《不内卷》专题
-
内存不足
我正在努力解决古老的字谜问题。多亏了许多教程,我能够迭代一组字符串,递归地找到所有的排列,然后将它们与英语单词列表进行比较。我发现的问题是,在大约三个单词之后(通常是关于“变形”之类的东西),我会得到一个OutOfMemory错误。我试着把我的批分成小的集合,因为它似乎是消耗我所有内存的递归部分。但即使只是“变形”也把它锁起来了... 编辑:根据出色的反馈,我已经将生成器从排列更改为工作查找: 它
-
nodejs内存不足
问题内容: 我今天遇到一个奇怪的问题。对于其他人来说,这可能是一个简单的答案,但这让我感到困惑。为什么下面的代码会导致内存错误? 我得到了这两个错误之一…第一个是在节点的解释器中运行此代码时,第二个是通过nodeunit运行它时: 严重错误:CALL_AND_RETRY_2分配失败-内存不足 严重错误:JS分配失败-内存不足 问题答案: 当我尝试访问阵列时会发生这种情况。但是获取长度却没有。
-
RecycerView内部ViewPager内部scrollview不工作
我有一个xml布局,它有以下视图:滚动视图->Relationvelayout->Some views+Tablayout+ViewPager->RecylerView(在ViewPager的片段中)。ViewPager有一些固定的高度(保持它“wrap_content”根本不会显示它)。现在的问题是Recylerview永远不会滚动。我已经尝试了几个已经发布的解决方案,比如在“嵌套滚动视图”中包
-
Node.js堆内存不足
问题内容: 今天,我运行了用于文件系统索引编制的脚本,以刷新RAID文件索引,并在4小时后崩溃并出现以下错误: 服务器配备16GB RAM和24GB SSD交换。我非常怀疑我的脚本是否超过了36gb的内存。至少不应该 脚本使用文件元数据(修改日期,权限等,无大数据)创建存储为对象数组的文件索引 过去,我曾经用此脚本经历过奇怪的节点问题,这使我不得不这样做。在处理诸如String之类的大文件时,由于
-
PyTorch GPU内存不足
我正在PyTorch中运行一个评估脚本。我有许多经过训练的模型(*.pt文件),我将其加载并移动到GPU,总共占用270MB的GPU内存。我使用的批量大小为1。对于每个示例,我加载一个图像并将其移动到GPU。然后,根据样本,我需要运行一系列经过训练的模型。有些模型以张量作为输入和输出。其他模型的输入是张量,输出是字符串。序列中的最终模型总是有一个字符串作为输出。中间张量临时存储在字典中。当模型使用
-
Eclipse STS-内存不足
STS不断崩溃,项目文件夹中的日志如下: 它始于我使用Winmerge比较和修改STS之外的java、pom和属性文件时
-
堆内存不足,java
我是刚到爪哇的。我只是试图了解如何处理堆内存溢出及其原因。有人能在下面的代码中帮助我为什么它会抛出这个错误吗。我怎么能避免。 错误: 线程“main”Java.lang.OutOfMemoryError中出现异常:Java.util.arrays.copyof(arrays.Java:2361)在Java.lang.AbstractStringBuilder.ExpandCapacity(Abst
-
Storm 2.0.0内存不足
我将代码库从1.1.1升级为使用storm 2.0.0。现在我观察到,如果我在本地模式下运行拓扑,几分钟后它就会耗尽内存。 [THREAD ID=AsyncLocalizer执行器-2-EventThread]Dev-APC180-本地o. a. s. s. o. a. z.ClientCnxn错误,同时调用监视器java.lang.OutOfMemoryError:无法创建新的本机线程在java
-
node.js堆内存不足
我已经经历了奇怪的节点问题在过去与这个脚本迫使我。在处理像String这样的大文件时,node会出现故障,将索引拆分为多个文件。有什么方法可以改进nodejs的内存管理与庞大的数据集?
-
node.js不得不说的12点内容
本文向大家介绍node.js不得不说的12点内容,包括了node.js不得不说的12点内容的使用技巧和注意事项,需要的朋友参考一下 1.node.js,服务器端的javascript,它允许在后端(脱离浏览器环境)运行javascript代码。 2.事件驱动、异步式I/O的编程模式(单线程)是其核心。 3.node.js的javascript引擎是v8,来自google chrome项目。V8号称
-
RecyclerView得内容不可见
我正在尝试创建一个ListView,它的每一行都是一个水平滚动列表。早些时候,我使用的是HorizontalScrollView,但我需要一个可以回收视图的布局。所以我使用了RecyclerView,但是现在RecyclerView的内容不可见了。 下面是我的垂直ListView适配器: 下面是我的水平回收视图适配器: 下面是ListView行的布局: 当我使用HorizontalScrollVi
-
NetBeans内存不足错误
问题内容: 我是Netbeans中这种错误的新手。我一直在使用Java Bean 8.0.2在Java J2SE中工作。我正在对字符串进行模糊搜索,通常字符串长度为300-500。我正在使用Levenshtein和Jaro Winkler算法来查找字符串之间的距离。大约有1500次迭代来查找字符串之间的距离!问题是我的Net Bean通常会为以下内容提供错误: 我已经在线进行了一些搜索来摆脱此错误
-
内容不能为null laravel
我正试图提交一份表格,但出现了此错误 查询异常在Connection.php647行:SQLSTATE[23000]:完整性约束违反:1048列内容不能为空(SQL:插入到(,,,,)值(主, , [], 2017-03-28 11:10:58, 2017-03-28 11:10:58)) 内容应该可以为空。 我的迁移表 我的存储方法
-
pyspark-Kafka流-内存不足
我正在尝试使用此代码使用代理版本0.10测试kafka流。这只是一个打印主题内容的简单代码。还没什么大不了的!但是,由于某种原因内存不足(VM中的10GB RAM)!代码: 运行火花提交: 不幸的是,结果是: java.lang.OutOfMemoryError:Java堆空间 我假设Kafka每次应该带一小部分数据来避免这个问题,对吗?那么,我做错了什么?
-
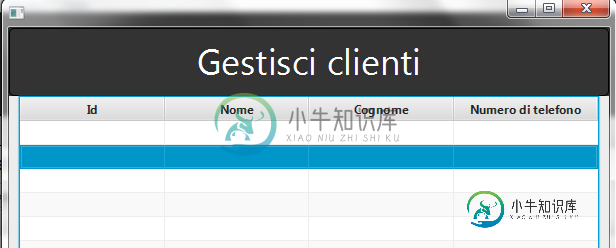 JavaFX TableView不显示内容
JavaFX TableView不显示内容我试图在TableView中插入一些值,但它不显示列中的文本,尽管这些列不是空的,因为有三行(与我在TableView中插入的条目数量相同)可单击。 我有一个类“ClientIController”,它是fxml文件的控制器,这些是TableView和TableView的列的声明。 我在initialize()方法中调用了一个名为loadTable()的函数,该函数将内容添加到TableView中