《大管加》专题
-
任务被拒绝由于最大池大小在ThreadPoolExecator
应用程序已配置Zuul和Eureka将请求路由到后端服务,在我们进行负载测试之前,一切正常。 我开始在负载测试环境中执行10个并发请求,在zuul gateway中出现转发错误,原因是线程池无法为未来的任务分配线程,并拒绝任务,错误如下。 我的奇迹;在上面的原因中,我看到池大小只有10个,而10个线程是buzy,很实用,因为我连续触发了10个请求。 但是我的corepoolsize应该比我在这里遇
-
如何大摇大摆地显示WebApi OAuth令牌endpoint
我创建了一个新的Web Api项目,添加了ASP.NET标识并配置了OAuth,如下所示: 谢了。 另外,我应该说Swagger文档对我所有的控制器都适用,只是我忽略了一个明显的方法--如何登录。
-
Spark:连接2个大型DFs时,大小超过Integer.max_value
各位, 当我试图将spark中的两个大型数据流(每个100GB+)连接到每行一个密钥标识符时,我遇到了这个问题。 我在EMR上使用Spark1.6,下面是我正在做的事情: null 我也尝试过使用更大的集群,但没有帮助。此链接表示,如果洗牌分区大小超过2GB,将引发此错误。但是我尝试将分区数量增加到一个很高的值,仍然没有运气。 我怀疑这可能与懒惰加载有关。当我在一个DF上做10个操作时,它们只在最
-
 Azure 函数,缩略图大小大于原始图像
Azure 函数,缩略图大小大于原始图像我已经使用这个带有Azure函数和NodeJS文章的背景图像缩略图处理来创建一个缩略图。已成功创建映像。但是图像的尺寸增加了。这是怎么发生的?它一定很小不是吗?我该如何解决这个奇怪的问题? 这是Blob存储器上的原始图像 处理后(缩略图) 这是 Azure 函数(节点):
-
节点.js - 已超出最大调用堆栈大小
当我运行代码时,Node。js抛出由过多递归调用引起的异常。我试图增加Node。js-stack-size-by,但是node。js崩溃,没有任何错误消息。当我在没有sudo的情况下再次运行时,请选择Node。js打印。有没有可能在不删除递归调用的情况下解决这个问题?
-
mongose-range error:超出了最大调用堆栈大小
我正在尝试将文档批量插入MongoDB(因此绕过Mongoose并使用本机驱动程序,因为Mongoose不支持批量插入文档数组)。我这样做的原因是为了提高写作速度。 我收到错误RangeError: Maximum Call Stack Size Exceeded在console.log(err)在下面的代码: 类似于:https://stackoverflow.com/questions/243
-
反应js:Uncaught RangeError:超出最大调用堆栈大小
React.js用props给后代组件发值错了? 我编写了前面的演示来测试使用向后代组件发送信息。但它导致了错误: 未捕获的范围错误:对象超过了最大调用堆栈大小。克隆元素 但是我在演示运行良好后才写,所以你能告诉我是什么原因导致错误吗?
-
大小>=2的所有子数组中的最大GCD
给定一个数组,编写一个程序以在大小的所有子数组中找到最大 gcd 我的代码: 它是O(N^2),还能再优化吗?
-
大摇大摆的API“必需”-这需要多少钱?
它没有任何问题,没有抛出异常或任何其他迹象。为什么?
-
APK大小V/S已安装应用程序大小
我对飞舞和飞镖语言还不熟悉。在开发了一些示例应用程序后,我从教程中了解到,简单的Tab Layout应用程序在发布后需要7MB用于APK,安装后的应用程序大小为27MB。我的问题如下: APK大小和已安装APP大小有什么区别? 当开发一个应用程序时,无论是本机还是Flutter,我们应该记住APK大小不应该很大,或者安装后的应用程序大小不应该很大? 记住本机和Flutter的所有优点和缺点,开发A
-
字典区分大小写和不区分大小写
我需要一个像
-
 科大讯飞 大数据工程师 一面凉经
科大讯飞 大数据工程师 一面凉经笔试过了一个月给捞起来了 一面 45min 1. 自我介绍 2. 细聊项目,很细(一上来就忘了数据量,尴尬) 3. 特征工程怎么做的 4. iv值的计算方法 5. AUC的计算方法 6. 正反例不平衡对auc有影响吗 7. 知道过拟合吗 8. 逻辑回归怎么解决过拟合问题 9. 写个函数指针 10. pandas库有哪些数据类型 11. 怎么取两个dataframe有差异的部分(忘了具体函数了,讲了
-
大话后端开发的奇淫技巧大集合
模块化设计 根据业务场景,将业务抽离成独立模块,对外通过接口提供服务,减少系统复杂度和耦合度,实现可复用,易维护,易拓展 项目中实践例子: Before: 在返还购APP里有个【我的红包】的功能,用户的红包数据来自多个业务,如:邀请新用户注册领取100元红包,大促活动双倍红包,等各种活动红包,多个活动业务都实现了一套不同规则的红包领取和红包奖励发放的机制,导致红包不可管理,不能复用,难维护难拓展
-
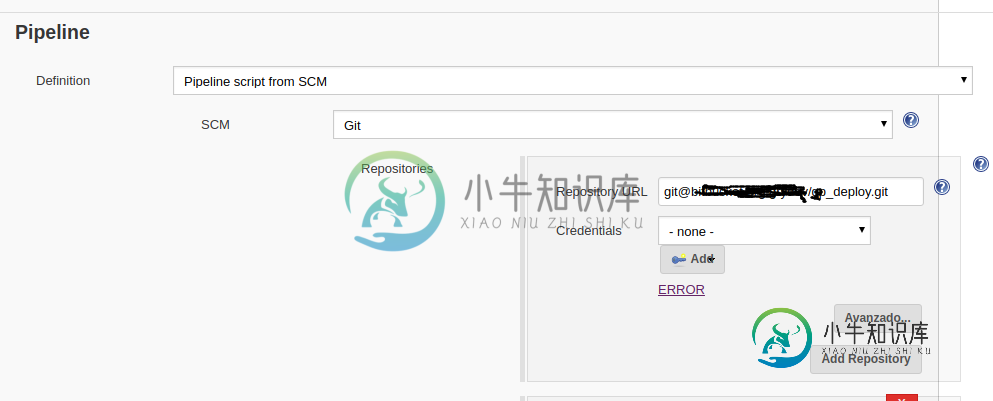 詹金斯管道从不同分支的供应链管理不工作
詹金斯管道从不同分支的供应链管理不工作我在Jenkins的环境中使用管道,该环境已经从SCM配置了管道脚本,然后将groovy文件用于管道中的阶段/作业。此脚本位于主分支中的Bitbucket上。 每次jenkins jobs启动时,它都会调用master branch,它会毫无问题地运行,管道的各个阶段都会运行。 现在,我在bitbucket上创建了一个新分支,并修改了groovy文件以包含更多的步骤(如运行单元测试和其他内容),我
-
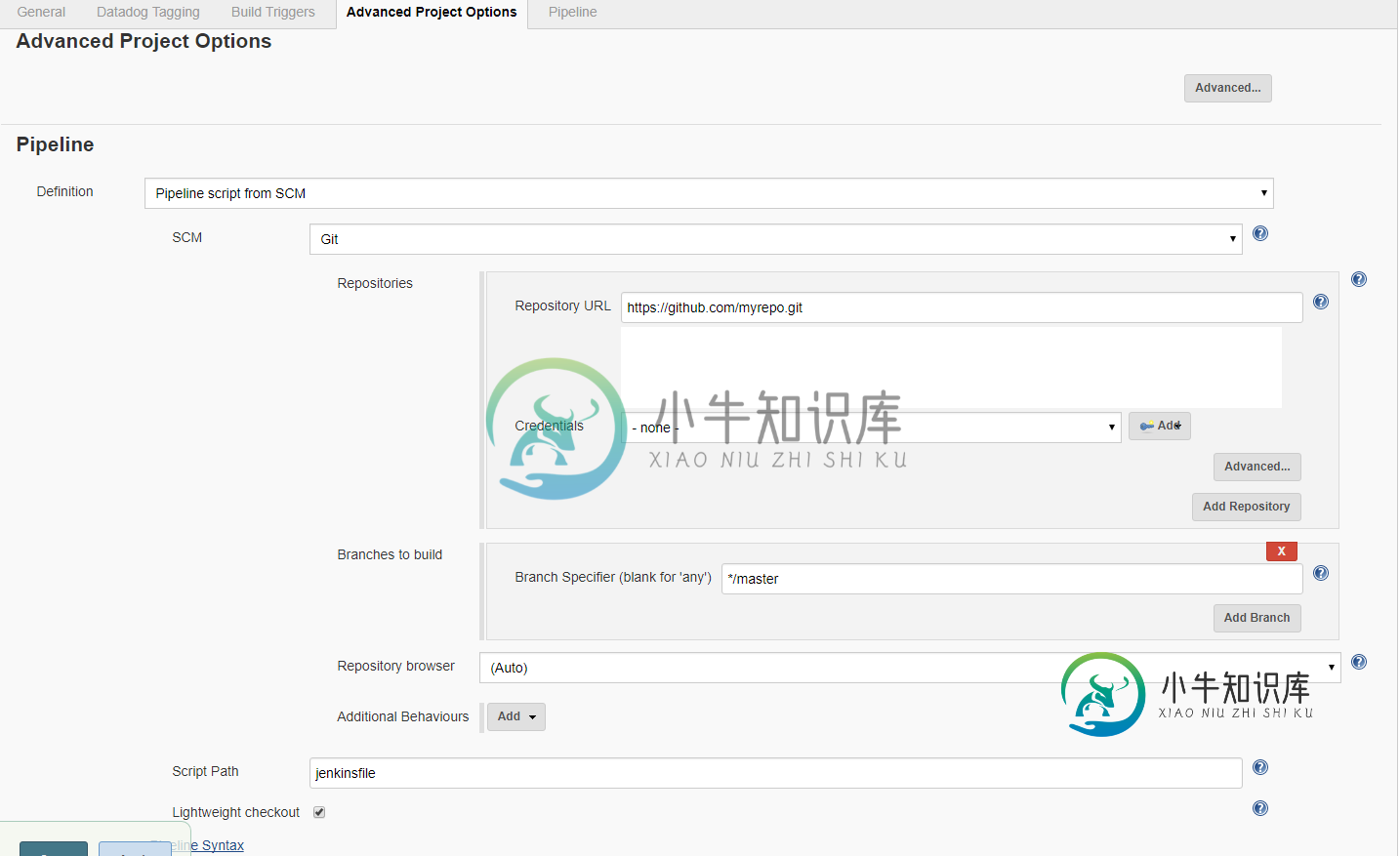 jenkins管道从scm获取管道脚本下的存储库url变量
jenkins管道从scm获取管道脚本下的存储库url变量我正在使用位于git存储库中的Jenkins文件。我已经使用来自scm的管道脚本配置了新作业,该脚本指向我的JenkinsFile。我试图在我的Jenkins file pipeline脚本中使用git模块,以便从我的git repo中提取我的数据,而不需要配置prestatic变量,并且仅仅使用在我的作业中已经配置的scm pipeline脚本下的存储库URL变量。在我的Jenkins管道脚本中