《矢量图》专题
-
Dockerfile覆盖ENV变量
问题内容: 我有一个Dockerfile,我想使用默认值来配置API。 来自socialengine / nginx-spa ENV API_URL本地主机:6007 因此,当我运行此映像时,我将能够使用以下内容覆盖localhost:6007: 码头工人运行-e API_URL = production.com:6007 ui 这是行不通的,我找不到如何执行此操作的清晰说明。 有什么建议吗? 问
-
C++ 向量迭代器
本文向大家介绍C++ 向量迭代器,包括了C++ 向量迭代器的使用技巧和注意事项,需要的朋友参考一下 示例 begin将an返回iterator到序列容器中的第一个元素。 end返回iterator末尾的第一个元素。 如果矢量对象const,无论是begin和end返回const_iterator。如果const_iterator即使向量不返回,也要返回const,则可以使用cbegin和cend。
-
Java ADT调用变量
我是Java新手,我正在尝试创建一个ADT。我的ADT涉及通过输入分子和分母来创建和处理分数。我希望我的方法之一是将两个分数相加,并根据两个和的gcd返回一个简化的分数。我遇到的问题是实例化两个分数的组成部分(分子和分母)。该方法应该取一个分数其他,表示为。我分配的第一个变量是 但这似乎不起作用。以下是迄今为止的方法:
-
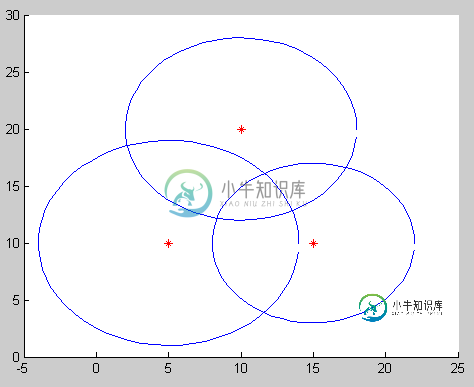 三边测量问题
三边测量问题如我所知,三次分割是寻找三个球体交汇区域中心的过程。我在c中写了三边测量法,我取了方程式,它是维基百科中三边测量中心和二维三边测量的细节 举一个如下的例子: 例1:p1(5,10),p2(15,10),p3(10,20),r1=9,r2=7,r3=8,答案是(11.6,13.8),这是逻辑答案。 但当像下面的例子一样的情况下,答案就像一个垃圾数字,我从计算中确定,但在这种情况下,我不知道原因! E
-
接口中的变量
问题内容: 为什么在接口中使用的变量是PUBLIC STATIC FINAL?为什么特别是“静态”? 问题答案: 无论如何,在接口中声明的字段只能是常量,那么为什么它取决于您使用哪个实例来访问它? 无论如何,将字段放在接口中通常都是不好的样式。该接口旨在反映实现该接口的类的功能-这与常量的概念完全正交。使用接口 只是 声明一堆常量肯定是一个讨厌的主意。我偶尔会发现使接口类型公开简单的实现很有用,例
-
详解JavaScript的变量
本文向大家介绍详解JavaScript的变量,包括了详解JavaScript的变量的使用技巧和注意事项,需要的朋友参考一下 基本类型和引用类型的值 ECMAScript变量一般有两种数据类型的值:基本类型和引用类型。 基本类型: 简单的数据段:Undefined, Null, Boolean, Number, String 引用类型:多个值构成的对象; 1.动态的属性 定义两者的值:创建一个变量并
-
批量插入问题
问题内容: 我正在尝试将数据从此链接插入到我的SQL Server https://www.ian.com/affiliatecenter/include/V2/CityCoordinatesList.zip 我创建了表 我正在运行以下脚本来进行批量插入 但是批量插入失败,并出现以下错误 当我使用google时,我发现了几篇文章,指出问题可能出在RowTerminator上,但我尝试了诸如/ n
-
apache代理tcp流量
我有个奇怪的问题。 我有http流量进入端口80,由我的vhosts文件管理,代理到内部web服务器,但我也有tcp非http流量进入端口80,需要代理到端口80上的另一个内部服务器。 我已经尝试了mod重写规则来尝试隔离非http通信的源ip地址,并创建一个规则来代理它到我的其他内部主机,但这也不起作用。 我将windows与apache一起使用,如果可能的话,我更愿意使用apache来实现这一
-
无变量scala编程
val和var在scala中,我认为这个概念是可以理解的。 我想做这样的事情(类似java): 这样我就可以更改姓名、地址等。。。 这工作得很好,但问题是,在我的程序中,我最终将所有内容都作为变量。据我所知,val在scala中是“首选”。val如何在这种类型的示例中工作,而不必在每次更改其中一个参数时重写所有30个参数? 也就是说,我可以 这是“正常”scala的做事方式吗(不受22个参数限制)
-
SQLAlchemy批量upsert[副本]
使用大型数据集进行批量更新的最佳方法是什么?我知道PostgreSQL现在支持upserts,但我不确定如何在SQLAlchemy中做到这一点。
-
保留NSLayoutConstraints的常量
在NSLayoutConstraint之前的时间里,这是可能的,因为保留了NSWindow的大小和状态—正在寻找一种优雅的方法来实现这一点 有没有办法在应用程序退出时保存,并在启动时再次恢复它们?
-
Dockerfile中的Env变量
我正在尝试dockerize一个基本的nodejs应用程序。我的dockerfile如下 但我总是收到同样的错误 我该怎么解决?
-
批量插入支持
我尝试使用r2dbc执行批处理插入。 我已经看到,使用spring boot中的DatabaseClient,这还不可能实现。我尝试使用R2DBC SPI语句和and方法来实现这一点,如下所示: 我在日志上看到完成了两个插入请求。 添加是执行批更新还是只运行两个请求? 谢谢
-
PHP批量插入foreach
我有一个从远程源读取数据的curl脚本。以下是当前代码: 然而,脚本的工作是非常缓慢的插入,因为我想象它的写作每一个单独的记录。计数变量是每页返回多少条记录,页面变量是一个简单的页面计数器。 我想知道是否有一种方法可以执行批量插入语句,一次插入所有100条记录。 提前谢谢。
-
测量计算时间