《大管加》专题
-
JDBC有最大结果集大小吗?
JDBC是否有专门从Hive查询放入ResultSet的最大行数?我说的不是获取大小或分页,而是ResultSet中返回的总行数。 如果我错了,请更正,但获取大小设置了jdbc在数据库中每次传递时要处理的行数,并将适当的响应插入到结果集中。当它遍历了表中的所有记录后,它将结果集返回给Java代码。我问返回到Java代码的行数是否有限制。 如果它没有最大行数,则该类是否有任何固有的内容可能导致某些记
-
无法设置HikariCP最大池大小
我使用的是SpringBoot2.0。3释放。我想增加HikariCP的最大池大小,默认情况下为10。 我试着在带有 spring.datasource.hikari.maximum-池-大小=200 但是它不起作用,因为在日志中它仍然显示最大池大小为10。 我想改变的原因是,我不知怎么地达到了登台的极限,我不知道是什么原因造成的。
-
大摇大摆要求所有属性
给定以下架构定义(这是定义所需属性的有效方法):
-
弹性搜索-最大碎片大小
在学习ElasticSearch的过程中,我偶然发现并没有得出最终结论。 ElasticSearch的最大碎片大小是多少
-
SpringDoc/在nginx代理后大摇大摆
我们在代理后运行服务,以便: 被路由到公共地址 或者从另一个角度定义: 当nginx在上接收到请求时,它会去掉前缀,并将请求传递给路径上的service。 在设置任何东西之前(使用默认的SpringDoc配置),我可以正确地看到超文本传输协议上的昂首阔步的文档://service-post: 8080/swagger-ui.html。 设置主机上公共地址的路径。com,我正在使用: 然而,这似乎完
-
Java JVM最大可保留堆大小
有很多关于堆大小的帖子和站点,但是没有一个提到在调用JVM时如何找出我可以保留的最大可能堆大小。 任务是用最大可用堆大小xmx=max动态启动我的jvm(这里不需要讨论这个任务的对象!)。 我们可以考虑读取当前可用或空闲的内存,并将该大小用于xms和XMX。但这不起作用。 调用Java程序时: Java-XMS1536M-XMX1536M myApp 导致: 选择您选中的应用程序大约需要的堆。并在
-
Spark分区大小大于executor内存
我有四个问题。假设在spark中有3个worker节点。每个工人节点有3个执行器,每个执行器有3个核心。每个执行器有5 gb内存。(总共6个执行器,27个内核,15GB内存)。如果: > 我有30个数据分区。每个分区的大小为6 GB。最佳情况下,分区的数量必须等于核心的数量,因为每个核心执行一个分区/任务(每个分区执行一个任务)。在这种情况下,由于分区大小大于可用的执行器内存,每个执行器核心将如何
-
 大华二面 大数据开发c++
大华二面 大数据开发c++1.hashmap底层数据结构 2.virtual的使用场景,虚函数表 3.设计模式 4.多线程同步的方法 5.三次握手 6.智能指针有哪些,如何设计一个share_ptr? 7. vector是如何实现的,和list相比有何优缺点? 8.想问我网络编程方面的,我说不熟悉,跳过了…… 9.c++ 源文件到可执行文件的过程 9.多线程适用于那些应用场景? 10.stl哪些容器是线程安全的 11.补充
-
如何根据手机屏幕大小增加位图图像大小?
我正在使用一个库从url获取图像并将其作为位图图像保存到缓存中。但是当我检索该图像时,它非常小。如何根据手机屏幕增加位图图像的高度和宽度?这是创建位图的类。
-
使用Bouncy Castle库会导致output.jar文件大小的大量增加
我只使用了库中的几个实际类,即: 提前道谢。
-
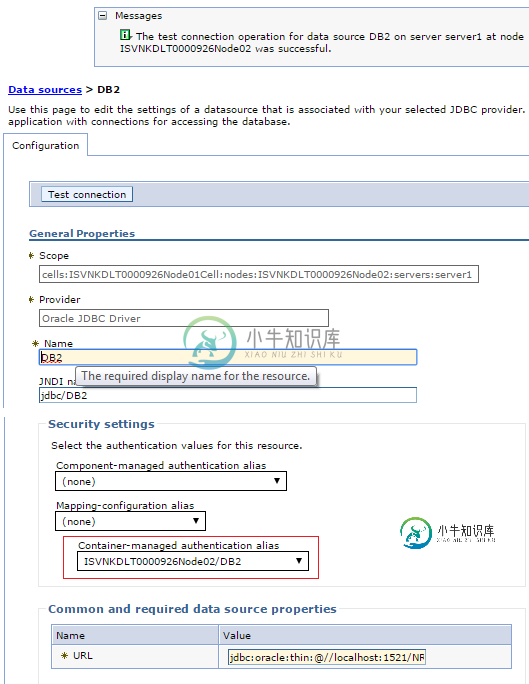 (OpenJPA/WAS)如何将容器托管身份验证用于容器托管实体管理器
(OpenJPA/WAS)如何将容器托管身份验证用于容器托管实体管理器了解如何配置WAS或OpenJPA,以便通过容器管理的实体管理器使用容器管理的身份验证。 试图通过在JNDI中注册为“JDBC/DB2”(指Oracle)的JDBC数据源访问Oracle数据库,该数据源在persistence.xml中定义。 persistence.xml 但是,当访问持久性单元的容器管理实体管理器时,会抛出ORA-01017无效的usrname/password。如果在pers
-
从另一个管道调用参数化的Jenkins管道
问题内容: 有任何方法可以从具有参数的另一个管道触发管道作业,我已经尝试过 也尝试过 和 没有运气,它说: 项目类型不支持参数 问题答案: 由于子作业是另一个多分支管道项目,因此我需要指定我要运行的分支 现在可以用了
-
.NET中托管和非托管代码之间的区别
本文向大家介绍.NET中托管和非托管代码之间的区别,包括了.NET中托管和非托管代码之间的区别的使用技巧和注意事项,需要的朋友参考一下 .NET Framework具有CLR(公共语言运行时),可以执行用.NET语言编写的代码。CLR管理内存需求,安全性,代码优化,特定于平台的转换等。在非托管代码的情况下,不存在CLR,并且代码由操作系统直接执行。 以下是托管代码和非托管代码之间的一些重要区别。
-
Jenkinsfile声明性管道-没有此类属性管道类
我已经在Jenkins上创建了一个基本的声明性管道。当我运行构建时,它会抛出以下错误 Jenkins服务器使用最新版本的默认插件设置为默认。Jenkinsfile如下所示 当Jenkins读取Jenkinsfile时,看起来块失败了,这在Jenkinsfile看起来很混乱。
-
在Google DataFlow上完成管道后运行函数/管道
我试图在Beam管道完成后,在Google DataFlow上运行一个函数(或管道)。 目前,我已经构建了一个hack来运行该函数,方法是使用 ... func在哪里: 但是有更好的方法吗?