《实战》专题
-
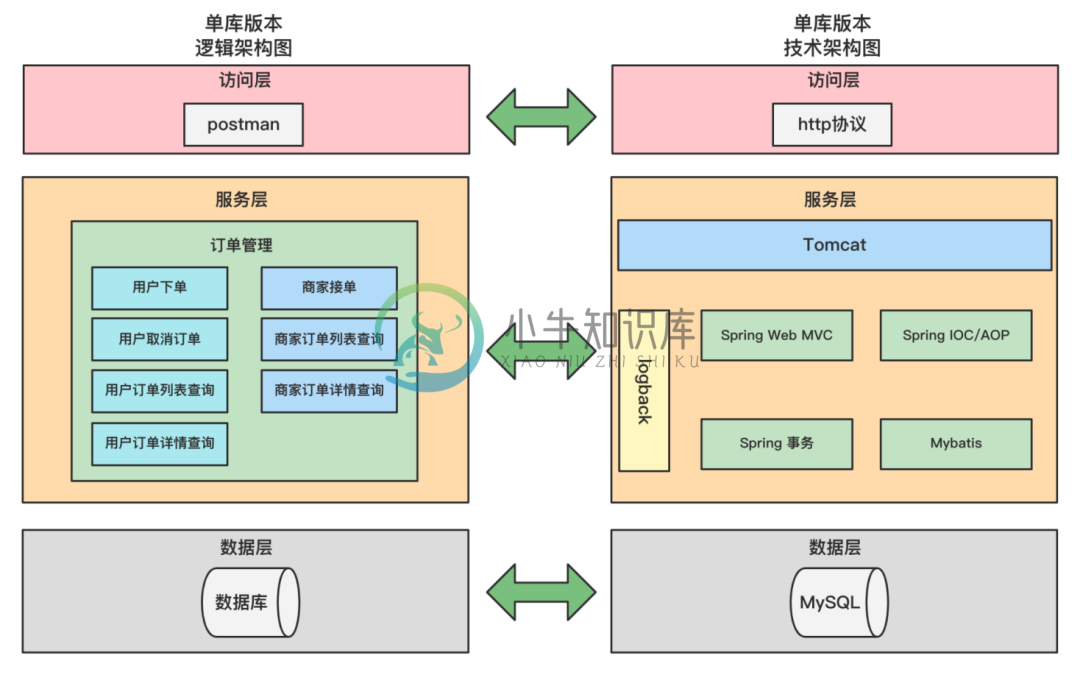 基于订单系统的分库分表实战
基于订单系统的分库分表实战主要内容:前 言,认识一下单库版本的订单系统,业务快速增长,驱动系统架构不断演进,来看一下分库分表版本的订单系统架构,结束语前 言 各位读者朋友,大家好,这是分库分表实战的第一篇文章,首先介绍一下"基于ShardingSphere的分库分表实战"的设计思路及内容。 本实战的重点是分库分表实战,比较适合1~3年工作经验的程序员朋友。实战主要以外卖APP中的外卖订单来作为本次实战的核心业务。 基于外卖订单业务,儒猿技术团队开发了一个外卖订单项目,通过该项目逐步分析随着订单数据量逐步增加,系统将遇到什
-
第九章 HBASE实战 - 副录-HBase资源收集
Apache HBase™ 参考指南
-
第九章 HBASE实战 - 5.使用管理工具
每个人都希望自已的HBASE管理员能够让集群运行流畅,存储大量的数据,并且能同时,迅速和可靠地处理几百万的并发请求.对于管理员来说,让HBASE中海量数据一直保持可存取,易管理和便于查询是一项至关重要的任务. 除了对于你运行的集群要有扎实的了解之外,你所使用的工具也同样重要.HBASE自带了一些管理工具,它可以使管理员的工作变得轻松一些.HBASE带有一个基于WEB的管理页面.在此页面中可以查看集
-
第九章 HBASE实战 - 3.基本数据迁移
概述 将数据移到Hbase的方法有以下几种: 使用Hbase的Put API 使用HBase的批量加载工具 使用自定义的MapReduce方法 使用HBase的Put API是最直接的方法.这种方法的使用并不难学,但大多数情况下,它并非总是最有效的方法.特别是在有一大批数据需要移入Hbase并且对移入都是问题又有限定的情况下,这种方法的效率并不高.我们需要处理的数据通常都有很大的数据量,这可能也是
-
第九章 HBASE实战 - 2.整合SQL引擎层
NOSQL(Not only SQL 非关系型数据库)的特性之一是不使用SQL作为查询语言,本节简单介绍NOSQL定义,为何NOSQL 上定义SQL引擎,以及现有基于HBASE的SQL引擎的具体实现 NOSQL是不同于传统关系型数据库的数据库系统的统称.两者有很多显著的不同点,其中最重要的是NOSQL不使用SQL作为查询语言.其数据存储可以不需要固定的表格模式,也经常会避免使用SQL的JOIN操作
-
第九章 HBASE实战 - 1.HBASE基于Java开发
使用Java操作HBASE(增删查改) package com.chu; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseCon
-
《Selenium2自动化测试实战–基于Python语言》
发展历程: 《selenium_webdriver(python)第一版》 将本博客中的这个系列整理为pdf文档,免费。 《selenium_webdriver(python)第二版》 加入的单元测试框架unittest,用其组织和运行测试用例, 5元。 《selenium_webdriver(python)第三版》 整合和HTML测试报告的生成,初步形成测试架构的雏形, 8元。 《seleniu
-
Selenium实战:.Net下的自动化测试搭建
这篇文章,其实我酝酿了好一阵子。作为一个开发人员,搞这个事情总归有点狗拿耗子的感觉。各位看官手下留情,西红柿和鸡蛋留着回去炒个菜别朝我来。博客我不常写,至于文笔……大家忍忍就过去了。 话说Selenium这东西出来很长时间了,我开始接触的时候已经是2.0发布以后的事情了。纵观国内,Selenium及其相关资料大多在Java领域有所耳闻,至于.Net的资料,国内大体是很少的。作为坚定的.Net
-
高并发业务接口开发思路(实战)
高并发业务除了需要有支撑高并发的服务器架构,还需要根据业务需求和架构体系,设计出合理的开发方案, 这里根据一个实践过业务场景分析开发思路,罗列出高并发接口需要注意的点,以及设计上的巧思,共勉之,望共鸣 业务场景 业务: 今日好货 交互端: IOS/Andorid 需求点:(实际业务会复杂些,为了容易理解,这里简化需求点) 提供最新的好货商品信息列表,支持分页 需要时时获取最新的商品数据列表,以下情
-
实战Kaggle比赛:狗的品种识别(ImageNet Dogs)
我们将在本节动手实战Kaggle比赛中的狗的品种识别问题。该比赛的网页地址是 https://www.kaggle.com/c/dog-breed-identification 。 在这个比赛中,将识别120类不同品种的狗。这个比赛的数据集实际上是著名的ImageNet的子集数据集。和上一节的CIFAR-10数据集中的图像不同,ImageNet数据集中的图像更高更宽,且尺寸不一。 图9.17展示了
-
 GRUB2 配置文件 grub.cfg 详解 / GRUB2 实战手册
GRUB2 配置文件 grub.cfg 详解 / GRUB2 实战手册GRUB2 的环境变量大致可以分为两类,第一类是自动设置的变量,也就是这些变量的初始值由 GRUB2 自动设置,其值必定存在且不为空。
-
第八章 实战演练:todos 分析(三)总结
在前两篇文章中,我们已经对这个todos的功能、数据模型以及各个模块的实现细节进行了分析,这篇文章我们要对前面的分析进行一个整合。 首先让我们来回顾一下我们分析的流程:1. 先对页面功能进行了分析;2. 然后又分析了数据模型;3. 最后又对view的功能和代码进行了详解。你是不是觉得这个分析里面少了点什么?没错,就知道经验丰富的你已经看出来了,这里面少了对于流程的分析。这篇文章就对整体流程进行分析
-
06 路由中间件 链路追踪(Jaeger)实战
概述 首先同步下项目概况: 上篇文章分享了,路由中间件 - Jaeger 链路追踪(理论篇),这篇文章咱们接着分享:路由中间件 - Jaeger 链路追踪(实战篇)。 这篇文章,确实让大家久等了,主要是里面有一些技术点都是刚刚研究的,没有存货。 先看下咱们要实现的东西: API 调用了 5 个服务,其中 4 个 gRPC 服务,1 个 HTTP 服务,服务与服务之间又相互调用: Speak 服务,
-
 蔚来后端开发实习生(五战)75min挂
蔚来后端开发实习生(五战)75min挂1.自我介绍 2.coding 堪比上次momenta的道格拉斯-抽稀算法,出了个差不多类似的,只不过从节点,到线段那些都得自己定义 有bug没调试通 3.项目经历 3.1 关注架构的设计,还关注架构是不是自己提的 4.实习 4.1 你认为有技术难点的工作 5.java 5.1 java线程有哪些状态 5.2 怎么开启多线程 5.3 讲讲对锁的了解 5.4 讲讲AOP 5.5 讲讲配置刷新 5.6
-
 四战腾讯实习之腾讯视频三面
四战腾讯实习之腾讯视频三面🕒 岗位/面试时间 后台开发/ 40min 👥 面试题目 1. 项目相关场景题 2. 项目中数据库表的结构为什么这么设计 3. 高并发访问时避免冲突的方法 4. 有哪些种锁 5. golang中互斥锁与读写锁都是什么有什么区别 6. 多台机器加读写锁有什么问题 7. 分布式锁 8. 对golang中context的理解 9. 看过golang源码库吗 10. 为什么学golang 11.自己的