《欢聚时代》专题
-
时间
C-c C-d 设定截止日期(DEADLINE);C-c C-s 设定计划(SCHEDULED): C-c .在当前位置插入一个时间戳: 时间标记都会显示在日程表的本周事件中: C-c . 插入时间戳;如果连续插入两个时间戳,则插入一个时间范围 C-u C-c . 更加精确的时间戳,在日程表中以时间线显示 C-c ! 插入时间戳,不在日程表中显示 C-c < 直接插入时间戳(当前日期) C-c >
-
时间戳。getTime()将时间戳值视为系统时区中的时间
假设我有一个时间戳值。 编辑 现在我正在使用获取上述时间的毫秒值; 根据Java文档,getTime()方法的定义是
-
SELECT查询是否总是以相同顺序返回行?具有聚集索引的表
问题内容: 我的查询是否总是以相同的顺序返回数据库表中的行? 我的表的一列上有一个“聚集索引”。这会改变答案吗? 问题答案: 返回的行的顺序将 不会 总是相同的,除非你明确地与状态,这样的条款。所以不行。 和不; 仅仅因为您的1000个查询返回的顺序相同,所以 不能 保证第1001个查询的顺序相同。
-
Networkx:将所有节点最短路径长度之和作为一个聚合值获取
我是NetworkX的初学者,我试图找到一种方法,将图中一个节点到其他节点的所有最短路径值汇总为一个聚合值,例如,节点B的长度为6,如下面代码的结果所示。我得到了图中所有节点对之间的最短路径,但是我需要帮助将每个节点的长度添加为一个值,如上所述。任何帮助都将不胜感激。下面是计算最短路径长度的代码。我编辑了这个问题,以便获得单个节点的节点密度值,如下面的代码所示。
-
默认情况下,SQL Server是否在表的所有列上创建非聚集索引
问题内容: sql server将创建任何默认的非聚集索引吗?我们真的应该将所有FK都作为非聚集索引吗?这里的权衡是什么 问题答案: 否,SQL Server不会自动创建非聚集索引。 除非您的声明另有说明,否则将基于主键自动创建聚簇索引。 是的,我会建议索引外键列,因为这些是最容易被JOIN’d /搜索不要使用,等等。但是,要知道,在低基数的设定值(性别为例)的指标会比较没有用,因为值之间没有足够
-
洗牌矢量元素,使得两个相似的元素最多聚在一起两次
为了举个例子: 我有一个名为vec的向量,包含10个1和10个2。我试图随机安排,但有一个条件,两个相同的值不能在一起超过两次。 到目前为止,我所做的是使用randperm函数生成vec的随机索引,并相应地洗牌vec。这就是我所拥有的: 我的代码随机排列vec元素,但不满足两个相似值最多出现两次的条件。我该怎么做?有什么想法吗?
-
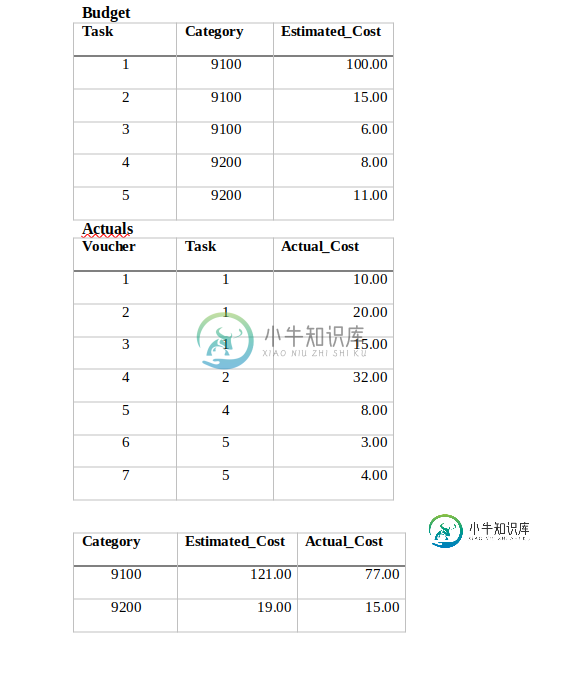 如何使用最新MYSQL版本的left join和两个聚合函数来获取组
如何使用最新MYSQL版本的left join和两个聚合函数来获取组我试过这样做,但无法得到结果,我只能得到一个列与类别,而不是两个在同一时间。 这是我用过的: 而且
-
如何构建聚合管道,根据其他文档中的字段值过滤文档?
如果文档集合包含: 我想构建一个聚合,通过我的myDocRefId字段只返回没有被任何其他文档引用的文档。对于这个集合,我想返回: 文档1在聚合中被删除,因为文档3具有对它的引用。 如何在聚合管道中实现这一点?
-
Kafka流——有可能减少由多个聚合创建的内部主题的数量吗
我有一个Kafka Streams应用程序,它可以根据几个值对传入的消息进行分组。例如: 示例消息: 拓扑: 这导致了很多话题: 如果我们可以将多个聚合发送到单个状态存储,并将group by value作为密钥的一部分,那就太好了。例如: 这将导致主题少得多: 这在目前看来是不可能的(无论如何使用DSL),因为使用操作符会创建一个用于重新分区的内部主题,所以如果我们有多个子拓扑不同的东西,那么K
-
解析DateFormat时的Java时区
问题内容: 我有解析日期的代码,如下所示: 一切正常,突然,这停止了。原来,管理员在服务器上进行了一些配置更改,并且当前返回的日期为“ 2010-12-27T10:50:44.000-08:00”,上述模式无法解析该日期。我有两个问题: 第一种是哪种模式将解析上述格式的JVM返回的日期(特别是时区为“ -08:00”)?其次,在Linux RHEL 5服务器上,究竟会在哪里更改此类设置,以便我们将
-
Waitpid等同于超时时间?
问题内容: 想象一下,我有一个启动几个子进程的进程。父母需要知道孩子何时离开。 我可以使用,但是如果/当父母需要退出时,我无法告诉被阻塞的线程正常退出并加入它。自己清理一下是很高兴的,但可能没什么大不了的。 我可以与结合使用,然后在任意时间睡眠以防止繁忙的等待。但是,那时我只能知道孩子是否经常离开。就我而言,知道孩子何时立即离开可能并不重要,但我想尽快知道… 我可以为使用信号处理程序,并在信号处理
-
时间到一天的时间
问题内容: 我有一个时间戳记,我想知道是否有办法在PST中将其舍入到一天的开始。例如,ts:对应于,但是我想将其舍入为一个映射到的时间戳。我读了time.Time文档,但没有找到解决方法。 问题答案: 执行此操作的简单方法是使用上一个创建新内容,并且仅分配年份的月份和日期。看起来像这样; 这是一个表演例子;https://play.golang.org/p/jnFuZxruKm
-
标准时间和夏时制
在美国,有诸如和这样的时区,在夏时制期间,它们是和,而当夏时制不生效时,它们是和。 那么,既然夏令时从3月的第二个星期日开始,到11月的第一个星期日结束,那么说3月到11月之间的日期是在还是是无效的吗?例如,以下日期在技术上是否不存在? 它不应该是,还是仅仅是,以避免必须指定或?
-
时区相等的Postgres时间
问题内容: 我在Postgres的平等问题上遇到了麻烦。 平等的工作方式与我期望的一样,如果在对时区进行归一化之后,如果时间相同,那么它应该为真: 但是,似乎不适用于以下情况: 但是,不平等在我期望他们如何实现的过程中起作用: 我有什么误会吗?如何以与平等相同的方式处理时区来评估平等? 问题答案: 以下是两种评估平等的方法: 在 第一个 将它添加到一个。该 第二 通过使用构建体。 但不要使用。曾经
-
 JavaScript电子时钟倒计时
JavaScript电子时钟倒计时本文向大家介绍JavaScript电子时钟倒计时,包括了JavaScript电子时钟倒计时的使用技巧和注意事项,需要的朋友参考一下 本文实例讲解了JavaScript电子时钟倒计时的详细代码,分享给大家供大家参考,具体内容如下 JavaScript时间类 1、获取时分秒: getHours() getMinutes(); getSeconds(