《数据挖掘》专题
-
 编写Ruby脚本来对Twitter用户的数据进行深度挖掘
编写Ruby脚本来对Twitter用户的数据进行深度挖掘本文向大家介绍编写Ruby脚本来对Twitter用户的数据进行深度挖掘,包括了编写Ruby脚本来对Twitter用户的数据进行深度挖掘的使用技巧和注意事项,需要的朋友参考一下 Twitter以及一些API 尽管早期的网络涉及的是人-机器的交互,但现在的网络已涉及机器-机器之间的交互,这种交互是使用web服务来支持的。大部分受欢迎的网站都有这样的服务存在——从各种各样的Google服务到Linked
-
3.2 GPU挖矿
硬件 该算法是内存困难的,为了将DAG安装到内存中,每个GPU需要1-2GB的RAM。如果你遇到Error GPU mining. GPU memory fragmentation?,那就意味着你内存不足 GPU挖矿也在OpenCL中实现,因此AMD GPU将比同类NVIDIA GPU“更快”。ASIC和FPGA相对效率低下,因此不鼓励。 要获得openCL的芯片组和平台,请尝试: AMD SDK
-
挖矿原理
在比特币的P2P网络中,有一类节点,它们时刻不停地进行计算,试图把新的交易打包成新的区块并附加到区块链上,这类节点就是矿工。因为每打包一个新的区块,打包该区块的矿工就可以获得一笔比特币作为奖励。所以,打包新区块就被称为挖矿。 比特币的挖矿原理就是一种工作量证明机制。工作量证明POW是英文Proof of Work的缩写。 在讨论POW之前,我们先思考一个问题:在一个新区块中,凭什么是小明得到50个
-
 比特币矿挖掘
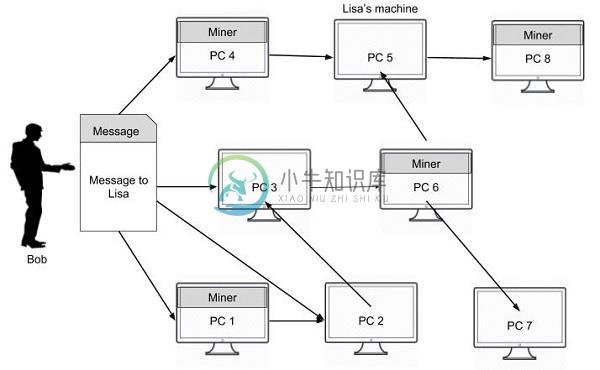
比特币矿挖掘主要内容:比特币挖掘,比特币矿工的角色,比特币区块链是如何建造的?要了解比特币矿工的作用,我们首先了解比特币挖掘。 比特币挖掘 比特币挖掘是将交易记录添加到比特币过去交易的公共分类账的过程。过去交易的分类账称为区块链,因为它是一系列区块。比特币挖掘用于保护和验证交易到网络的其余部分。 示例 当Bob为Lisa创建购买请求时,他不会单独将其发送给Lisa。请求消息在他所连接的整个网络上广播。Bob的网络以图像形式描绘。 消息将传递到所有连接的节点(计算机)。图中的
-
挖掘 FreeRADIUS 的 man page
下面的命令可以被用来指导首先决定哪些FreeRADIUS包被安装了和临时决定包中包含哪些文件. dpkg系统 显示所有FreeRADIUS安装的包: $> dpkg -l | grep radius 使用
-
 顺丰-大数据挖掘与分析工程师-一二三面面经(oc)
顺丰-大数据挖掘与分析工程师-一二三面面经(oc)一面 简历面,如果过往实习项目由机器学习等,比较关心其中数据预处理和特征处理,没有问coding和模型延伸问题(八股) 二面 对于项目中涉及的某个优化算法特别感兴趣,深挖概念、流程、优点、公式等 (第一次也是目前唯一被问到这个细节,真的要对简历熟悉) 压力大的时候喜欢干什么 hr面 为什么想来深圳 深圳还投了哪些公司 十一前发意向 总体觉得顺丰的问题难度很看分配到的面试官,和身边同学交流,有的就会
-
数据挖掘 - 58同城url无规律变化,是一种反爬措施吗?
我在爬58同城的招聘数据时,发现在同一页面从第二页转到第三页时,url中不仅页码部分从2变到3,还有一部分以“PGTID=”开头的内容,一直发生无规律变化,因此只通过修改Url中页码部分无法和浏览器一样遍历不同页,请问这是一种什么情况呢?会对爬虫有影响吗?请问该如何解决这个问题 例如:58同城招聘北京地区护士招聘第二页url为 https://bj.58.com/nhushi/pn2/?fullP
-
 2022暑期实习-面试-顺丰科技-大数据挖掘与分析工程师
2022暑期实习-面试-顺丰科技-大数据挖掘与分析工程师公司:顺丰速运集团(顺丰科技) 岗位:大数据挖掘与分析工程师 形式:视频面试 视频面试平台:赛码 初试 面试官:所在组的大数据挖掘与分析高级工程师 时长:15分钟 流程: 0、面试官自我介绍 1、自我介绍 2、看到你简历上写了很多个项目,你觉得哪个项目对你能力提升比较大?可以详细描述一下吗?包括但不限于项目背景、分析过程、最终目标、结果展示等。 3、讲一下机器学习模型和数据挖掘方法在这些项目中的具
-
 百度 机器学习/数据挖掘/自然语言处理工程师 一面面经
百度 机器学习/数据挖掘/自然语言处理工程师 一面面经面试岗位:机器学习/数据挖掘/自然语言处理工程师 面试时间:23/08/14 面试时长:50min 面试内容: 自我介绍 介绍两段实习经历 熟悉哪些机器学习/深度学习/搜广推算法 两道代码题:寻找两个正序数组的中位数;根据字符出现频率排序;(力扣原题) 反问:部门业务;对新人期待/要求:学习能力强、基础:Python离线模型开发、C++在线开发; 总结:面试官对面试者的研究背景较为包容开放,为人和
-
7.1.4填挖方分析
在“分析”菜单栏中点击“填挖方分析”,有绘制多边形和选择面两个选项,这里以绘制多边形为例。 在三维地形上绘制一个指定多边形作为填挖方范围,双击结束绘制,弹出对话框。 首先需要设置所需向下或向上填挖的目标高度,即基准面。在对话框上输入基准面高程值,填挖方分析随着基准面高程值得变化而变化,最后点击“分析”得到填挖方量数据以及分析结果图,分析结果图中紫色区域表示
-
9.2.4填挖方分析
在“分析”菜单栏中点击“填挖方分析”,有绘制多边形和选择面两个选项,这里以绘制多边形为例。 在三维地形上绘制一个指定多边形作为填挖方范围,双击结束绘制,弹出对话框。 首先需要设置所需向下或向上填挖的目标高度,即基准面。在对话框上输入基准面高程值,填挖方分析随着基准面高程值得变化而变化,最后点击“分析”得到填挖方量数据以及分析结果图,分析结果图中紫色区域表示
-
简易挖矿教程
简易挖矿的限制:每个挖矿账户可开启4个挖矿程序,如果有更多机器,请自己先搭建完整节点。专业矿工请先搭建完整节点 当前只支持电脑CPU挖矿 生成钱包,并注册成为矿工 根据自己的情况下载钱包:当前支持安卓、windows(64位)、linux(64位)、mac(64位) 钱包下载,可以下载简易挖矿程序:mining_client 下载/解压后,执行程序,默认会自动生成一个钱包文件 同时在首页上可以看到
-
以太坊私有网络挖掘
1) 我使用以下命令设置一个专用以太坊网络 2) 创建了一个帐户 3)然后,使用miner.start()命令启动矿工。 过了一段时间,以太被自动添加到我的帐户中,但我的私人网络中没有任何挂起的事务。那么我的矿工们从哪里得到乙醚呢? 尽管我没有在我的网络中实例化任何事务,但一旦启动miner,我就可以看到日志中记录了一些事务。 日志如下: 我的创世区块代码如下: 由于我的网络是隔离的,并且只有一个
-
英文文本挖掘预处理
1. 英文文本挖掘预处理特点 英文文本的预处理方法和中文的有部分区别。首先,英文文本挖掘预处理一般可以不做分词(特殊需求除外),而中文预处理分词是必不可少的一步。第二点,大部分英文文本都是uft-8的编码,这样在大多数时候处理的时候不用考虑编码转换的问题,而中文文本处理必须要处理unicode的编码问题。这两部分我们在中文文本挖掘预处理里已经讲了。 而英文文本的预处理也有自己特殊的地方,第三点就是
-
中文文本挖掘预处理
1. 中文文本挖掘预处理特点 首先我们看看中文文本挖掘预处理和英文文本挖掘预处理相比的一些特殊点。 首先,中文文本是没有像英文的单词空格那样隔开的,因此不能直接像英文一样可以直接用最简单的空格和标点符号完成分词。所以一般我们需要用分词算法来完成分词,在文本挖掘的分词原理中,我们已经讲到了中文的分词原理,这里就不多说。 第二,中文的编码不是utf8,而是unicode。这样会导致在分词的时候,和英文