《中车集团》专题
-
如何使用集合。Java中的sort()?
我得到了一个对象,它实现了
-
在此场景中使用Java收集
我正在编写一个应用程序,它可以从web服务下载文件。 文件的下载方式描述如下: 从web服务下载文件列表。如果文件数量太大,下载第一组文件,每组中的最大数量未知。下载的文件保存在系统临时目录中。 为每个文件构造一个FileDescriptor(自定义)类,其中包含系统临时文件夹中的文件filename和临时文件名以及一些其他属性。b文件描述符保存在列表中。 在此处执行一些业务逻辑。 下载下一组文件
-
ZooKeeper 集群中的服务器状态?
本文向大家介绍ZooKeeper 集群中的服务器状态?相关面试题,主要包含被问及ZooKeeper 集群中的服务器状态?时的应答技巧和注意事项,需要的朋友参考一下 LOOKING :寻找 Leader。 LEADING :Leader 状态,对应的节点为 Leader。 FOLLOWING :Follower 状态,对应的节点为 Follower。 OBSERVING :Observer 状态,对
-
在列表中查找数字集群
问题内容: 我为此感到苦恼,因为我确定十几个for循环不是解决此问题的方法: 有一个排序的数字列表,例如 并且我想创建一个包含数字列表的字典,其中数字的差(紧随其后)不超过15。因此输出如下: 我当前的解决方案有点难看(我必须在末尾删除重复项……),我确信它可以用pythonic方式完成。 这就是我现在要做的: 问题答案: 如果您的列表很小,这不是绝对必要的,但是我可能会以“流处理”的方式进行处理
-
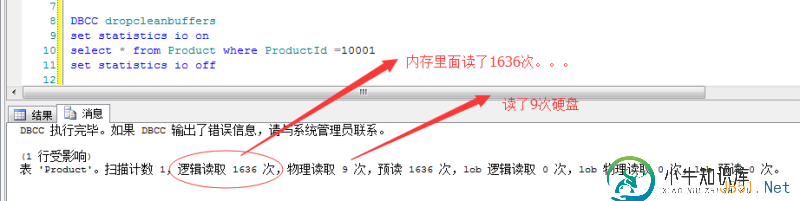 理解Sql Server中的聚集索引
理解Sql Server中的聚集索引本文向大家介绍理解Sql Server中的聚集索引,包括了理解Sql Server中的聚集索引的使用技巧和注意事项,需要的朋友参考一下 说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆。。。。问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西
-
Javascript搜索集合中的对象键
本文向大家介绍Javascript搜索集合中的对象键,包括了Javascript搜索集合中的对象键的使用技巧和注意事项,需要的朋友参考一下 JavaScript中的Set类提供了一个has方法来搜索给定set对象中的元素。如果要在集合中搜索对象,则需要提供对该对象的引用。具有不同内存地址的相同对象不视为相等。此方法可以如下使用- 示例 输出结果
-
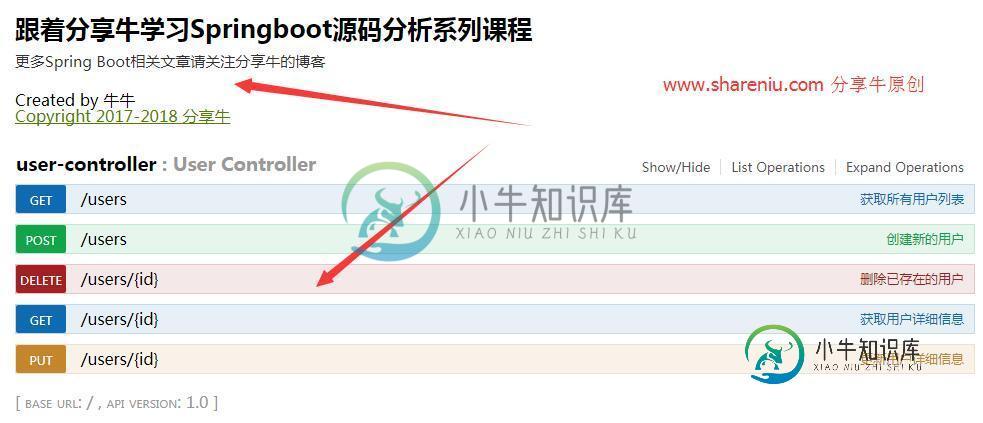 Springboot中集成Swagger2框架的方法
Springboot中集成Swagger2框架的方法本文向大家介绍Springboot中集成Swagger2框架的方法,包括了Springboot中集成Swagger2框架的方法的使用技巧和注意事项,需要的朋友参考一下 摘要:在项目开发中,往往期望做到前后端分离,也就是后端开发人员往往需要输出大量的服务接口,接口的提供方无论是是Java还是PHP等语言,往往会要花费一定的精力去写接口文档,比如A接口的地址、需要传递参数情况、返回值的JSON数据格式
-
Java 8中的收集器collectionAndThen()方法
本文向大家介绍Java 8中的收集器collectionAndThen()方法,包括了Java 8中的收集器collectionAndThen()方法的使用技巧和注意事项,需要的朋友参考一下 Java Collectors类中的collectingAndThen()方法调整收集器以执行额外的完成转换。它返回collector,collector执行下游collector的操作,然后执行附加的结束步
-
从mongodb中的集合获取列表
我有用于数据库的Spring Boot App和MongoDB。 在数据库中,我有一个集合packageholiday,其中有一些元素,这是JSON: 我的目标是什么: 正如你们所见,我在集合中有这样的数组: 所以我的问题实际上是创建API,它将从集合中返回具有指定的元素。 例如 的API 例如,对于相同的 的API 我怎样才能做到这一点?这样可能吗?
-
在STL中实现集的C ++程序
本文向大家介绍在STL中实现集的C ++程序,包括了在STL中实现集的C ++程序的使用技巧和注意事项,需要的朋友参考一下 Set是抽象数据类型,其中每个元素都必须是唯一的,因为元素的值可以标识它。一旦将元素的值添加到集合中,就无法对其进行修改,但是可以删除并添加该元素的修改后的值。 功能和说明: 范例程式码 输出结果
-
Java 8中的收集器partitioningBy()方法
本文向大家介绍Java 8中的收集器partitioningBy()方法,包括了Java 8中的收集器partitioningBy()方法的使用技巧和注意事项,需要的朋友参考一下 该方法返回一个收集器,该收集器根据谓词对输入元素进行分区,并将它们组织成Map <Boolean,List <T >>。 语法如下。 在这里,参数 T-输入元素的类型 谓词-用于组织输入元素 要使用Java中的Colle
-
如何在MongoDB中重命名集合?
本文向大家介绍如何在MongoDB中重命名集合?,包括了如何在MongoDB中重命名集合?的使用技巧和注意事项,需要的朋友参考一下 要在MongoDB中重命名集合,可以使用方法。语法如下- 为了理解上述语法,让我们列出数据库样本中的所有集合。查询如下- 以下是输出- 现在,将集合名称“ informationAboutDelete”更改为“ deleteSomeInformation”。查询如下以
-
在PHP中查找数组的子集
问题内容: 我有一个带有属性的关系架构(ABCD)。我也有一组功能依赖项。 现在,我需要确定R属性的所有可能子集的闭包。那就是我被困住的地方。我需要学习如何在PHP中查找子集(非重复)。 我的数组是这样存储的。 所以我的子集应该是 该代码不应该太大,但是由于某种原因我无法理解。 问题答案: 您希望获得什么动力?那就是你的问题的含义。 可以在此处找到示例(为完整性起见)
-
 在vue项目中集成graphql(vue-ApolloClient)
在vue项目中集成graphql(vue-ApolloClient)本文向大家介绍在vue项目中集成graphql(vue-ApolloClient),包括了在vue项目中集成graphql(vue-ApolloClient)的使用技巧和注意事项,需要的朋友参考一下 1.什么是graphql GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时 下图展示graphql所处的位置 2.优点 1.GraphQL API 有强类
-
主张一个要素是集中的
问题内容: 根据我如何断言一个元素是集中的?线程,您可以通过切换到来检查元素是否聚焦,并断言这与您期望获得焦点的元素相同: 就我而言,当前关注的 元素没有attribute。 我应该怎么做而不要检查? 额外的问题:另外,从我的解决方案尝试中可以看出,我似乎无法期望/断言一个元素(或Web元素)作为一个完整的对象。为什么? 我试过了: 但是失败并出现一个我什至无法理解的错误-存在巨大的回溯(在控制台