《新浪集团》专题
-
 浪潮java日常实习面经 20min
浪潮java日常实习面经 20min浪潮java日常实习面经 20min 拷打项目,是否有中间件(估计他想问中间件) 开始经典八股: 面向对象特征,分别详细介绍一下 java基本数据类型 封装类的特征 String中的equal和=的区别 用过什么设计模式(答少了几个),用在什么场景(忘了)😭 mysql 索引用的什么详细讲一下 反问:什么部门,什么业务,下次面试什么时候(貌似没面了) 一小时后电话oc了
-
 08.22 浪潮提前批一面面经
08.22 浪潮提前批一面面经一面是HR面,大概就只用了10分钟 自我介绍 问实习和项目(项目是在实习公司做的吗?实习多久?介绍一个项目,你用了什么方法主要解决了什么问题?) 本科是软件工程 研究生是电子信息 是不是因为实习做的算法就想投算法岗? 熟悉哪些算法 因为回答主要熟悉深度学习和图像处理相关,问熟悉哪些框架 老家和对工作地点的要求 考研还是保研 本科和研究生基点 现在投了哪些公司 哪些在推进 反问: 总共有几面?两面,
-
进一步探索分类 - 新的数据集,新的挑战
是时候使用新的数据集了——比马印第安人糖尿病数据集,由美国国家糖尿病、消化和肾脏疾病研究所提供。 令人惊讶的是,超过30%的比马人患有糖尿病,而全美的糖尿病患者比例是8.3%,中国只有4.2%。 数据集中的一条记录代表一名21岁以上的比马女性,她们分类两类:五年内查出患有糖尿病,以及没有得病。 共选取了8个特征: 怀孕次数; 口服葡萄糖耐量实验两小时后的血浆葡萄糖浓度; 舒张压(mm Hg); 三
-
当开发人员将新请求更新到api时,如何更新Postman集合
例如: 在一个例子中,我有一个API和65个请求,我从Swagger UI导入这些请求并编写测试用例。然后几天后,我使用相同的链接导入,请求的数量变成了69个,这意味着增加了4个新请求,但Postman用测试用例替换了整个集合。
-
如何将新的源集添加到Gradle?
问题内容: 我想在我的Gradle版本(版本1.0)中添加集成测试。它们应与我的常规测试分开运行,因为它们需要将webapp部署到本地主机(它们测试该webapp)。这些测试应该能够使用在我的主要源代码集中定义的类。我如何做到这一点? 问题答案: 这花了我一段时间才能弄清楚,在线资源也不是很好。所以我想记录我的解决方案。 这是一个简单的gradle构建脚本,除了主要和测试源集之外,还具有intTe
-
查找结果集中的最新日期
问题内容: 我正在处理一个查询,其中需要查看患者去诊所时输入的患者生命体征(特别是血压)。我将获得2015年全年的结果,当然,某些患者曾多次就诊,我只需要查看最近一次就诊时输入的生命指标即可。另一个轻微的变化是收缩压和舒张压是分别输入的,因此我得到如下结果: 有26,000多个结果,因此显然我不想遍历每位患者并查看他们的最新结果是什么时候。我希望我的结果看起来像这样: 我知道出生的名字和日期,以后
-
LiquiBase:为新数据库添加变更集
我有一个使用Liquibase for PostgreSQL定义的现有模式。我正在添加对Oracle的支持,这需要进行重大更改。有些create-table标记只需更改数据类型即可工作,有些则不然(需要sql更改)。当前的changelog-schema文件在单个change-set下有多个create-table语句(我知道这不是一个好的设计,但这正是我现在要处理的),为了重用那些create-
-
Mapsforge不从域重新绘制集群POI
我使用Realm从DB加载POI。接下来,通过mapsforge将这些点添加到集群实现中。此代码运行良好: 它在地图上绘制所有POI,但若我在领域集群中使用RxJava,就永远不会在地图上添加POI。代码如下:
-
如何选举集群中的新硕士?
问题内容: 我正在编写一个托管云堆栈(在诸如EC2之类的硬件级云提供程序之上),我不久将面临的一个问题是: 几个相同的节点如何确定其中一个成为主节点?(即,考虑在EC2上运行的5台服务器。其中一台必须成为主服务器,而其他服务器必须成为从服务器。) 我阅读了MongoDB使用的算法的说明,它看起来非常复杂,并且还取决于投票的概念—即,两个单独的节点将无法决定任何事情。同样,他们的方法在产生结果之前有
-
新的Elasticsearch-Ruby宝石与导轨集成
问题内容: 有任何方法可以将用于Ruby的新Elasticsearch宝石集成到轨道中,轮胎很棒,但两个月以来就已淘汰,并由新宝石替代,但是还没有与轨道的集成功能。 所有教程都使用累了,但是现在,我们如何在Elasticsearch中使用rails? 问题答案: 还有另一个名为“ searchkick”的宝石,它将elasticsearch与Rails集成在一起: https://github.c
-
SQLServerException:生成了要更新的结果集
问题内容: 我正在尝试将新记录插入MS SQL数据库,并且遇到了从未见过的异常。当我打电话时,抛出以下异常: 这是产生错误的Java代码: 其中ADD_COMMENT定义为字符串: 为了更全面,该表定义为: 我认为我在这里没有做任何非常复杂的事情,但我无法想到为什么会遇到这种例外情况。我在同一个类中有一个方法,该方法执行完全相同的插入类型(实际上是具有不同表名和值数量的相同查询),并且没有问题
-
按id集更新多个文档。猫鼬
我想知道mongoose是否有一些方法可以通过id集更新多个文档。例如: 我想知道的是,如果猫鼬能做这样的事情: 其中,ids是一个id数组,如['id1','id2','id3']-示例数组。对于find,同样的问题。
-
定义Ivy中“最新集成”的行为
我很难理解latest.integration是如何工作的。 我有一个例子,没有给出输出中提到:http://ant.apache.org/ivy/history/latest-milestone/tutorial/defaultconf.html 也就是说,无论发布时间如何,本地解析器都优先于其他解析器。 我的常春藤.xml是这样的: 这里我声明我有一个nexus url存储库和一个对默认本地的
-
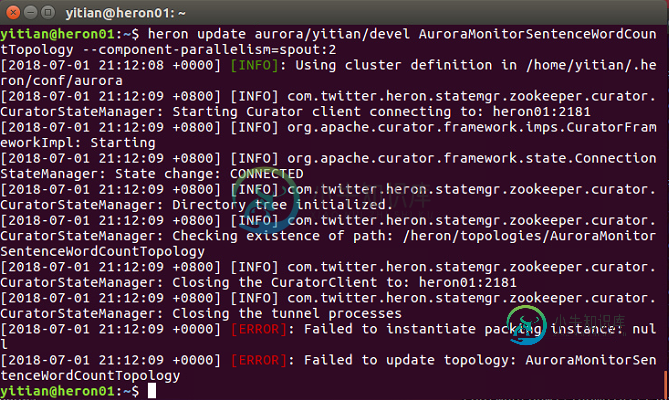 在Heron集群中更新拓扑失败
在Heron集群中更新拓扑失败这个拓扑运行正常,不知道是什么原因导致这个问题。
-
10.8. 新字符集配置文件格式
字符集配置存储在XML文件中,一个字符集对应一个文件。