《数据分析面试》专题
-
 秋招大数据面试记录
秋招大数据面试记录#数据人的面试交流地# 2022/09/30 闻泰科技 大数据开发 一面: 为什么当程序员? 加班接受? 家人愿意让你去深圳发展吗? 职业规划 mysql: 索引了解吗 性别适合做索引吗,经常改变的字段适合做索引吗 MySQL的锁 事务的四大特性 事务内增删查改的语句是按顺序执行的吗 视图是什么 数据是怎么存储的 hive:hive在hdfs上的存储格式 怎么看hive表的存储路径 show ta
-
 CVTE电话面试–数据挖掘
CVTE电话面试–数据挖掘没看到cvte有什么产品岗,所以瞎投了数据挖掘,结果笔试都没有,早上忽然打电话要电话面试。 什么都没准备就这样去浪费hr时间了。 主要还是聊简历上的项目,很喜欢问xx和xx的区别,但项目不会全问,只问了我介绍的那个。 然后问了一些编程和数据库的基础知识,但我大脑一片空白,回答得稀烂,尴尬到脚趾抓地只想赶紧结束。 全程持续了二十六分钟,面试官人很nice,不会过度刁难,希望凉掉吧不要再有技术二面了?
-
 2024腾讯面试数据岗位
2024腾讯面试数据岗位#软件开发2024笔面经# 0)项目中遇到哪些问题? 1)业务数据采集框架选择(FlinkCDC,Maxwell,Canal) 2)Dwd 层新老访客修复、Dws层用户回流状态过大,选择状态后端不合理导致OOM3)状态后端选择 RocksDB导致链路延迟过高 4)Dws层读取外部数据库维度数据网络延迟过高导致反压 5)数据倾斜导致的反压 6)Flink SQL 未设置 TTL 导致的 OOM 7)
-
 阿里云数据开发面试
阿里云数据开发面试#软件开发2024笔面经# 阿里云数据开发岗位面试公司名称:阿里云 面试岗位:大数据开发 整个是大数据开发,我以为是数仓开发,结果问的全是Spark问题,被搞自闭了。1,自我介绍 2,park中RDD的Task数量由什么决定?3,Spark怎么实现算子中的变量共享?4,Spark共享变量的使用条件? 5,可序列化?连接池实例是在算子内还是在算子外? 我一开始没想好,先回答了连接池的作业:是为了连接
-
 大数据实时实习面试
大数据实时实习面试1.自我介绍 2.你对redis宕机后的方法 我:...... 3.你说到算法。你有刷过letcode算法? 我:很少刷letcode,一般都是刷sql的 3.kafka的副本同步 我:忘了 4.谈谈你对数仓的理解 我:..... 5.谈谈你对hbase和clickhouse的理解 我:.... 6.你说你对hive中的ads层数据导入到MySQL,为什么不是直接从hive的ads层中访问 我:不
-
 5.9荣耀面试数据开发
5.9荣耀面试数据开发一个小姐姐打电话告诉我会议号的。 进去之后,先自我介绍,然后让我讲项目。 hdfs的读写机制 雪花模型星型模型的区别和适用场景 小文件的弊端 又在问项目 20分钟结束了,反问环节都没有。。。
-
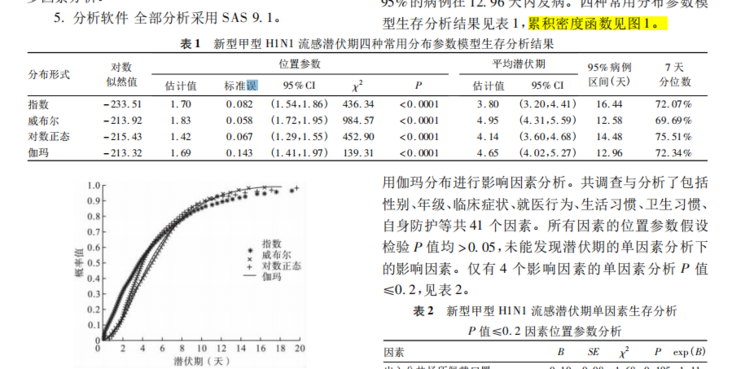 程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?
程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?SAS生存分析LIFEREG做区间删失数据(如潜伏期)的参数分布后,对于得到的各类参数分布模型,怎么估计潜伏期的百分位数呢? 比如这篇文献,右边的潜伏期百分位数数据怎么得到呀??? 还有参数分布的累积密度分布函数?/? 求大佬带带
-
 兴业数金 数据开发 一面 二面
兴业数金 数据开发 一面 二面#兴业数金一面 ,二面 #数据开发 #23校招 9.23二面(糟心) 全程不看屏幕,全程听不到说啥,全程氛围尬住 1.介绍自己,balabala 2.说说你对数金的了解(他笑了,你知道还挺多) 3.说说你的优势(声音巨小) 4.上个面试咋样 我???那个面试,我,,,那个???? 然后把一面给他复述一遍 5.还记得你的笔试题吗 鬼才记得 6.记得笔试的编程题吗
-
 蚂蚁-风险策略分析师-一二三面面经(oc)
蚂蚁-风险策略分析师-一二三面面经(oc)背景 中流双9本硕,有段银行的风控建模实习 一面 简历深挖: 你在什么样的部门,主要做什么样的项目?这个项目目标是什么?然后你在里面做的工作内容是什么? 产出报告的质量怎么判断,结果包括对业务的思想是什么? 评分A卡的样本选择,怎么做违约定义,怎么抽样,好坏样本 最后的业务结果和价值? 还有一些问题,记不太清了,总之算是比较挖简历细节和延伸思考。 场景题: 套现对于用户和商家角度分别如何防控 有地
-
 JS函数节流和函数防抖问题分析
JS函数节流和函数防抖问题分析本文向大家介绍JS函数节流和函数防抖问题分析,包括了JS函数节流和函数防抖问题分析的使用技巧和注意事项,需要的朋友参考一下 问题1:如果实现了dom拖拽功能,但是在绑定拖拽事件的时候发现每当元素稍微移动一点便触发了大量的回调函数,导致浏览器直接卡死,这个时候怎么办? **问题2:**如果给一个按钮绑定了表单提交的post事件,但是用户有些时候在网络情况极差的情况下多次点击按钮造成表单重复提交,
-
C++ 虚函数和纯虚函数的区别分析
本文向大家介绍C++ 虚函数和纯虚函数的区别分析,包括了C++ 虚函数和纯虚函数的区别分析的使用技巧和注意事项,需要的朋友参考一下 首先:强调一个概念 定义一个函数为虚函数,不代表函数为不被实现的函数。 定义他为虚函数是为了允许用基类的指针来调用子类的这个函数。 定义一个函数为纯虚函数,才代表函数没有被实现。 定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函
-
 AngularJS中一般函数参数传递用法分析
AngularJS中一般函数参数传递用法分析本文向大家介绍AngularJS中一般函数参数传递用法分析,包括了AngularJS中一般函数参数传递用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了AngularJS中一般函数参数传递用法。分享给大家供大家参考,具体如下: 1. 模型参数 直接使用变量名,不要加引号 2. 普通参数 加上引号即可 将上面的value改为 'value' 就会直接弹出 value了 希望本文所述对大
-
使用Apache Spark和Java将CSV解析为数据帧/数据集
我是spark的新手,我想使用group by 我想简化关于CSV,按部门分组,指定,国家,附加列总和(成本到公司)和总员工计数 结果应该是: 有什么方法可以使用转换和操作来实现这一点。或者我们应该进行RDD操作?
-
9.24 解析与分析Python源码
问题 你想写解析并分析Python源代码的程序。 解决方案 大部分程序员知道Python能够计算或执行字符串形式的源代码。例如: >>> x = 42 >>> eval('2 + 3*4 + x') 56 >>> exec('for i in range(10): print(i)') 0 1 2 3 4 5 6 7 8 9 >>> 尽管如此,ast 模块能被用来将Python源码编译成一个可被分
-
nodeJS与MySQL实现分页数据以及倒序数据
本文向大家介绍nodeJS与MySQL实现分页数据以及倒序数据,包括了nodeJS与MySQL实现分页数据以及倒序数据的使用技巧和注意事项,需要的朋友参考一下 大家在做项目时肯定会遇到列表类的数据,如果在前台一下子展示,速度肯定很慢,那么我们可以分页展示,比如说100条数据,每10条一页,在需要的时候加载一页,这样速度肯定会变快了。 那么这里我给大家介绍如何在nodejs环境中用mysql实现分页