《大数据开发》专题
-
php微信公众号开发(2)百度BAE搭建和数据库使用
本文向大家介绍php微信公众号开发(2)百度BAE搭建和数据库使用,包括了php微信公众号开发(2)百度BAE搭建和数据库使用的使用技巧和注意事项,需要的朋友参考一下 微信越来越火,今天开始学习微信公众号开发,在开发之前,假如你已经了解PHP知识和HTML/css等技术。 1.申请微信公众号:地址https://mp.weixin.qq.com/ 注册前需要手拿身份证照片半身像,保证身份证信息看清
-
 汇量科技数据平台开发实习一面二面HR面已offer
汇量科技数据平台开发实习一面二面HR面已offer本人大四研0。感觉这次面试是本人经历的面试以来最有难度的一次,Mobvista看网上风评很好,希望疫情赶紧好起来,我想去实习了。 11.02 一面(1h) 1.自我介绍 2.项目介绍 3.货拉拉实习工作 4.docker镜像分层以及核心原理 5.HBase预分区、rowkey设计原则 6.是否了解spark on k8s,说的不太懂k8s 7.描述下spark on yarn的任务调度流程(clu
-
二次开发 - 常用数据表说明 - dede_flinktype|友情链接网站类型
dede_flinktype|友情链接网站类型: 字段 类型 整理 属性 Null 默认 额外 id mediumint(8) UNSIGNED 是 NULL 链接类型ID typename varchar(50) utf8_general_ci 是 类型名称
-
如何在没有索引的大熊猫中转置数据框?
问题内容: 可以肯定,这非常简单。 我正在读取一个csv文件并具有数据框: 我想换位得到 但是,当我执行df.T时, 如何摆脱最上面的索引? 问题答案: 您可以先将索引设置为数据框中的第一列(或通常要用作索引的列),然后再转置该数据框。例如,如果要用作索引的列是,则可以执行以下操作: 要么
-
如何解决phpmyadmin导入数据库文件最大限制2048KB
本文向大家介绍如何解决phpmyadmin导入数据库文件最大限制2048KB,包括了如何解决phpmyadmin导入数据库文件最大限制2048KB的使用技巧和注意事项,需要的朋友参考一下 解决办法如下: 1、打开php.ini。找到 upload_max_filesize 、 memory_limit 、 post_max_size 这三个参数! (在默认的情况下,php只允许最大的上传数据为2M
-
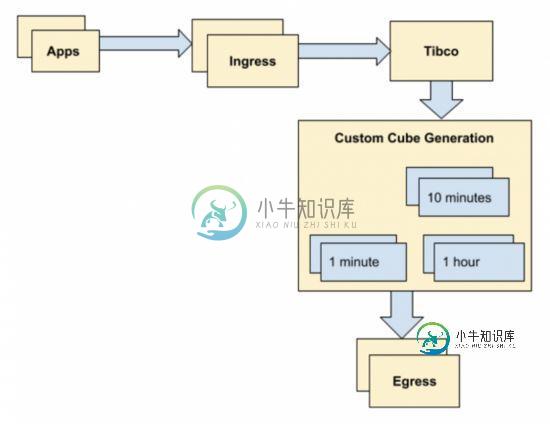 eBay 打造基于 Apache Druid 的大数据实时监控系统
eBay 打造基于 Apache Druid 的大数据实时监控系统本文向大家介绍eBay 打造基于 Apache Druid 的大数据实时监控系统,包括了eBay 打造基于 Apache Druid 的大数据实时监控系统的使用技巧和注意事项,需要的朋友参考一下 首先需要注意的是,本文即将提到的 Druid,并非阿里巴巴的 Druid 数据库连接池,而是另一个大数据场景下的解决方案:Apache Druid。 Apache Druid 是一个用于大数据实时查询和分
-
是否可以限制每个路由的Flask POST数据大小?
问题内容: 我知道可以通过以下方法在Flask中设置请求大小的整体限制: 但是我想确保一个特定的路由将不接受特定大小的POST数据。 问题答案: 你需要检查一下特定路线本身;你可以随时测试内容长度;是一个或整数值: 在访问请求中的表单或文件数据之前,请执行此操作。 你可以将其变成装饰器以供查看: 然后将其用作: 本质上这就是Flask所做的;当你尝试访问请求数据时,在尝试解析请求正文之前,首先检查
-
如何在庞大的数据集(angular.js)上提高ngRepeat的性能?
问题内容: 我有一个巨大的数据集,其中包含数千行,每个行具有大约10个字段,大约2MB的数据。我需要在浏览器中显示它。最简单的方法(获取数据,将其放入,执行其工作)可以很好地工作,但是当它开始将节点插入DOM时,它会使浏览器冻结大约半分钟。我应该如何解决这个问题? 一种选择是将行逐行追加,并等待完成向DOM中插入一个块后再移至下一个。但是AFAIK ngRepeat在完成“重复”操作时不会返回报告
-
流式传输音频时UDP数据包大小/延迟权衡?
我正在构建一个通过udp在线传输实时音频的应用程序,我希望最小化延迟。音频以其生成的速度发送,这意味着生成一秒钟的音频需要一秒钟,发送速度不能超过音频速率。 我最初的想法是发送压缩音频的小数据包,以便客户端可以尽快开始播放。使用Opus编解码器,我应该能够发送5毫秒的音频数据包(最低2.5毫秒),这意味着用户可以很快开始播放,比如说在发送了2个这样的数据包之后。 然而,当使用如此小的分组大小时,会
-
如何加载大量字符串以与oracle数据库匹配?
问题内容: 我目前正在学习PL / SQL,所以我仍然是新手。假设您有一个生产数据库,您可以使用Oracle SQL Developer将其连接到该数据库。您只有该数据库的READ特权。因此,您不能创建或编辑任何表。 我的问题是,如果我有大量的ID,我必须将其与该数据库中的表连接起来,该怎么办? 显然,我可以将ID加载到临时表上,然后进行联接,但这确实很乏味,因为我只有READ特权。硬编码ID也不
-
使用subprocess.Popen时将大量数据通过管道传输到stdin
问题内容: 我有点想了解解决这个简单问题的python方法是什么。 我的问题很简单。如果使用以下代码,它将挂起。子流程模块doc中对此进行了详细记录。 搜索一个解决方案(有一个非常有见地的线程,但是我现在已经迷失了),我发现这个解决方案(以及其他)使用了一个显式的fork: 尽管此解决方案在概念上非常容易理解,但它使用了一个以上的进程,并且与子进程模块相比,其停留在太低的级别(那只是为了隐藏此类事
-
 Python数据可视化常用4大绘图库原理详解
Python数据可视化常用4大绘图库原理详解本文向大家介绍Python数据可视化常用4大绘图库原理详解,包括了Python数据可视化常用4大绘图库原理详解的使用技巧和注意事项,需要的朋友参考一下 今天我们就用一篇文章,带大家梳理matplotlib、seaborn、plotly、pyecharts的绘图原理,让大家学起来不再那么费劲! 1. matplotlib绘图原理 关于matplotlib更详细的绘图说明,大家可以参考下面这篇文章,相
-
PHP实现格式化文件数据大小显示的方法
本文向大家介绍PHP实现格式化文件数据大小显示的方法,包括了PHP实现格式化文件数据大小显示的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现格式化文件数据大小显示的方法。分享给大家供大家参考。具体分析如下: 有时候我们需要在网页上显示某个文件的大小,或者是其它数据的大小数字。 这个数字往往从跨度很大,如果以B为单位的话可能是个位,如果1G则长达1073741824的数字,这
-
在Python中调整图像大小而不会丢失EXIF数据
问题内容: 我需要使用Python调整jpg图像的大小,而又不丢失原始图像的EXIF数据(有关拍摄日期,相机型号等的元数据)。所有有关python和图像的google搜索都指向我当前正在使用的PIL库,但似乎无法保留元数据。我到目前为止(使用PIL)的代码是这样的: 有任何想法吗?还是我可能正在使用的其他库? 问题答案: http://www.emilas.com/jpeg/
-
在Spark数据框列中获取最大值的最佳方法
问题内容: 我正在尝试找出在Spark dataframe列中获得最大值的最佳方法。 考虑以下示例: 哪个创建: 我的目标是在A列中找到最大值(通过检查,这是3.0)。使用PySpark,我可以想到以下四种方法: 上面的每一个都给出了正确的答案,但是在没有Spark分析工具的情况下,我无法确定哪个是最好的。 从直觉或经验主义的观点来看,就Spark运行时或资源使用而言,上述哪种方法最有效,或者是否