《jvm》专题
-
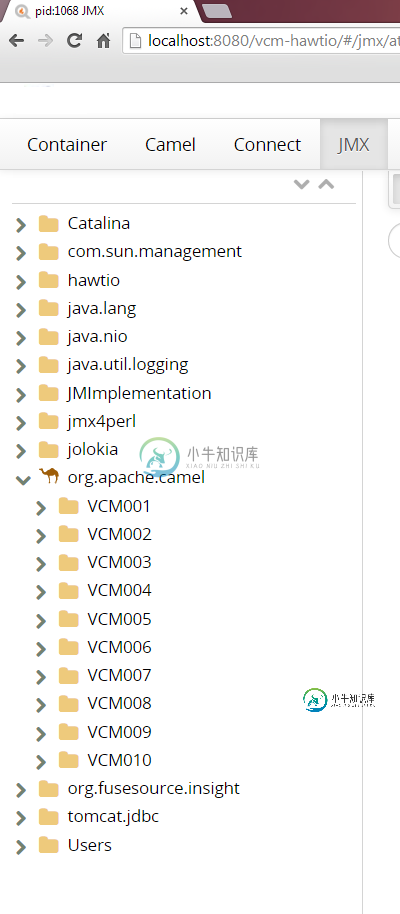 Hawtio:Camel没有在同一个JVM中显示所有实例
Hawtio:Camel没有在同一个JVM中显示所有实例我在与Hawtio相同的JVM中部署了10个Camel组件。 每一个都是唯一的,有不同的ID。 我可以通过JMX视图看到所有10个,但通过“骆驼”视图只能看到9个。
-
.jar文件在IntelliJ中工作,但当.jar在IntelliJ之外运行时,会发生JVM错误
我是Java和堆栈溢出的新手,我在IntelliJ中创建了一个Java项目,并通过构建工件和构建。jar文件创建了一个。jar文件,以便在不使用IntelliJ的情况下运行该项目。该程序使用一个机器人来打开运行窗口,通过按Windows和R键,移动鼠标到我的计算机的分辨率(1366 x 768)的盒子内部,单击,键入cmd并按回车,移动鼠标到cmd窗口内部,单击,键入whoami并按回车。这在In
-
如何从程序中找到JVM版本...甚至更多的细节?
我读过这个,但还不够好! 我的意思是:当我跑的时候 java版本 但是:当我打印这些系统属性时,这样的细节就丢失了!我还没有找到一种编写java代码的方法,可以将稍旧的JVM与较新的JVM区分开来。 长话短说:有没有什么编程方法可以“在我的JVM中”做一些事情,从而给我提供那种级别的细节? (基本上,我需要它来动态禁用我们的一些JUnit测试;它们不能与旧的JVM一起工作;但是我希望在本地ecli
-
在CentOS 6中,JVM总是超过100%的CPU使用率
我在服务器上运行一个Java软件,24小时/天。今天早些时候(在服务器区域设置的午夜后几个小时检测到,这是值得注意的,因为它是本月的第一天),我收到了作为客户端连接到该软件的用户报告,称该软件突然变得不可用。JVM从未被中断或重新启动。它上一次重启是在几天前,从那以后它一直正常运行(使用大约5%或更少的CPU,这是正常的)。 这一次,当我检查该进程时,它实际上是在吞噬它可以从服务器上运行的其他应用
-
为什么不从下一个JVM中删除类型erasure?
Java在Java5中引入了泛型的类型擦除,因此它们可以在Java的旧版本上工作。这是一个兼容性的折衷。从那以后,我们就失去了兼容性[1][2][3]--Bytecode可以在JVM的更高版本上运行,但不能在更早的版本上运行。这看起来可能是一个更糟糕的选择:我们丢失了类型信息,并且仍然无法在旧版本的JVM上运行为较新版本的JVM编译的字节码。怎么了? 具体地说,我想问的是,在JVM的下一个版本中为
-
JVM10规范与不同?
有没有人知道Java10和JVM10规范的版本与以前的版本不同?对于Java8和Java9,有不同的规范,很难看到有什么变化。
-
JVM如何在CPU核之间扩展线程?
所以从一开始:当计算机启动时,引导线程(通常是处理器0中核心0中的线程0)就开始从地址0xFFFFFFF0中提取代码。所有剩下的CPU/核都处于特殊的Hibernate状态,称为等待-SIPI(WFS)。 然后,在OS加载后,它开始管理进程,并在CPU/核之间调度它们,通过高级可编程中断控制器(APIC)向WFS中的每个线程发送一个特殊的处理器间中断(IPI)(启动IPI)。SIPI包含该线程应该
-
了解JVM内存分配和Java内存不足:堆空间
我想真正了解内存分配在JVM中是如何工作的。我正在编写一个内存不足的应用程序:堆空间异常。 我知道我可以传入VM参数,如Xms和Xmx,以增加JVM为正在运行的进程分配的堆空间。这是一个可能的解决方案,或者我可以检查我的代码内存泄漏并修复那里的问题。 我的问题是: 1)JVM实际上如何为自己分配内存?这与OS如何将可用内存传递给JVM有什么关系?或者更一般地说,为任何进程分配内存实际上是如何工作的
-
JVM不会像我说的那样使用那么多内存
我正在运行一个内存密集型应用程序。一些关于环境的信息: 64位debian 13 GB RAM 64位JVM(我的程序运行时输出System.getProperty("sun.arch.data.model"),它说"64") 下面是我发出的确切命令: Java-xmx 9000m-jar " ale . jar " test config 我已经用同样精确的数据、配置等运行了程序。在其他几个系统
-
如何从核心转储文件中提取JVM堆转储?
我正在尝试将Java进程的Linux核心转储转换为堆转储文件,适合用Eclipse MAT进行分析。根据这篇博客文章,适应于较新的OpenJDK 12,我创建了一个核心转储,然后运行将转储转换为HPROF格式: 核心转储文件是22GB,而堆转储文件只有3MB,因此命令可能无法处理整个核心转储。此外,Eclipse MAT无法打开堆转储文件,并显示以下消息:
-
是否有任何方法可以合并并从CuCumber jvm报告中删除重复的测试用例?
在我的自动化项目中,我有两位负责人,如下所示: 主运行程序-执行所有@ui测试标记的测试用例,如果场景失败,target/rerun.txt将填充场景位置(例如features/Dummy.feature:22): 辅助运行程序-从target/rerun.txt重新执行场景: 执行时,会创建两个结果json文件: cucumber.json cucumber_rerun.json Maven C
-
JVM崩溃时hs_err_pidxxx.log文件中错误的rlimit信息
我的问题是:为什么NOFILE不对应于我在系统上设置的值(在limits.conf文件中,它应该是20000)?当我使用与运行jvm的用户相同的用户运行命令ulimit-n时,我有一个不同的值。请注意,显示的堆栈是我在系统上设置的正确值,而不是默认值。JVM运行在AWS C3.Large随需应变实例上。 以下是ulimit-a命令的结果:
-
Kubernetes/Docker中的jvm比独立的jvm更快地耗尽内存
我们正在将JDK 1.8v131 JVM服务器移动到Kubernetes/Docker环境中。 在独立的VM中运行的JVM服务器很少,在运行的Kubernetes/Docker环境中运行的JVM服务器也很少,这两种类型在生产中都有。 在相同的负载下,Kubernetes/Docker JVM内存不足,而VM中的JVM运行良好,没有问题。 我们在VM和容器中运行时使用了完全相同的JVM参数。 有什么
-
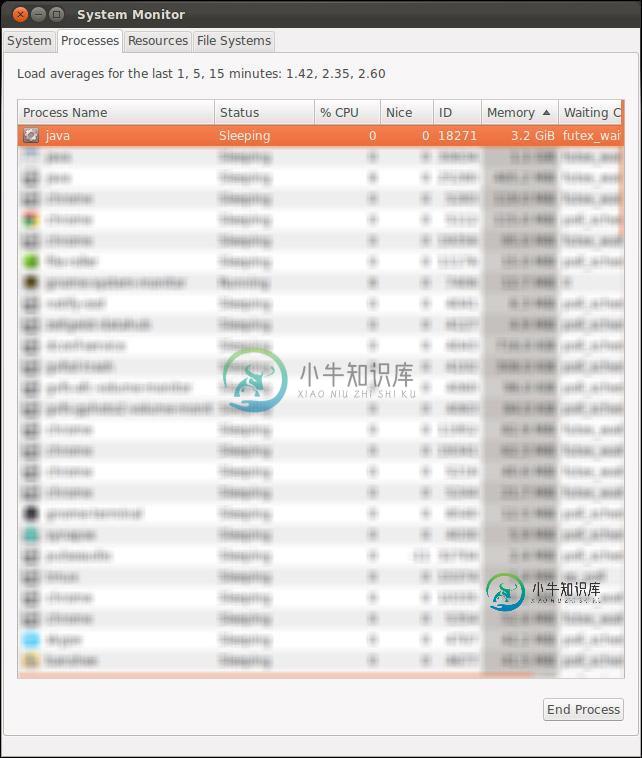 JVM内存使用失控
JVM内存使用失控我有一个Tomcat webapp,它代表客户端执行一些相当大的内存和CPU密集型任务。这是正常的,也是所需的功能。但是,当我运行Tomcat时,内存使用量会随着时间的推移而猛增,达到4.0GB以上,这时我通常会关闭该进程,因为它会扰乱我开发机器上运行的其他所有内容: 我以为我的代码无意中引入了内存泄漏,但在使用VisualVM检查它之后,我看到了一个不同的情况: VisualVM显示该堆占用大约
-
JVM中的-xms和-xmx相等
我有一个Java微服务,它在生产中的内存每天都在增加,我刚刚继承了它。它目前使用了一个4GB堆的80%,并且每天增加几个百分点。 JVM选项中的-xms和-xmx值都设置为4GB。 这是否意味着垃圾收集器在JVM达到其堆限制之前不会激活?