《数据开发工程师》专题
-
API应用开发流程
同样以 blog应用为例 1.在api目录下创建blog目录 blog结构: ├─api 应用目录 │ ├─blog 应用目录 │ │ ├─controller 控制器目录 │ │ ├─lang 多语言包(可选) │ │ ├─logic 逻辑层目录(可选) │ │
-
开发流程规范化
压力测试 脚本在/benchmark中, 需要覆盖到 TCP服务器,代码:tcp.php,监听端口9502 UDP服务器,代码:udp.php,监听端口9502 HTTP服务器,代码:http.php,监听端口9502 WebSocket服务器,代码:websocket.php,监听端口9502 测试脚本 php async.php -c 100 -n 100000 -s tcp://127.0.
-
4.3.6 开发过程小结
4.3.5 开发过程小结 calendar 程序的完整开发过程,展示了自顶向下设计方法的强大能力。当面临一个复杂 问题而感到无从下手的时候,可以尝试将原始问题分解为若干个子问题,然后再去考虑每个 子问题的解决方案。这个分解过程可以重复进行,从结构图的顶层开始,自顶向下逐步求精, 直至得到所有子问题的精确代码。 自顶向下设计过程可以概括为以下四个步骤: (1)将问题分解为若干子问题; (2)为每个子
-
简易的开发教程
PS:该教程以 Visual Studio 2015 为例 前提工作 首先配置好你的开发环境,建立一个Win32动态链接库项目 然后复制Dism++SDK(Dism++目录\Dism++SDK目录中的内容)到你的项目目录,并加入你的解决方案 接下来就应该编写插件配置文件了,详情可以参考本文档的 插件信息文件编写参考 在“空间回收”增加一个自定义的清理项目 然后你可以在cpp文件中根据加入如下代码(
-
 Kibana 插件开发教程
Kibana 插件开发教程这是一本讲述kibana插件开发教程类的书籍,写这本书的时候,还没有深入开发过kibana插件,书中难免会出现各种错误,欢迎大家指正交流。
-
 DApp 开发简短教程
DApp 开发简短教程本教程将引导您制作一个简单的基于以太坊的分布式应用程序。到最后,你将能够进入Parity,选择你的Dapp并在实践中看到它。
-
 Android OpenGL ES 开发教程
Android OpenGL ES 开发教程OpenGL ES 主要用来开发 3D 图形应用的。OpenGL ES (OpenGL for Embedded Systems) 是 OpenGL 三维图形 API 的子集,针对手机、PDA 和游戏主机等嵌入式设备而设计。本教程结合实例由浅入深地讲解了使用 OpenGL ES 进行 3D 图形开发的。
-
 达发一面 系统软件研发工程师
达发一面 系统软件研发工程师达发一面( 系统软件研发工程师 )-当场点名被刷 苏州的达发,本人是23届毕业的本三211硕士,一面记录一下, 9月中旬号投的简历,面试时间是9.19笔试,9.23面试,40分钟。 问题: 1自我介绍 2怼项目 3项目负责的部分讲解,各个框架捋一下 4追问项目中遇到的难题 手撕(字符串压缩)c语言 设计一个简单的压缩功能,对字符串中的重复字符进行计数,并将计数加到该字符后面,如果计数为1, 则不加
-
 已offer|携程大数据分析工程暑期实习
已offer|携程大数据分析工程暑期实习▫️Timeline:3.13投递 - 3.15完成综合考试 - 3.27请求转到第二志愿 - 4.11一面 - 4.21二面 - 4.25HR面+英语测评 - 4.26收offer ▫️bg:美本专业对口,一段相关实习,两个项目(1机器学习,1rfm) ▫️一面(~45mins) - 职业学业规划 - 回国时间&到岗时间&实习时长 - 自我介绍 - 介绍实习内容 - 实习怎么搭建指标体系 - 实
-
 微信公众平台开发 数据库操作
微信公众平台开发 数据库操作本文向大家介绍微信公众平台开发 数据库操作,包括了微信公众平台开发 数据库操作的使用技巧和注意事项,需要的朋友参考一下 一、简介 前面讲解的功能开发都是简单的调用API 完成的,没有对数据库进行操作。在接下来的高级功能开发中,需要使用到数据库,所以在这一篇中,将对MySQL 数据库的操作做一下简单的介绍,以供读者参考。 二、思路分析 百度开发者中心提供了强大的云数据库(包括MySQL, Mongo
-
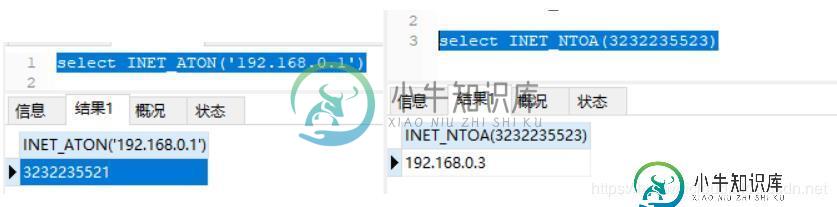 MySQL数据库开发的36条原则(小结)
MySQL数据库开发的36条原则(小结)本文向大家介绍MySQL数据库开发的36条原则(小结),包括了MySQL数据库开发的36条原则(小结)的使用技巧和注意事项,需要的朋友参考一下 前言 这些原则都是经历过实战总结而成 每一条原则背后都是血淋淋的教训 这些原则主要是针对数据库开发人员,在开发过程中务必注意 一、核心原则 1.尽量不在数据库做运算 俗话说:别让脚趾头想事情,那是脑瓜子的职责 作为数据库开发人员,我们应该让数据库多做她所擅
-
web开发中添加数据源实现思路
本文向大家介绍web开发中添加数据源实现思路,包括了web开发中添加数据源实现思路的使用技巧和注意事项,需要的朋友参考一下 在web开发中,可以利用hibernate配置数据源,但在实际的应用中,可能要连接多个数据源, 1.配置dataSource 2.配置sessionFactory 3.添加jdbc支持 感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
 字节大数据开发实习一二HR面
字节大数据开发实习一二HR面5/5一面 5/14 二面 5/18 hr面 5/19 OC 一面(1h10min) 1.自我介绍一下 2.介绍一下你的项目 2.1 Mysql全量数据规模 2.2 既然Mysql能存储,为什么要导入到hive中 3.说一下MySQL的ACID特性 4.脏读和幻读分别是什么含义 5.spark持久化的级别和作用 6.spark任务出现数据倾斜有哪些方法解决 7.hive没办法创建分区怎么理
-
 荣耀大数据开发岗-面试官有病
荣耀大数据开发岗-面试官有病大概是今年五月初面试了荣耀大数据的Java开发港,面试官全程基本什么都没有问。也没有问一些八股文的问题,也没有问算法题。 就是轻蔑地看了一眼我的简历,然后问你的项目是自己做的,还是根据别人的来做的,然后直接说你做的这个项目怎么这么简单,因为我还有一个机器学习的项目,然后他就随便问了项目做什么的。 最离谱的是他说你有机器学习的经历,那么我推荐你去客户端。 总之全程什么技术问题都没有问你,也没有问项目
-
 陌陌—数据平台开发—提前批面经
陌陌—数据平台开发—提前批面经7.12号 一面:60分钟 1. 自我介绍 2. 选一个你觉得做的最好的项目进行介绍,然后逐个问简历上写的该项目的每个技术点(项目大概问了30分钟) 3. Hadoop组件你熟悉那个(回答MapReduce和HDFS) 4. HDFS的读写流程说一下 5. 如果HDFS写的过程中DataNode宕机了会怎么办?(回答了一台DataNode宕机的处理机制) 然后追着问:如果所有的DataNode都