符串)。 我已经能够成功地编程和测试插入,并找到方法,但我有困难与删除。 我的程序中发生的事情是,删除实际上并没有从树中删除任何东西,我相信这是因为它只引用当前节点的本地创建,但我可能错了。我认为我可以实现我需要测试的不同
-
spring数据弹性搜索与const_分数
我需要运行以下查询: 但我不能用spring data elasticsearch轻松运行这个。 有什么办法吗 spring data elasticsearch是否很好地支持所有elasticsearch查询DSL
-
搜索文本文件的不确定性
朋友们,我有一段代码,它读取文本文件并搜索匹配的单词,但在搜索文本文件时存在不确定性。有时它能够匹配单词,有时它不能,尽管单词存在于文本文件中。 代码如下: 以下是我的文本文件内容: 有人知道为什么会这样吗?假设我在文本文件中添加一个单词“finish”,然后搜索它,它总会找到它。但是,如果我的搜索词是“dadas”或“dadist”,则在et中生成null。
-
大文件中最高效的搜索-Python
我正在大文本文件中搜索匹配项,但我发现它太慢了。这是文件结构: 我正在尝试匹配第一列的文本,我想提取第二列的值。列之间用\t隔开,大约有1000万行。用不同的单词多次搜索文件。什么搜索方法的时间效率最好? 编辑:文件大小为129 Mb,将被搜索至少数千次。EDIT2:文件是按字母顺序排序的,只有当单词有不同的大写字母时,它们才能出现多次。例如:单词都是不同的条目。
-
Spring boot server启动问题弹性搜索
我正在使用elasticsearch7。5、我已打开以下属性 我已经生成了API密钥来将我们的springboot连接到elasticsearch。我正在使用 我的所有请求都来自“RestHighClient”,并且能够触发请求。唯一的问题是在服务器启动期间,它们是一些无法连接到Elasticsearch的错误。 在pom中。xml 在应用程序属性中: 有人能给我提个建议吗,我怎样才能解决它。
-
POJO列表中的弹性搜索结果
目前,我正在将弹性搜索命中映射到POJO,然后再次将其保存在列表中。 是否有一种方法可以直接将弹性结果映射到内容POJO列表,而无需从Search Hit迭代它。
-
将弹性搜索结果转换为POJO
我有一个使用spring数据elasticsearch库的项目。我的系统返回了结果,但我想知道如何以域POJO类的形式获得结果。 我没有看到太多关于如何实现这一点的文档,但我不知道应该在谷歌上搜索什么正确的问题。 目前,我的代码是这样的,在我的测试中,它检索正确的结果,但不是作为POJO。 非常感谢您的帮助。
-
使用Dict的Python深度优先搜索
我一直看到深度优先搜索的伪代码,它与我的具体问题之间的关系完全让我感到困惑。我试图确定一个“有向图”是否是强连通的。 如果我有一个包含2个字符串的dict(第一个表示源,第二个表示目的地)和一个表示边缘权重的可选数字: 如何实现DFS的某些元素?我知道我可以从一个顶点“奥斯汀”开始,而“休斯顿”是另一个顶点。但我不明白这些在Python代码中是如何工作的 我只是很难看到这种从伪代码到代码的转换。感
-
二进制搜索树的删除方法
我正在一个实验室工作,该实验室要求我为二进制搜索树创建一个删除方法。这是我的remove方法的代码。 运行代码时得到的输出是: 移除90后的树。70 80 85 98 100 120 移除70. 80 85 98 100 120后的树 移除85后的树。80 98 100 120 移除98后的树。80 100 120 移除80后的树。100 120 移除120后的树。100 移除100后的树。100