《特斯拉》专题
-
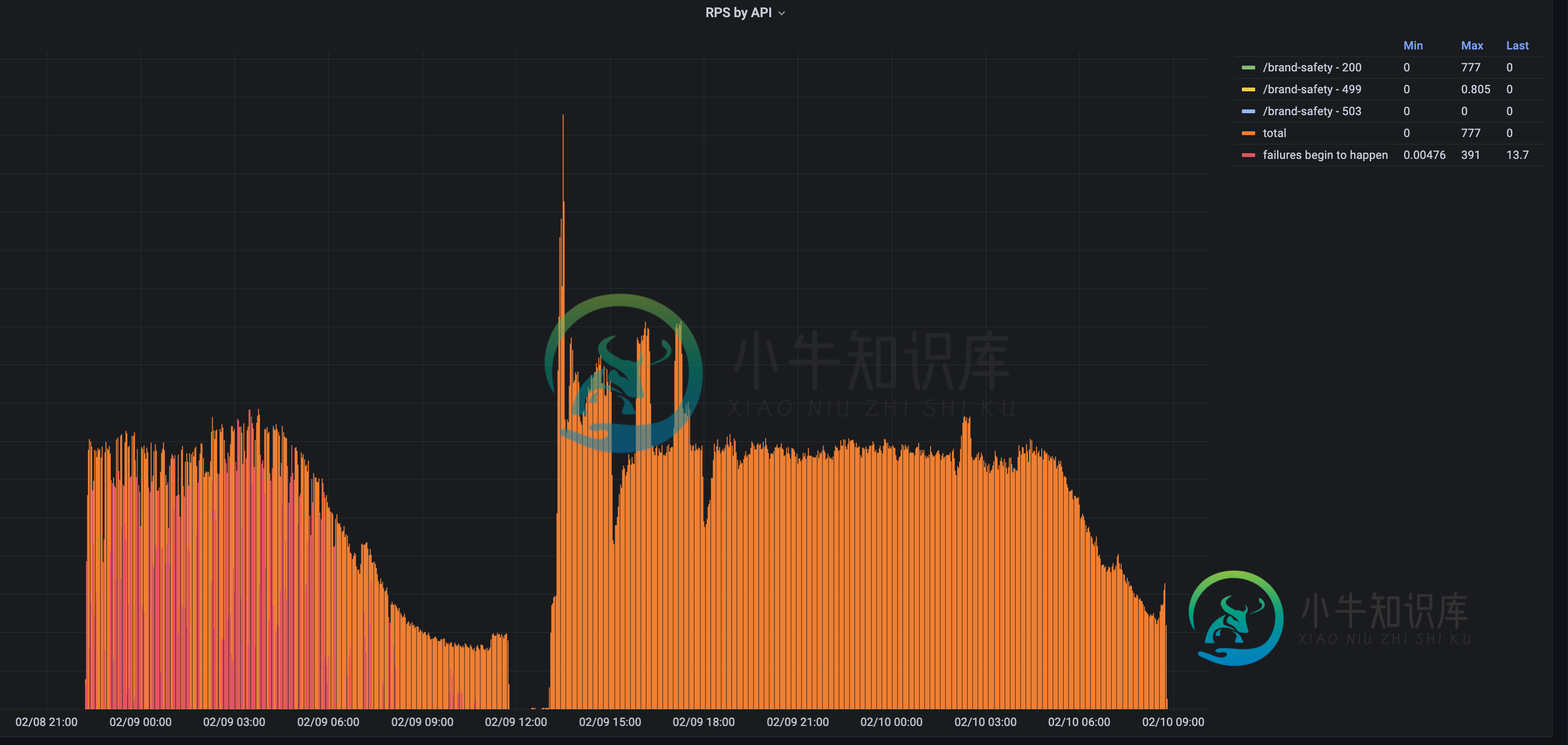 普罗米修斯:找到最大RPS
普罗米修斯:找到最大RPS假设我在普罗米修斯中有两个指标,两个计数器: 好的: 失败: 总计: 我的问题是如何找到在查询中发生的failures 我期待以下回应: 这意味着,如果 pod 接收
-
给詹金斯增加一个奴隶
我想在詹金斯增加一个奴隶。我遵循了https://wiki.jenkins-ci.org/display/jenkins/step+by+step+guide+to+set+up+master+和+slave+machines中的步骤。 有什么想法可能会出问题吗? 我检查过了,我确实有连接权限。
-
从主机重启詹金斯从机
我们怎样才能完成它? 注意:使用jenkins-slave作为服务不是一个选项,因为我们有其他安全访问问题。
-
普罗米修斯或使用rate时()
摘要 由于导入的Grafana仪表板无法工作,我正在尝试找出如何在Prometheus查询中正确使用或运算符。
-
使用詹金斯与黑鸭枢纽
我安装了Jenkins,下载了Black Duck Hub插件(V4.0.1)。 我遵循了接下来的步骤。去找詹金斯- 我该怎么办?
-
在赛贝斯ASE表中删除列
如何在Sybase ASE 15表格设置中删除列。 我尝试了一些,但没有用: 以及查看Sybase文档,它没有为我的问题提供解决方案。 数据库my_db未启用选择进入数据库选项。无法执行带有数据副本的ALTER TABLE。设置选择进入数据库选项并重新运行。
-
获取赛贝斯ASE硬件信息
我四处搜索,找到了一些有用的程序,例如: 但没人能帮我。我需要获得有关CPU、RAM、OS等的信息。有什么工具或程序可以帮助我吗?
-
赛贝斯BIT数据类型过滤
我们将Sybase ASE用于从头开发的应用程序。我们有一些表有位列。在Sybase中,位数据类型不能为null。对于我们存储在表中的记录来说,这很好,但是我们的搜索存储过程存在设计问题。我们的存储过程和相应的数据访问层类(在.NET中使用Dapper)严重依赖代码生成器。由于我们无法将位参数的NULL传递给搜索存储过程,因此我们只能检索位列中具有1或0值的记录。下面的例子: 这里有一些变通方法,
-
韦斯帕:如何为 centos7 配置VESPA_HOME?
质子文件表明http://docs.vespa.ai/documentation/proton.html所有数据将存储在$VESPA_HOME/var/db/VESPA/search/ 当我们安装yum的vespa时 它将环境变量VESPA_HOME设置为“/opt/VESPA” 我们如何阻止数据进入/opt/vespa?我们需要将VESPA_HOME设置为“/mnt1/vespa” 尝试,手动设
-
詹金斯中的硒失效测试
我试图在Jenkins中运行硒。当我在本地运行它时,测试总是通过。但是在Jenkins我总是出错: 没有这样的元素: 找不到 元素: 我使用詹金斯,硒和测试
-
斯坦纳树Steiner Tree实例讲解
说到斯坦纳树问题,它是一种组合优化问题,与最小生成树相似,是最短网络的一种。最小生成树是在给定的点集和边中寻求最短网络使所有点连通。而最小斯坦纳树允许在给定点外增加额外的点,使生成的最短网络开销最小。 一、斯坦纳树 斯坦纳树问题是组合优化问题,与最小生成树相似,是最短网络的一种,其实最小生成树是最小斯坦纳树的一种特殊情况,最小生成树是在给定的点集和边中寻求最短网络使所有点连通,而最小斯坦纳树允许在
-
朴素贝叶斯 - 使用Python实现
训练阶段 朴素贝叶斯需要用到先验概率和条件概率。让我们回顾一下民主党和共和党的例子:先验概率指的是我们已经掌握的概率,比如美国议会中有233名共和党人,200名民主党人,那共和党人出现的概率就是: P(共和党) = 233 / 433 = 0.54 我们用P(h)来表示先验概率。而条件概率P(h|D)则表示在已知D的情况下,事件h出现的概率。比如说P(民主党|法案1=yes)。朴素贝叶斯公式中,我
-
朴素贝叶斯 - 数值型数据
你可能已经注意到,在讨论近邻算法时,我们使用的都是数值型的数据,而在学习朴素贝叶斯算法时,用的是分类型的数据。 比如,人们对法案的投票有赞成和否决两类;音乐家可以用他们演奏的乐器来分类等等。这些分类之间是没有距离的,萨克斯手和钢琴家的距离并不会比鼓手近。而数值型数据则有这种远近之分。 在贝叶斯方法中,我们会对事物进行计数,这种计数则是可以度量的。对于数值型的数据要如何计数呢?通常有两种做法: 方法
-
朴素贝叶斯 - 微软购物车
你听说过微软的智能购物车吗?没错,他们真有这样的产品。这个产品是微软和一个名为Chaotic Moon的公司合作开发的。 这家公司的标语是“我们比你聪明,我们比你有创造力。”你可以会觉得这样的标语有些狂妄自大,这里暂且不谈。 这种购物车由以下几个部分组成:Windows 8平板电脑、Kinect体感设备、蓝牙耳机(购物车可以和你说话)、以及电动装置(购物车可以跟着你走)。 你走进一家超市,持有一张
-
支持向量机高斯核调参
在支持向量机(以下简称SVM)的核函数中,高斯核(以下简称RBF)是最常用的,从理论上讲, RBF一定不比线性核函数差,但是在实际应用中,却面临着几个重要的超参数的调优问题。如果调的不好,可能比线性核函数还要差。所以我们实际应用中,能用线性核函数得到较好效果的都会选择线性核函数。如果线性核不好,我们就需要使用RBF,在享受RBF对非线性数据的良好分类效果前,我们需要对主要的超参数进行选取。