《数据开发工程师》专题
-
 数据开发 - 面经 - 来未来(医疗大数据)
数据开发 - 面经 - 来未来(医疗大数据)2024.1.9 面试 Boss直聘沟通 公司要求驻场开发,接受加班,接受出差 你是25届是吧?能在六个月左右是吗?目前在校吗? 后续有什么规划? 你怎么理解数据开发这个岗位的? 讲讲简历上这两个项目?是你在学校做的是吧? 项目你是全程参与是吧? 聊天这个项目的数据源是哪里来的呀? 项目整体是落在HDFS上是吧? 单一架构,嗷,然后可视化,是哇? 下一个电商项目介绍一下? 数据来源讲讲? 那意思是
-
数据科学家,数据工程师,数据分析师之间的区别。
本文向大家介绍数据科学家,数据工程师,数据分析师之间的区别。,包括了数据科学家,数据工程师,数据分析师之间的区别。的使用技巧和注意事项,需要的朋友参考一下 数据科学家,数据工程师和数据分析师是信息技术公司中的各种职位档案。 数据科学家 数据科学家是一个非常特权的工作,负责监督整体功能,提供监督以及对信息,数据的未来显示的关注。 数据工程师 数据工程师专注于技术优化,以所需格式构建数据等。 数据分析
-
 摩尔线程c++软件开发工程师一二面(已oc)
摩尔线程c++软件开发工程师一二面(已oc)9.21 摩尔线程一面 讲一讲两种字节序 如何判断大端还是小端字节序 讲一讲联合体的空间占用特点 修改其中一个成员的值,其他变量会受影响吗 讲一讲malloc和new的区别 new和malloc需要指定申请的字节数吗 讲一讲sizeof sizeof一个指针是什么结果 为什么32位的指针是4个字节 指针和引用的区别 都有什么类型创建的时候必须初始化吗 传参传引用和传指针的区别 讲一讲socket编
-
 网易互娱大数据研发工程师面试经验分享
网易互娱大数据研发工程师面试经验分享本人社招,面试大数据研发工程师岗位,一共三轮面试。 1、一面(技术面),约40分钟,面试题如下: (0)自我介绍,别照着简历说,补充说些简历上没有的,比如哪里人、兴趣爱好、优势有哪些等。 (1)笔试,编程题,语言自选,题目:输入一个字符串,找出其中的整数,按升序排序后输出,多个相连的数字为一个整数,排序可用类库自带方法。 实现很简单,这里就不提供答案了。 (2)笔试,SQL编程,
-
 23秋招 补录 阿里 数据研发工程师 面经 已offer
23秋招 补录 阿里 数据研发工程师 面经 已offer准备面试过程中搜数据开发岗面经还是费了点劲的 所以在此记录一下攒人品 之后各位uu能多一点参考 背景 阿里的数据研发(不是大数据研发)校招的时候对技术要求不高比较随意 所以我这种数据分析岗位背景的人简历也是秒过 还有蚂蚁的某些数据开发也是这样的 之前找过我说现有的技术栈没问题 但我因为自我感觉不行+对数据分析的执着给拒了!!大家不要学我可以多看看机会 数据分析岗位基本趋于饱和 只看大公司+数据分析
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:CTO线-数据产品与技术部 岗位:数据研发工程师 形式:电话面试 时长:22分钟 流程: 1、自我介绍。 2、介绍一下实习的工作。 3、这个项目中有几个人? 4、在项目中遇到了什么困难? 5、实习的公司有没有类似数据中台的部门? 6、在数据预处理方面做了哪些事情?怎么保障数据的规范性和准确性? 7、介绍一下建模的工作。 8、学校里有没有学过数据挖掘相关的课程? 9、对于分类和
-
 2023暑期实习-面试-蚂蚁集团-数据研发工程师
2023暑期实习-面试-蚂蚁集团-数据研发工程师公司:蚂蚁集团 部门:信贷事业群-风险管理部 岗位:数据研发工程师 形式:电话面试 时长:31分钟 流程: 1、自我介绍。 2、对数据开发岗有了解吗? 3、实习的时候接触到的数据来自哪里? 4、你是怎么理解数据仓库这个岗位的? 5、你刚才提到了数据沉淀,那你觉得有哪些方法来做数据沉淀? 6、如果让你做数据ETL的话你有兴趣吗? 7、对大数据的技术栈哪些比较熟悉? 8、传统的数据仓库和关系型数据库有
-
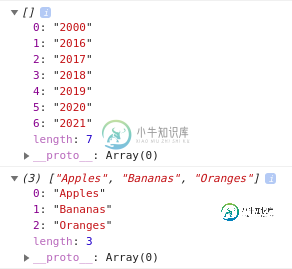 Chrome开发工具中的不同数组
Chrome开发工具中的不同数组为什么 Chrome 开发工具在水果数组前面放了一个“(3)”,而不是年份数组? 第一个是这样获取的结果: 第二个只是这样的测试:
-
 25届日常实习面试 - 数据开发 & 后端开发
25届日常实习面试 - 数据开发 & 后端开发字节跳动 - 数据研发 一面(40min) 学过的数据结构,并分别讲下它们的特点 进程和线程的区别 TCP和UDP的区别 JAVA的面向对象的三大特性,并详细介绍应用场景 MySQL的事务隔离级别 MySQL的binlog的运用 数据仓库的的特点、数据治理 范式建模、维度建模 Hive内外部表的使用场景 HQL底层执行逻辑 Hive数据存储在哪,分区和分桶的区别 Sort by 和 Order b
-
 兴业数金数据工程师笔试 凉凉
兴业数金数据工程师笔试 凉凉先说下专业,不是专门学计算机的,是数学院信息与计算科学 上个月快月底的时候投了数据分析的简历,过了两天一看,“笔试名单筛选中”,又过了两天,“未通过”,好家伙直接没了,所以就没管了 但是前几天突然收到了笔试的通知,但是“数据工程师” 看了下别人的笔试经验发现是有选择有编程,编程是sql 我确实会sql,但是有段时间没接触了,于是昨天练了一整晚,回忆了个七七八八 想着早点考早超生,今晚就给考了 看到
-
 数禾科技(数据应用工程师)一面
数禾科技(数据应用工程师)一面1. 自我介绍 2. JAVA并发包了解吗 3. JVM垃圾回收机制 4. Spring循环依赖 5. Mybatis一级缓存二级缓存 6. Mysql深分页 7. MySQL索引有哪些 8. MySQL事务隔离级别 9. Redis 缓存雪崩,缓存穿透 10. 了解大数据组件吗,Hadoop,HIVE
-
 TCL实业 大数据工程师 面经
TCL实业 大数据工程师 面经9.11 一面 35min: 1.自我介绍 2.专业介绍 3.Mysql索引 4.Mysql事务并发导致的问题 5.Mysql两种引擎的对比 6.Hadoop运行模式 7.job tracker 作用 8.Hdfs小文件问题 9.Hadoop调度器 10.Hadoop脑裂出现的原因 11.Kafka 怎样保证不丢数据 12.Flink task和subtask 的区别 13.并行度和slot的关系
-
 数据分析建模工程师面经
数据分析建模工程师面经1.自我介绍 2.实习项目拷打 3.场景题,有一万条数据,但有一个类只有条数据,训练时要注意什么,我:构造数据;增加查全率。面试官:从模型方面讲讲。我:加入正则化项。面试官:损失函数的权重。 4.一个项目,反例比较少,选择一个模型评估方法。没答上来。面试官说AUC曲线,让我说说原因。也猜到了要答AUC曲线跟数量无关,但是有点印像,画曲线的时候是要使用正例反例数量的,不敢说话,疯狂道歉。 5.SQL
-
Google云数据流工作线程
-
 奇怪的csig数据工程timeline
奇怪的csig数据工程timeline一面 09.05 1h多 1.自我介绍 2.实习内容 3.指标建设与数仓的对应关系 4.指标怎么管理的 5.指标报警怎么设置 6.你会怎么管理所有指标体系 7.手撕 重复字符串 二面 09.07 接近2h 1.自我介绍 2.数理知识:拉格朗日函数、贝叶斯函数的损失函数,对缺失值的影响,卡方与t与z检验的区别 3.大数据相关:mapreduce中map task与reduce task个数、hive