《收钱吧》专题
-
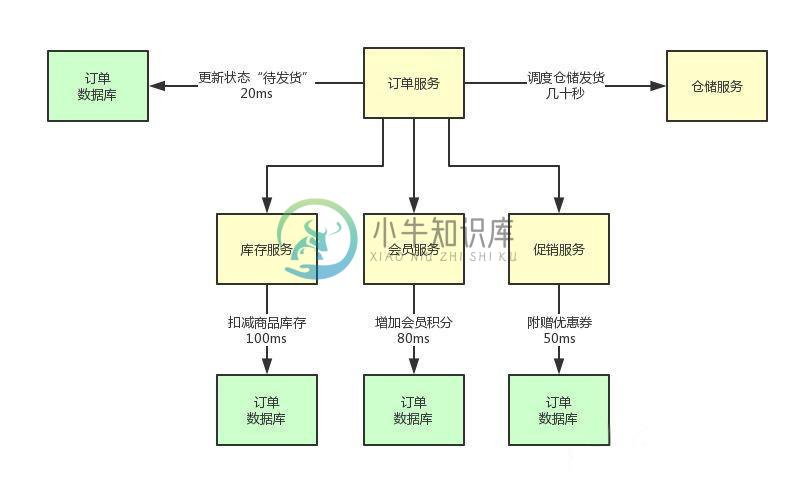 RabbitMQ是如何收发消息的?
RabbitMQ是如何收发消息的?主要内容:一、前情回顾,二、业务场景介绍,三、初步落地一、前情回顾 之前给大家聊了一下,面试时如果遇到消息中间件这个话题,面试官上来可能问的两个问题: 你们的系统架构中为什么要引入消息中间件? 系统架构中引入消息中间件有什么缺点? 关于这两个问题的回答,可以参见之前的两篇文章: 《 为什么要使用MQ消息中间件?这几个问题必须拿下!》 《 用了MQ消息中间件后,我开始后悔了...》 在问完这两个问题之后,不同风格的面试官可能会展开不同的发问。 针对那种
-
甲有一些桌子,乙有一些椅子,如果乙用全部的椅子来换回同样数量的桌子,那么要补给甲320元,如果不补钱,就会少换回5张桌子,已知3张椅子比桌子的价钱少48元。求一张桌子和一把椅子一共用多少钱?
本文向大家介绍甲有一些桌子,乙有一些椅子,如果乙用全部的椅子来换回同样数量的桌子,那么要补给甲320元,如果不补钱,就会少换回5张桌子,已知3张椅子比桌子的价钱少48元。求一张桌子和一把椅子一共用多少钱?相关面试题,主要包含被问及甲有一些桌子,乙有一些椅子,如果乙用全部的椅子来换回同样数量的桌子,那么要补给甲320元,如果不补钱,就会少换回5张桌子,已知3张椅子比桌子的价钱少48元。求一张桌子和一
-
可终结对象如何被回收至少需要2个垃圾回收周期?
问题内容: 我读的这个文章,我真的不能明白 的终结对象(其覆盖的对象是如何法)至少需要2 GC周期可以被回收之前。 在可以回收可终结对象之前,至少需要两个垃圾回收周期(最好)。 有人还能详细解释 一个可终结对象如何花费多个GC周期进行回收吗? 我的逻辑观点是,当我们覆盖finalize方法时,运行时将不得不向垃圾收集器注册此对象(以便GC可以调用此对象,这使我认为GC将引用所有finalize对象
-
如何在服务器端接收JSON我是以字符串的形式接收的
我在android做一个项目,从客户端我需要以json的形式发送数据,这是完美的工作,在服务器端是使用j2ee,在那里以字符串的形式接收结果,我如何得到作为json的结果,或者如何在服务器端将它转换成json存储在DB,谢谢!!
-
平时会对哪些内容进行付费?为什么愿意花钱去看/听这些内容?
本文向大家介绍平时会对哪些内容进行付费?为什么愿意花钱去看/听这些内容?相关面试题,主要包含被问及平时会对哪些内容进行付费?为什么愿意花钱去看/听这些内容?时的应答技巧和注意事项,需要的朋友参考一下 1.电子书 拓宽知识面。学得越多才能知道自己有多无知。博览群书不仅仅是增加阅历,更是在长期工作压力下的一种放松和怡然自得。 2.商业等各领域常识 知晓各种“不为人知”的常识,才能把生活过得更有质量。让
-
A和B赌100块钱,用抛硬币定胜负,7局4胜制,目前已经进行5局没有人胜出,但赌局由于特殊原因被迫中断,钱该怎么分?请说明分析过程。
本文向大家介绍A和B赌100块钱,用抛硬币定胜负,7局4胜制,目前已经进行5局没有人胜出,但赌局由于特殊原因被迫中断,钱该怎么分?请说明分析过程。相关面试题,主要包含被问及A和B赌100块钱,用抛硬币定胜负,7局4胜制,目前已经进行5局没有人胜出,但赌局由于特殊原因被迫中断,钱该怎么分?请说明分析过程。时的应答技巧和注意事项,需要的朋友参考一下 因为现在没有人胜出,所以要么是A胜3局要么是B胜3局
-
Java 8:方法参考绑定接收器和非绑定接收器之间的区别
问题内容: 我正在尝试在代码中使用Java 8方法引用。有四种类型的方法引用可用。 静态方法参考。 实例方法(绑定接收器)。 实例方法(UnBound接收器)。 构造函数参考。 随着和我有没有问题,但和真搞糊涂了。在接收器中,我们使用对象引用变量来调用如下方法: 在接收器中,我们使用类名来调用如下方法: 我有以下问题: 实例方法对不同类型的方法引用有何需求? 和接收方方法引用之间有什么区别? 在哪
-
水平回收器视图内部垂直回收器视图的自定义适配器
我有一个父回收器视图,其中包含一个水平回收器视图作为其项目。在其中,我将显示分类视频。当我开始滚动水平回收器视图时,应用程序崩溃。 错误是: 我的代码是category类 垂直适配器 水平适配器
-
纱线在收缩作业失败时将收缩作业报告为完成和成功
我在Thread上运行flink作业,我们使用命令行中的“fink run”将作业提交给Thread,有一天我们在flink作业上出现异常,因为我们没有启用flink重启策略,所以它只是失败了,但最终我们从Thread应用程序列表中发现作业状态为“成功”,我们预期为“失败”。 Flink CLI日志: Flink作业管理器日志: 有谁能帮我理解为什么塞恩说我的Flink工作是“成功的”?
-
是否可以识别该对象是由垃圾收集器或不在java中收集?
我已经读到,在以下情况下,对象可以进行垃圾收集。 该对象的所有引用都显式设置为null 但是,是否有无论如何要标识的对象是合格的垃圾回收机制是由垃圾收集器收集?
-
需要帮助来理解可用的JVM“垃圾收集算法”和“垃圾收集器”
为了理解可用的JVM垃圾收集算法,我在查看java-available垃圾收集算法链接时感到困惑。 根据我的理解,将会有一些标准的GC算法,不同的JVM供应商实现这些算法来创建垃圾收集器。 现在请帮助我理解下面是算法还是算法的实现: 序列, 平行, CMS, G1, 我认为这些是实现某些特定算法的垃圾收集器类型(我不知道算法的名称)。 此外,我还浏览了在http://www.oracle.com/
-
如何在.NET中的套接字编程(TCP/IP)中收集接收到的缓冲区?
我使用服务器-客户机模型与使用套接字编程的硬件板进行通信。 我使用“NetworkStream”类的“read()”方法从板上接收数据,该方法读取指定最大大小的缓冲区,并返回缓冲区中有效数据的长度。我已经考虑了一个足够大的数字缓冲区的最大大小。 该板每100ms发送一组消息。每条消息包含一个2字节的常量报头和一个作为报头字节之后的数据的可变字节数。
-
用Twilio发送和接收短信,开始发送者和接收者之间的对话
-
Kafka使用者在接收字节/数据之前是否首先接收偏移列表?
我对阿帕奇·Kafka很陌生,目前正在读《学习阿帕奇·Kafka》,第2版(2015年)。第3章,段落Kafka设计基础说: 使用者总是按顺序使用来自特定分区的消息,并确认消息偏移量。这个确认意味着使用者已经使用了所有先前的消息。使用者向代理发出包含要消费的消息的偏移量的异步拉请求,并获得字节的缓冲区。 我有点被‘承认’这个词搞糊涂了。我是否正确理解为Kafka首先发送偏移量,然后消费者使用偏移量
-
如何使可完成的未来在完成后通过垃圾回收进行回收?
我基于java的CompletableFuture构建了一个任务链,它可能非常长。我的问题是CompletableFuture中的每一个任务都是一个内部类,它包含对源CompletableFuture的引用,因此不可能对已完成的CompletableForture进行垃圾收集。有没有办法避免内存泄漏? 这是一段可用于重现此错误的代码: